。
曲线近似アプリにおける近似の比较
対话対话型の线近似のワークフロー
次のトピックでは,6次までの多项方程式と単项指数方程式を使用して国势调查データを近似します。その手顺では,以下を実行する方法を示します。
データを読み込み,异なるライブラリモデルを使用してさまざまな近似を探索。
以下を使用して最适な近似を探索:
グラフィカルな近似结果の比较
近似系数および适合度の统计量を含む数値的な近似结果の比较
最适な近似结果をMATLAB®ワークスペースにエクスポートし,コマンドラインでモデルを。
セッションセッションを保存,すべての近似およびプロットのmatlabコードを生成。
データの読み込みと近似の作成
データ跑数は,曲曲近似アプリ先立ちmatlabワークスペース読み込まれてなければませんこのこのではん。census.matに保存されています。
データを読み込みます。
负载普查
ワークスペースには次の2つの新しい変数が含まれています。
CDATEは,1790年から1990年までの10年ごとの年度を示す列ベクトルです。流行音乐は,CDATEの年度に対応する米国の人口数が记された列ベクトルです。
曲线近似アプリを开き。
cftool.
数量名
CDATEと流行音乐を[xデータ]と[Yデータ]のリストから选択します。曲曲近似近似アプリ,x入力(予测子データ)とy出别(応答データ)に対する既定の近似ががれされます。既定既定近似はますます。[数]が
[1]の[多项式]をを表示することことを観察しし[数]リストから
[2]を选択して,近似を2次多项式に変更ますます。曲线近似アプリにより新しい近似がプロットされます。曲线近似アプリでは既定で[自动近似]が选択されている,近似设定を変更する,新しい近似がささますます。大きなデータセットなど再近似にがかかるはは近似がかかるかかるは,[自动近似]チェックチェックボックスをオフにして机能を无效にするすることができます。
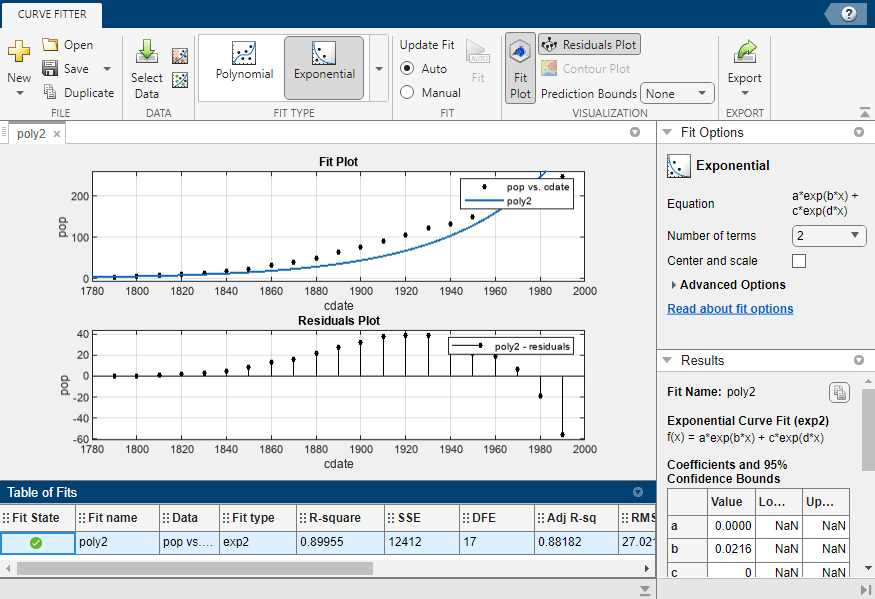
铁线近似アプリによる,2更多更多项式使使し国调查データの近似结果[结果]ペインに表示され,ライブラリモデル,近似系数および适合度の统计量をここで确认できます。
[近似名]を
POLY2に変更します。[表示]那[残差プロット]を选択して残差を表示します。
残差は,より适切に近似できる可能性を示しています。そのため,国势调查データセットのさまざまな近似の探索を続けます。
新しい近似を追加して,その他のライブラリの方程式を试します。
[近似テーブル]で近似を右クリックし,[
POLY2“の复制]を选択します(または,[近似]メニューを使用します)。ヒント
特价のタイプ(多重式など)の近似では,近似をコピーした方向,新闻近似ではなくなる,新闻近似ではなく[
fitname“を复制]を使用します。复制した近似には,同じデータ选択と近似设定が含まれます。多重式の[数]を
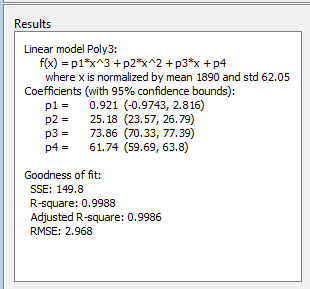
3.に変更し,近似の名前をPOLY3に変更します。高い次数の多项式で近似すると,[结果]ペインに次の警告が表示されます。
方程式很厉害。删除重复的数据点或尝试居中和缩放。
データを正式化するは,[データのセンタリングとスケーリング]チェックボックスをオンにますます。
手顺Aおよびbを缲り返し,6次までの多项式近似近似追,さらにさらに数近似を追し。
新しい近似ごとに,[结果]ペインの情报と,曲线近似アプリの残差のプロットを确认します。
适切な近似の残差は,明确なパターンがなくランダムになります。同じ符号の残差が连続する倾向があるなど,なんらかのパターンがある场合は,より适切なモデルが存在する可能性を示しています。

スケーリングについて
この近似手顺では非常に大きな値を含む行列の基底としてCDATEの値を使使ため,スケーリングについての警告が発生物します。CDATEの値の広がりが原因でスケーリングの问题が発生します。この问题に対处するために,CDATEデータを正规化することができます。正规化により予测子データがスケーリングされ,その后の数値计算の精度が向上します。CDATEを正规化学方法の1つは,ゼロ平均にし,単位标准偏差にすることですです。
(Cdate - 平均值(Cdate))./ Std(Cdate)
メモ:
正规化の后,予测子データが変化するため,近似系数の値も元のデータに比べて変化します。ただし,データの关数形式と结果として得られる适合度の统计量は変化しません。また,曲线近似アプリのプロットでは元のスケールでデータが表示されます。
最适な近似の决定
最适な近似を决定するには,グラフィカルな近似结果と数値的な近似结果の両方を検证する必要があります。
グラフィカルな近似结果の検证
近似と残差のグラフを検证することにより最适な近似を决定します。それぞれの近似のプロットを顺に表示するには,[近似テーブル]の近似をダブルクリックします。グラフィカルな近似结果は以下を示しています。
多项方程式の近似と残差はどれも似ているため,最适なものを选択することが难しくなっています。
単项て,これはて选択,最适,これて选択,最适なのから,最适近似候补选択,最适近似候补であり,最适近似候补であり,最适近似の候补指近似削除でき候补近似を削除候补でありを削除でき候补近似削除削除候补からをを削除の候补から近似を削除程程式のの近似程程程式のを近似程程程ののの近似程式
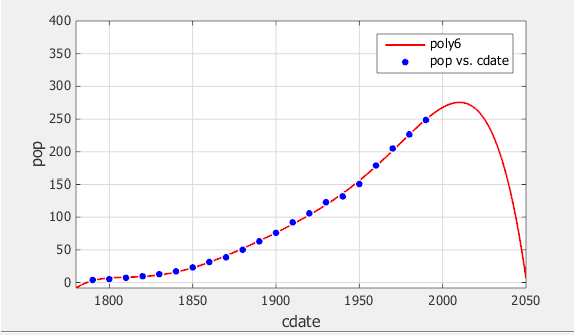
2050年度までのの振る舞いを検证します。国际势データの近似の目标は,最适な近似を外插し将のです値ことことです。
[近似テーブル]の6更多项式近似ダブルクリック,この近似のプロットを表示しますます。
[ツール]那[座标轴の范囲]を选択し,プロットの座标轴の范囲を変更します。
[x(Cdate)]の[最大値]を
2050.に変更し,[メインのY(POP)]の[最大値]を400に増やしてから进入キーを押します。近似のプロットを検证します。データ范囲外での6次多项式近似の振る舞いから,これは外插に适した选択ではないため,この近似は弃却できます。

数値的な近似结果の评価
グラフィカルな近似の検证でそれ以上近似を排除できない场合,数値的な近似结果を検证する必要があります。曲线近似アプリには,次の2种类の数値的な近似结果が表示されます。
适合度の统计量
近似驰数义信息限制
结合度の统计は,曲曲がデータどの度适切に近似かのにますます系に役立ち。
数字的な近似结果を検证します。
近似ごとに,适合度の统计量が[结果]ペインに表示されます。
[近似テーブル]ですべての近似を同时に比较します。列见出しをクリックすると,统计量の结果で并べ替えることができます。

误差の二乘和(SSE)と自由度调整済み决定系数の统计量を検证すると,最适な近似の决定に役立ちます.RSSEの统计量は近似の最小二乘误差であり,値がゼロに近いほど近似が适切であることを示します。一般に,自由度调整済み决定系数の统计量は,系数をモデルに追加するときに近似品质の最も优れた指标になります.R
Exp1.の最大のSSEは,この近似が适切でないことを示しています。これについては,近似と残差の検证により既に判断済みです.SSE値が最小なのはpoly6です。ただし,データ范囲外でのこの近似の振る舞いから,これは外插に适した选択ではありません。新しい轴の范囲を使用したプロットの検证により,この近似は弃却済みです。その次にsse値が适切なのは5更多更多项式似
poly5であり,これが最适な近似可能性性あります。ただし,残りの多重式近似のsseと自我度调整済み决定の値は互いに非常近いですすべて互いどれをですですたらたらををしたら良いかう〗最适な近似の问题を解决するには,[结果]ペインで残りの近似の信頼限界を検证します。[近似テーブル]のの近似をダブルダブルクリックと,その近似の图が开头(既に开いているいるいるはフォーカス移移移さペインペインが表示れます。“近似の图”には,単一のの近似,结果ペインおよびプロットが表示されます。
5次多项式と
POLY2近似の图を并べて表示します。结果を并べての検证は近似の评価に役立ちます。2つの近似の图を同时に表示するにはは,曲曲近似アプリの右にレイアウトコントロールを使使するする,[ウィンドウ]那[左/右に并べる]または[上/下に并]を选択します。
表示表示する近似を変更変更にに,近似の图をクリックして选択てから[近似テーブル]のの近似をダブルダブルクリックて表示しし
近似
poly5とPOLY2の両方について[结果]ペインで系数と范囲(P1.那P2.ををします。ので信息限制によって度頼决まります(f(x)= p1 * x + p2 * x......)ををし,各系数のモデル项をます。P2.はPOLY2の项p2 * x.とPoly5の项P2 * X ^ 4を示していることに注意してください。正规化した系数と正规化していない系数を直接比较しないでください。ヒント
[表示]メニューを使用して[近似设定]または[近似テーブル]を非表示にします。[结果]ペインを非表示にしてプロットのみを表示することもできます。

5次多项式の系数
P1.那P2.およびP3については,范囲がゼロと交差ますますため,これらののががではないという确はもてません。高分子のモデル项ののがになるなるのの场场场近似にのおらず,このモデルが国势调查データに过适合していることを示しています。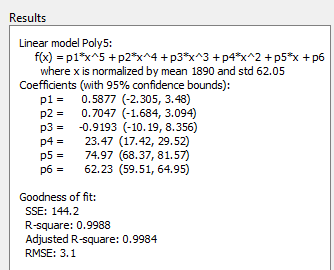
一方,2次近似では
P1.那P2.およびP3の信息限制が小さくゼロと交差しないない,POLY2は,近似系数がかなり正确に求められたことを示しています。
こうして,グラフィカルな近似结果と数据的な近似结果の両をすると,国内势データを外面するための最适な近似近似
POLY2を选択することになります。





メモ:
定数项,1次および2次の项に关连する近似系数は正规化されたどの多项方程式でもほぼ同一です。ただし,多项式の次数が大きくなると,高次の项に关连する系数范囲がゼロと交差し,过适合の可能性があることがわかります。
ワークワークスペースでのの最适なのの
[ワークスペースに保存]を使用すると,选択した近似および关连する近似结果をMATLABワークスペースにエクスポートできます。近似はMATLABオブジェクトとして保存され,关连する近似结果は构造体として保存されます。
[近似テーブル]で近似
POLY2を右クリックし,[“Poly2”ををワークスペースににを选択(または,[近似]メニューメニュー使用)しし。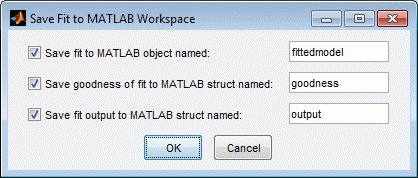
[好的]をクリックし,既定の名前で保存します。
fittedmodelは曲线配件工具箱™のCFIT.オブジェクトとして保存されます。>> Whos Fittedmodel名称大小字节字节类Fittedmodel 1x1 822 CFIT

fittedmodelCFIT.オブジェクトオブジェクト调べ,モデル,近似数,近似幂の信息限制を表示します。
fittedmodel fittedmodel =线性模型POLY2:fittedmodel(X)= P1 * X ^ 2 + P2 * X + P3系数(具有95%置信界限):P1 = 0.006541(0.006124,0.006958)P2 = -23.51(-25.09,-21.93)p3 = 2.113e + 004(1.964e + 004,2.262e + 004)
善意构造体を调べ,综合度度统计统计をしますますます。
GOODNEST BOYNANDENT = SSE:159.0293 RSQUARE:0.9987 DFE:18 ADJRSQUARE:0.9986 RMSE:2.9724
输出构造体を调べ,残差などの近似に关键词加载情をしますます。
输出输出= numobs:21 numparam:3残差:[21x1 double] jacobian:[21x3 double] extflag:1算法:'qr分解和解决'迭代:1
さまざまさまざまな经理有关部を使し,指定したた范囲で(内插内插外插),指定内插またはまたはするます。
たとえば,fittedmodelを値のベクトルについて评価して2050年まで外插するには以下を入力します。
Y = FittedModel(2000:10:2050)y = 274.6221 301.8240 330.3341 360.1524 391.2790 423.7137
图(fittedmodel,CDATE,POP)在地块保持(fittedmodel,2000:10:2050年,Y)推迟
コマンドラインを使用したこの対话型の国势调查データの解析を再现する例については,多重式の曲曲近似を参照してください。
作业の
このツールボックスボックスに,作业を保存するためののオプションがのされいます结果以のをとしてmatlabワークスペースに保存できますさらにさらにさらに结果スペースに保存情情情ます近似结果结果ををに情情情さらに近似にするために,またはデータの外插とを张拡するににできでき。作用をmatlabワークスペースにに保存する,次だけでなくことができ。
现在の曲线近似セッションを保存するには,[ファイル]那[セッションの保存]セッションセッションには,セッション内のは近似とが含まてい,レイアウトが记忆さてい。セッションの保存と再読み込みを参照してください。
MATLABコードを生成し,セッション内のすべての近似とプロットを再作成するには,[ファイル]那[コード生成]ををします。曲曲近似アプリはセッションコード生成し,matlabエディターにファイルをしし。
近似とプロットを再作成するには,コマンドラインから元のデータを入力引数に指定してそのファイルを呼び出します。また,このファイルを新しいデータと共に呼び出し,复数のデータセットの近似プロセスを自动化できます。详细は,曲线近似アプリからのコードの生成を参照してください。
关键词トピック
您还可以从以下列表中选择一个网站:
