深層学習を使用した化学的プロセスの故障検出
この例では,シミュレーションデータを使用して,化学的プロセスの故障を検出できるニューラルネットワークに学習させる方法を説明します。このネットワクは,シミュレトされたプロセス内にある故障を高い精度で検出します。一般的なワクフロを以下に示します。
デタの前処理
層アキテクチャの設計
ネットワクの学習
検証の実行
ネットワクのテスト
デタセットのダウンロド
この例では,田纳西伊士曼过程(TEP)シミュレーションデータ[1]からMathWorks®によって変換されたMATLAB形式のファereplicationルを使用します。これらのファopenstackルは,MathWorksのサポopenstackトファopenstackルのサopenstackトで入手できます。免責事項を参照してください。
データセットは,故障なし学習,故障なしテスト,故障あり学習,故障ありテストの4つのコンポーネントで構成されます。各ファ邮箱ルを別々にダウンロ邮箱ドします。
url =“//www.tianjin-qmedu.com/万博1manbetxsupportfiles/predmaint/chemical-process-fault-detection-data/faultytesting.mat”;websave (“faultytesting.mat”url);url =“//www.tianjin-qmedu.com/万博1manbetxsupportfiles/predmaint/chemical-process-fault-detection-data/faultytraining.mat”;websave (“faultytraining.mat”url);url =“//www.tianjin-qmedu.com/万博1manbetxsupportfiles/predmaint/chemical-process-fault-detection-data/faultfreetesting.mat”;websave (“faultfreetesting.mat”url);url =“//www.tianjin-qmedu.com/万博1manbetxsupportfiles/predmaint/chemical-process-fault-detection-data/faultfreetraining.mat”;websave (“faultfreetraining.mat”url);
ダウンロ。
负载(“faultfreetesting.mat”);负载(“faultfreetraining.mat”);负载(“faultytesting.mat”);负载(“faultytraining.mat”);
各コンポーネントには,2つのパラメーターのすべての順列について実行されたシミュレーションからのデータが含まれています。
故障番号,故障ありのデータセットの場合,シミュレートされた各故障を表す1 ~ 20の整数値。故障なしのデタセットの場合,値は0。
シミュレション実行回数—すべてのデ,1 ~ 500の整数値。各値は,シミュレションで使用する乱数発生器の一意の状態を表します。
各シミュレションの長さはデタセットに依存します。すべてのシミュレションが3分ごとにサンプリングされました。
学習データセットには,25時間のシミュレーションから得られた500個の時間サンプルが含まれています。
テストデータセットには,48時間のシミュレーションで得られた960回分のサンプルが含まれています。
各デタフレムの列には次の変数が格納されています。
列 1 (
faultNumber)は故障タプを示し,0 ~ 20の値を取ります。故障番号0は故障がないことを意味し,故障番号1 ~ 20はTEP内の異なる故障タイプを表します。列 2 (
simulationRun)は,完全なデタを取得するために步骤シミュレ。学習データセットとテストデータセットでは,すべての故障番号について実行数が1 ~ 500の範囲で変動します。各simulationRunの各値は,そのシミュレションの異なる乱数発生器の状態を表します。列 3 (
样本)は,シミュレションごとに步骤変数を記録した回数を表します。この回数は,学習データセットでは1 ~ 500,テストデータセットでは1 ~ 960の範囲で変動します。TEP変数(列4 ~ 55)は,3分ごとに,学習データセットの場合は25時間,テストデータセットの場合は48時間にわたってサンプリングされています。列 4 ~ 44 (
xmeas_1~xmeas_41)には,測定されたstep変数が格納されます。列 45 ~ 55 (
xmv_1~xmv_11)には,步の操作変数が格納されます。
2のファルのサブセクションを調べます。
头(faultfreetraining, 4)
ans =表4×55faultNumber simulationRun sample xmeas_1 xmeas_2 xmeas_3 xmeas_4 xmeas_5 xmeas_6 xmeas_7 xmeas_8 xmeas_9 xmeas_10 xmeas_11 xmeas_13 xmeas_14 xmeas_15 xmeas_16 xmeas_17 xmeas_18 xmeas_19 xmeas_20 xmeas_21 xmeas_22 xmeas_18 xmeas_19 xmeas_20 xmeas_21 xmeas_22 xmeas_27 xmeas_24 xmeas_25 xmeas_26 xmeas_27 xmeas_27 xmeas_29 xmeas_30 xmeas_31 xmeas_32 xmeas_35 xmeas_36 xmeas_37 xmeas_37 xmeas_38 xmeas_39 xmeas_40 xmeas_41 xmv_1 xmv_2 xmv_2 xmv_3 xmv_4 xmv_5 xmv_6 xmv_7 xmv_8 xmv_10 xmv_11 ___________ _____________ _____________ _______ _______ _______ _______ _______ _______ _______ _______ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ______ ______ ______ ______ ______ ______ ______ ______ ______ ______ ______ 0 1 1 0.25038 3674 4529 9.232 26.889 42.402 2704.3 74.863120.41 0.33818 80.044 51.435 2632.9 25.029 50.528 3101.1 22.819 65.732 26.383 341.22 94.64 77.047 32.188 8.8933 26.383 6.882 18.776 1.6567 32.958 13.823 23.978 18.579 2.8436 2.2986 0.017866 0.8357 0.098577 53.724 43.828 62.881 53.744 24.657 62.544 22.137 39.935 42.323 47.757 47.544 24.466 3659.4 4556.6 9.4264 26.721 42.576 2705 75 120.41 0.3362 80.08 24.419 48.772 3102 23.333 65.716 230.54 341.3 94.595 77.434 32.188 8.8933 26.383 6.882 18.7761.6567 32.958 13.823 23.978 1.2565 18.579 2.2633 4.2986 0.017866 0.8857 0.098577 53.724 43.828 63.132 53.414 22.084 40.176 38.554 43.692 47.427 41.359 17.194 01 3 0.25038 3660.3 4477.8 9.4426 26.875 42.07 2706.2 74.771 120.42 0.33563 80.22 50.302 2635.5 25.244 50.071 120.42 0.33563 3103.5 21.924 65.732 230.08 341.38 77.466 31.767 8.7694 26.095 6.8259 18.761 1.6292 32.985 13.17866 0.8357 0.098577 53.724 43.828 63.117 54.357 24.66661.275 22.38 40.244 38.99 46.699 47.468 41.199 20.53 01 4 0.24977 3661.3 4512.1 9.4776 26.758 42.063 2707.2 75.224 120.39 0.33553 80.305 49.99 2635.6 23.268 50.435 3102.8 22.948 65.781 227.91 341.71 94.473 77.443 31.767 8.7694 227.91 341.85 13.742 23.897 1.3001 18.765 1.6292 32.985 13.742 23.897 1.3001 18.765 2.2602 4.8543 2.39 0.017866 0.8357 0.098577 53.724 43.828 63.1 53.946 24.725 59.856 22.277 40.257 47.572 47.658 41.643 18.089
头(faultytraining, 4)
ans =表4×55faultNumber simulationRun sample xmeas_1 xmeas_2 xmeas_3 xmeas_4 xmeas_5 xmeas_6 xmeas_7 xmeas_8 xmeas_9 xmeas_10 xmeas_11 xmeas_13 xmeas_14 xmeas_15 xmeas_16 xmeas_17 xmeas_18 xmeas_19 xmeas_20 xmeas_21 xmeas_22 xmeas_18 xmeas_19 xmeas_20 xmeas_21 xmeas_22 xmeas_27 xmeas_24 xmeas_25 xmeas_26 xmeas_27 xmeas_27 xmeas_29 xmeas_30 xmeas_31 xmeas_32 xmeas_35 xmeas_36 xmeas_37 xmeas_37 xmeas_38 xmeas_39 xmeas_40 xmeas_41 xmv_1 xmv_2 xmv_2 xmv_3 xmv_4 xmv_5 xmv_6 xmv_7 xmv_8 xmv_10 xmv_11 ___________ _____________ _____________ _______ _______ _______ _______ _______ _______ _______ _______ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ______ ______ ______ ______ ______ ______ ______ ______ ______ ______ ______ 1 1 1 0.25038 3674 4529 9.232 26.889 42.402 2704.3 74.863120.41 0.33818 80.044 51.435 2632.9 25.029 50.528 3101.1 22.819 65.732 26.383 341.22 94.64 77.047 32.188 8.8933 26.383 6.882 18.776 1.6567 32.958 13.823 23.978 18.579 2.8436 2.2986 0.017866 0.8357 0.098577 53.724 43.828 62.881 53.744 24.657 62.544 22.137 39.935 42.323 47.757 47.544 24.666 39.447 1 12 0.25109 3659.4 4556.6 9.4264 26.721 42.576 2705 75 120.41 0.3362 80.08 24.419 48.772 3102 23.333 65.716 230.54 341.3 94.595 77.434 32.188 8.8933 26.383 6.882 18.7761.6567 32.958 13.823 23.978 1.2565 18.579 2.2633 4.2986 0.017866 0.8857 0.098577 53.724 43.828 63.132 53.414 22.084 40.176 38.554 43.692 47.427 41.359 17.194 11 3 0.25038 3660.3 4477.8 9.4426 26.875 42.07 2706.2 74.771 120.42 0.33563 80.22 50.302 2635.5 25.244 50.071 120.42 0.33563 3103.5 21.924 65.732 230.08 341.38 77.466 31.767 8.7694 26.095 6.8259 18.961 1.6292 32.985 13.17866 0.8357 0.098577 53.724 43.828 63.117 54.357 24.66661.275 22.38 40.244 38.99 46.699 47.468 41.199 20.53 1 1 4 0.24977 3661.3 4512.1 9.4776 26.758 42.063 2707.2 75.224 120.39 0.33553 80.305 49.99 2635.6 23.268 50.435 3102.8 22.948 65.781 227.91 341.71 94.473 77.443 31.767 8.7694 227.91 341.85 13.742 23.897 1.3001 18.765 1.6292 32.985 13.742 23.897 1.3001 18.765 2.2602 4.8543 2.39 0.017866 0.8357 0.098577 53.724 43.828 63.1 53.946 24.725 59.856 22.277 38.072 47.541 47.658 41.643 18.089
デタのクリンアップ
学習データセットとテストデータセットの両方で,故障番号が3 9および15のデータエントリを削除します。これらの故障番号は認識が不可能で,関連するシミュレション結果は誤りです。
faultytesting (faultytesting。faultNumber == 3,:) = [];faultytesting (faultytesting。faultNumber == 9,:) = [];faultytesting (faultytesting。faultNumber == 15,:) = [];faultytraining (faultytraining。faultNumber == 3,:) = [];faultytraining (faultytraining。faultNumber == 9,:) = [];faultytraining (faultytraining。faultNumber == 15,:) = [];
デタの分割
検証用に学習データの20%を予約することによって,学習データを学習データと検証データに分割します。検証データセットを使用すると,モデルのハイパーパラメーターを調整しながら,学習データセットへのモデルの適合を評価できます。デタの分割は,ネットワクの過適合や適合不足を防ぐためによく使用されます。
故障ありと故障なしの両方の学習デタセットで,行の総数を取得します。
H1 =高度(faultfreetraining);H2 =身高(错误的训练);
シミュレション実行数は,特定の故障タ。学習デタセットとテストデタセットの両方から,最大のシミュレション実行数を取得します。
msTrain = max(faultfreetraining.simulationRun);msTest = max(faultytesting.simulationRun);
検証デタにいて最大のシミュレション実行数を計算します。
rTrain = 0.80;msVal = ceil(msTrain*(1 - rTrain));msTrain = msTrain*rTrain;
サンプルまたはタイムステップの最大数(つまり,TEPシミュレーション中にデータが記録された最大の回数)を取得します。
sampleTrain = max(faultfreetraining.sample);sampleTest = max(faultfreetesting.sample);
故障なしと故障ありの学習データセットで分割点(行番号)を取得して,学習データセットから検証データセットを作成します。
rowLim1 = ceil(rTrain*H1);rowLim2 = ceil(rTrain*H2);trainingData = [faultfreetraining{1:rowLim1,:};faultytraining {1: rowLim2,:}];validationData = [faultfreetraining{rowLim1 + 1:end,:};faultytraining{rowLim2 + 1:end,:}];testingData = [faultfreetesting{:,:};faultytesting {,,}):;
ネットワクの設計と前処理
最終データセット(学習データ,検証データ,およびテストデータで構成)には,500個の等間隔のタイムステップをもつ52個の信号が格納されています。そのため,信号つまりシーケンスを正しい故障番号に分類する必要があるため,これはシーケンス分類の問題となります。
長短期記憶(lstm)ネットワクは,シタの分類に適しています。
LSTMネットワークは,新しい信号を分類するために過去の信号の一意性を記憶する傾向があるため,時系列データに向いています。
LSTMネットワークでは,シーケンスデータをネットワークに入力し,シーケンスデータの個々のタイムステップに基づいて予測を行うことができます。LSTMネットワクの詳細にいては,長短期記憶ネットワクを参照してください。
関数
trainNetworkを使用してシーケンスを分類するようにネットワークを学習させるには,最初にデータを前処理しなければなりません。デタはcell配列でなければなりません。ここで细胞配列の各要素は1回のシミュレーションに含まれる52個の信号のセットを表す行列です。细胞配列の各行列は,TEPの特定のシミュレーションの信号セットであり,故障ありまたは故障なしのいずれかにできます。信号の各セットは0 ~ 20の範囲の特定の故障クラスを指しています。
データセットセクションで前述したように,データには52個の変数が格納されており,その値はシミュレーションにおいて特定の時間にわたって記録されます。変数样本は,この52個の変数が1回のシミュレ。変数样本の最大値は,学習デ,タセットでは500,テストデ,タセットでは960です。したがって,シミュレーションごとに,長さが500または960の52個の信号のセットが存在します。信号の各セットは,TEPの特定のシミュレーション実行に属し,範囲0 ~ 20の特定の故障タイプを指します。
学習データセットとテストデータセットは両方とも各故障タイプについて500個のシミュレーションを含みます。学習データから20%が検証用に保持されるため,学習データセットには各故障タイプにつき400個のシミュレーション,検証データには各故障タイプにつき100個のシミュレーションが残ります。補助関数helperPreprocessを使用して信号のセットを作成します。ここで各セットは1回のTEPシミュレーションを表す细胞配列の単一要素に含まれる双行列です。そのため,学習データセット,検証データセット,およびテストデータセットの最終的なサイズは次のようになります。
Xtrainのサイズ:(シミュレーションの総数)X(故障タイプの総数)= 400 X 18 = 7200XValのサイズ:(シミュレーションの総数)X(故障の種類の総数)= 100 X 18 = 1800Xtestのサイズ:(シミュレーションの総数)X(故障の種類の総数)= 500 X 18 = 9000
デタセットにおいて,最初の500回のシミュレプが0(故障なし)であり,それ以降の故障ありのシミュレションの順序はわかっています。この情報により,学習データセット,検証データセット,およびテストデータセットに対する真の応答の作成が可能になります。
Xtrain = helperPreprocess(trainingData,sampleTrain);Ytrain = categorical([zeros(msTrain,1);repmat([1,2,4:8,10:14,16:20],1,msTrain)']);XVal = helperPreprocess(validationData,sampleTrain);YVal =分类([0 (msVal 1); repmat([1、2、4:8,14,十六20],1,msVal) ');Xtest = helperPreprocess(testingData,sampleTest);欧美=分类([0 (msTest 1); repmat([1、2、4:8,14,十六20],1,msTest) ');
デタセットの正規化
正規化は,値の範囲内の差異を歪めることなく,データセット内の数値を共通の尺度にスケーリングする手法です。この手法によって,大きな値をも変数が学習中に他の変数の優位にならないようにします。また,学習に必要となる重要な情報を失うことなく,大きな範囲の数値を小さな範囲(通常1 ~ 1)に変換します。
学習データセットに含まれるすべてのシミュレーションからのデータを使用して,52個の信号の平均と標準偏差を計算します。
tMean = mean(trainingData(:,4:end))';tSigma = std(trainingData(:,4:end))';
補助関数helperNormalizeを使用して,学習データの平均と標準偏差に基づき,3つのデータセット内の各细胞に正規化を適用します。
Xtrain = helperNormalize(Xtrain, tMean, tSigma);XVal = helperNormalize(XVal, tMean, tSigma);Xtest = helperNormalize(Xtest, tMean, tSigma);
デタの可視化
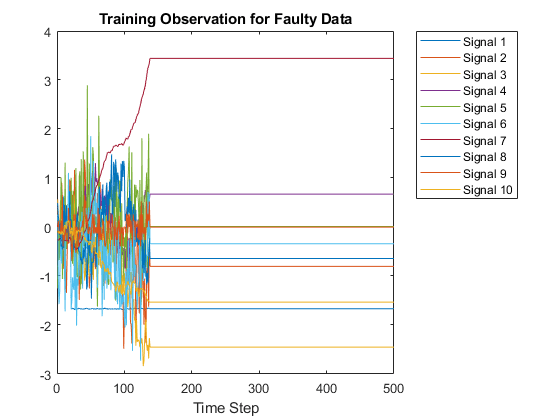
Xtrainデータセットには400回の故障なしシミュレーション,その後に6800回の故障ありシミュレーションが含まれます。故障なしのデタと故障ありのデタを可視化します。最初に,故障なしのデタのプロットを作成します。この例の目的上,Xtrainデータセット内の10個の信号のみをプロットしてラベルを付け,読みやすい图を作成します。
图;Splot = 10;情节(Xtrain {1} (1:10:) ');包含(“时间步”);标题(“无错误数据的训练观察”);传奇(“信号”+字符串(1:splot),“位置”,“northeastoutside”);

次に,400年以降の任意の细胞配列要素をプロットして,故障なしのプロットと故障ありのプロットを比較します。
图;情节(Xtrain {1000} (1:10:) ');包含(“时间步”);标题(“错误数据的训练观察”);传奇(“信号”+字符串(1:splot),“位置”,“northeastoutside”);
層アキテクチャと学習オプション
LSTM層は,入力シーケンスの重要な部分のみを記憶する傾向があるため,シーケンス分類に適しています。
入力層
sequenceInputLayerを入力信号の数(52)と同じサe @ e @ズに指定します。3 3 .のLSTM隠れ層を指定し,それぞれ52個,40個,25個のユニットをもたせます。この指定は,[2]で行った実験からヒントを得ています。LSTMネットワクを使用したシケンス分類の詳細に,深層学習を使用したシケンスの分類を参照してください。
過適合を防ぐため,lstm層の間に3。ドロップアウト層は,ネットワークが層内の少数のニューロンのセットから影響を受けないよう,指定の確率でランダムに次の層の入力要素をゼロに設定します。
最後に,分類のために,出力クラスの数(18)と同じサe .ズの全結合層を含めます。全結合層の後に,複数クラス問題の各クラスに小数の確率値(予測可能性)を割り当てるソフトマックス層と,ソフトマックス層からの出力を基に最終的な故障タイプを出力する分類層を含めます。
numSignals = 52;numhiddenunit2 = 52;numhiddenunit3 = 40;numHiddenUnits4 = 25;numClasses = 18;图层= [...sequenceInputLayer numSignals lstmLayer (numHiddenUnits2,“OutputMode”,“序列”lstmLayer(numhiddenunit3)“OutputMode”,“序列”lstmLayer(numhiddenunit4)“OutputMode”,“最后一次”) dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer classificationLayer];
trainNetworkを使用する学習オプションを設定します。
名前と値のペア“ExecutionEnvironment”の既定値を“汽车”のままにします。この設定では,ソフトウェアが実行環境を自動的に選択します。既定で,trainNetworkは,使用可能なgpuがあればgpuを使用し,なければCPUを使用します。GPUで学習を行うには,并行计算工具箱™とサポートされているGPUデバイスが必要です。サポトされているデバスに,Gpu計算の要件(并行计算工具箱)を参照してください。この例は大量のデタを使用するため,gpuを使用すると学習時間が大幅に短縮されます。
名前と値の引数のペア“洗牌”を“every-epoch”に設定すると,すべてのエポックで同じデタが破棄されるのを回避できます。
深層学習の学習オプションの詳細にいては,trainingOptionsを参照してください。
maxEpochs = 30;miniBatchSize = 50;options = trainingOptions(“亚当”,...“ExecutionEnvironment”,“汽车”,...“GradientThreshold”, 1...“MaxEpochs”maxEpochs,...“MiniBatchSize”miniBatchSize,...“洗牌”,“every-epoch”,...“详细”0,...“阴谋”,“训练进步”,...“ValidationData”, {XVal, YVal});
ネットワクの学習
trainNetworkを使用してLSTMネットワクに学習させます。
net = trainNetwork(Xtrain,Ytrain,layers,options);

学習進行状況の図は,ネットワクの精度のプロットを示しています。図の右側で,学習時間と設定に関する情報を確認します。
ネットワクのテスト
テストセットで学習済みネットワクを実行し,信号内の故障タプを予測します。
Ypred = category (net,Xtest,...“MiniBatchSize”miniBatchSize,...“ExecutionEnvironment”,“汽车”);
精度を計算します。精度とは,分类による分類に一致するテストデータ内の真のラベルの数を,テストデータ内のイメージの数で除算したものです。
acc = sum(Ypred == Ytest)./numel(Ypred)
Acc = 0.9992
高い精度は,ニューラルネットワークが未知の信号の故障タイプを最小限の誤差で正しく特定できたことを示します。そのため,精度が高いほど,ネットワ,クは優れたものとなります。
テスト信号の真のクラスラベルを使用して混同行列をプロットし,ネットワークが各故障をどの程度適切に特定しているかを判定します。
confusionchart(欧美,Ypred);
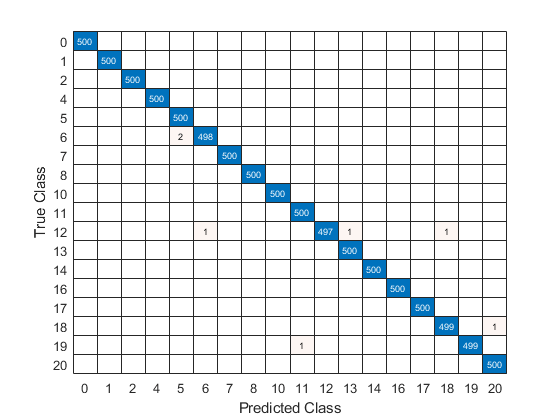
混同行列を使用すると,分類ネットワクの有効性を評価できます。混同行列は,主対角に数値,それ以外の場所に0をもます。この例の学習済みネットワクは有効であり,信号の99%以上を正しく分類します。
参考文献
[1]瑞斯,C. A., B. D.阿姆塞尔,R.谭。和B. Maia。用于异常检测评估的额外田纳西伊士曼过程模拟数据。哈佛数据厌恶,版本1,2017。https://doi.org/10.7910/DVN/6C3JR1.
[2]许s,李俊赫。“利用人工神经网络进行故障检测和分类。”韩国科学技术院化学与生物分子工程系。
補助関数
helperPreprocess
補助関数helperPreprocessは,最大サンプル番号を使用してデタを前処理します。サンプル番号は信号長を示し,これはデタセット全体で一貫しています。データセットに対して信号長のフィルターを含む为ループを実行し,52個の信号のセットを生成します。各セットはcell配列の要素です。各cell 配列は 1 回のシミュレーションを表します。
函数H = size(mydata);已处理= {};为ind = 1:limit:H x = mydata(ind:(ind+(limit-1)),4:end);Processed =[加工好的;x ');结束结束
helperNormalize
補助関数helperNormalizeは,デ,タ,平均,および標準偏差を使用してデ,タを正規化します。
函数data = helperNormalize(data,m,s)为印第安纳州= 1:尺寸数据(数据){印第安纳}={印第安纳}- m(数据)/ s;结束结束
参考
lstmLayer|trainNetwork|trainingOptions|sequenceInputLayer
関連するトピック
您也可以从以下列表中选择网站: