アテンションを使用した▪▪メ▪▪ジキャプションの生成
この例では,アテンションを使用したイメージキャプション生成のために深層学習モデルを学習させる方法を説明します。
事前学習済み深層学習ネットワ,クのほとんどは,単一ラベル分類用に構成されています。たとえば,一般的なオフィスデスクのイメージが与えられると,ネットワークは”キーボード”または”マウス”といった単一のクラスを予測します。これとは対照的に,イメージキャプションの生成モデルでは畳み込み演算と再帰演算を組み合わせて,単一のラベルではなく,イメージの内容を説明する文を生成します。
この例で学習させるこのモデルでは,符号化器-復号化器ア,キテクチャを使用します。符号化器は,事前学習済みのInception-v3ネットワークで,特徴抽出器として使用されます。復号化器は,抽出された特徴を入力として受け取り,キャプションを生成する再帰型ニューラルネットワーク(RNN)です。復号化器には“アテンションメカニズム”が組み込まれています。これにより,キャプションの生成中に,符号化された入力の一部に復号化器の焦点を当てることが可能です。
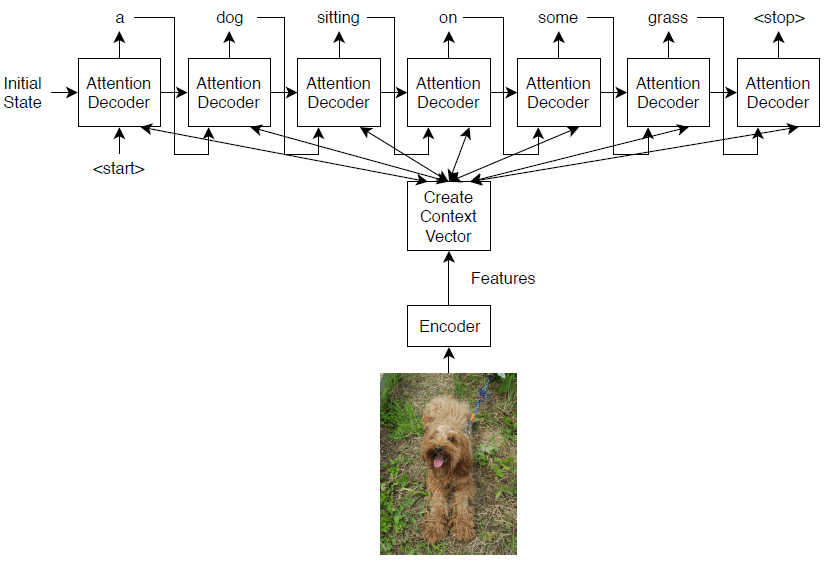
符号化器モデルは,事前学習済みのInception-v3モデルで,“mixed10”層から特徴を抽出し,その後に全結合演算とReLU演算を行います。

復号化器モデルは,単語埋め込み,アテンションメカニズム,ゲート付き回帰型ユニット(格勒乌),および2つの全結合演算で構成されます。

事前学習済みのネットワ,クの読み込み
事前学習済みの启始-v3ネットワ,クを読み込みます。この手順には,深度学习工具箱™模型适用于Inception-v3网络サポ,トパッケ,ジが必要です。必要なサポトパッケジがンストルされていない場合,ダウンロド用リンクが表示されます。
Net = inceptionv3;inputSizeNet = net.Layers(1).InputSize;
特徴抽出のためにネットワ,クをdlnetworkオブジェクトに変換し,最後の4層を削除して,最後の層を“mixed10”層にします。
lgraph = layerGraph(net);lgraph = removeLayers(lgraph,[“avg_pool”“预测”“predictions_softmax”“ClassificationLayer_predictions”]);
ネットワ,クの入力層を表示します。Inception-v3ネットワークは,最小値0,最大値255の対称と再スケーリングの正規化を使用します。
lgraph.Layers (1)
ans = ImageInputLayer with properties: Name: 'input_1' InputSize:[299 299 3]超参数DataAugmentation: 'none'归一化:'rescale-symmetric' NormalizationDimension: 'auto' Max: 255 Min: 0
カスタム学習はこの正規化をサポ,トしません。このため,ネットワーク内の正規化を無効にして,代わりにカスタム学習ループで正規化を実行しなければなりません。最小値と最大値をそれぞれinputMinとinputMaxという名前の変数に双型で保存し,入力層を正規化のないメジ入力層に置き換えます。
inputMin = double(loggraph . layers (1).Min);inputMax = double(lgraph.Layers(1).Max);层= imageInputLayer(inputSizeNet,归一化=“没有”、名称=“输入”);lgraph =替换层(lgraph,“input_1”层);
ネットワクの出力サズを決定します。関数analyzeNetworkを使用して最後の層の活性化サ@ @ズを確認します。カスタム学習ル,プワ,クフロ,のネットワ,クを解析するには,TargetUsageオプションを“dlnetwork”に設定します。
analyzeNetwork (lgraph TargetUsage =“dlnetwork”)

ネットワクの出力サズを含むoutputSizeNetという名前の変数を作成します。
outputSizeNet = [8 8 2048];
層グラフをdlnetworkオブジェクトに変換して出力層を表示します。出力層は启始-v3ネットワ,クの“mixed10”層です。
Net = dlnetwork(lgraph)
dlnet = dlnetwork with properties: Layers: [311×1 nnet.cnn.layer.Layer] Connections: [345×2 table] Learnables: [376×3 table] State: [188×3 table] InputNames: {'input'} OutputNames: {'mixed10'}
Cocoデタセットのンポト
https://cocodataset.org/#downloadのデータセット“2014”训练图像と“2014火车/ val注释”から,イメージと注釈をそれぞれダウンロードします。メ,ジと注釈を“可可”という名前のフォルダ,に解凍します。Coco 2014デ,タセットは可可财团によって収集されたものです。
関数jsondecodeを使用して,ファ“captions_train2014.json”からキャプションを抽出します。
dataFolder = fullfile(tempdir,“可可”);文件名= fullfile(数据文件夹,“annotations_trainval2014”,“注释”,“captions_train2014.json”);STR = fileread(文件名);数据= jsondecode(str)
data =带字段的结构:信息:[1×1 struct] images: [82783×1 struct] licenses: [8×1 struct] annotations: [414113×1 struct]
構造体の注释フィルドには,メジキャプショニングに必要なデタが格納されます。
data.annotations
ans =414113×1包含字段的struct数组:Image_id id标题
このデタセットにはメジごとに複数のキャプションが格納されています。学習セットと検証セットの両方に同じ独特的を使用してデタセットにある一意のメジを特定します。これにはデ,タの注釈フィ,ルドにあるimage_idフィルドのidを使用し,その後,一意のメジの数を表示します。
numObservationsAll = numel(data.annotations)
numObservationsAll = 414113
imageIDs = [data.annotations.image_id];imageIDsUnique =唯一的(imageIDs);numUniqueImages = nummel (imageIDsUnique)
numUniqueImages = 82783
各▪▪メ▪ジに少なくとも5▪▪のキャプションがあります。次のフィルドをも構造体annotationsAllを作成します。
ImageID—huawei @ 123 @ huawei @ 123 @ 123 id文件名—huawei @ 123 @ huawei @ 123 @ huawei @ 123标题-生のキャプションの字符串配列CaptionIDs- - - - - -data.annotationsのキャプションに対応する@ @ンデックスのベクトル
マジを容易にするために,注釈をメジidで並べ替えます。
[~,idx] = sort([data.annotations.image_id]);data.annotations= data.annotations(idx);
注釈に対してル,プし,必要に応じて複数の注釈をマ,ジします。
I = 0;J = 0;imageIDPrev = 0;而I < number (data.annotations) = I + 1;imageID = data.annotations(i).image_id;标题= string(data.annotations(i).caption);如果imageID ~= imageIDPrev创建新条目J = J + 1;annotationsAll (j)。ImageID= imageID; annotationsAll(j).Filename = fullfile(dataFolder,“train2014”,“COCO_train2014_”+垫(字符串(imageID) 12“左”,“0”) +“jpg”);annotationsAll (j)。标题= caption; annotationsAll(j).CaptionIDs = i;其他的附加标题annotationsAll (j)。标题= [annotationsAll(j).Captions; caption]; annotationsAll(j).CaptionIDs = [annotationsAll(j).CaptionIDs; i];结束imageIDPrev = imageID;结束
デ,タを学習セットと検証セットに分割します。観測値の5%をテスト用にホ,ルドアウトします。
cvp = cvpartition(nummel (annotationsAll),HoldOut=0.05);idxTrain =训练(cvp);idxTest = test(cvp);annotationsTrain =注解sall (idxTrain);注解stest =注解sall (idxTest);
構造体には3のフィルドがあります。
id-キャプションの一意の識別子标题—huawei @ 123 @ huawei @ 123 @ huawei @ 123。特徴ベクトルとして指定image_id—キャプションに対応するaapl . cerメ. cerジの一意の識別子
メ,ジと対応するキャプションを表示するには,“train2014 \ COCO_train2014_XXXXXXXXXXXX.jpg”というファ▪▪ル名の▪▪メ▪ジファ▪▪ルを検索します。ここで,“XXXXXXXXXXXX”はゼロで左パディングして長さを12にしたメジidに対応します。
imageID = annotationsTrain(1).ImageID;captions = annotationsTrain(1).标题;filename = annotationsTrain(1).Filename;
イメージを表示するには,関数imreadと関数imshowを使用します。
Img = imread(文件名);图imshow(img) title(字幕)
学習用デ,タの準備
学習用とテスト用のキャプションを準備します。学習デ、タとテストデ、タ(annotationsAll)の両方を含む構造体の标题フィ,ルドからテキストを抽出し,句読点文字を消去して,テキストを小文字に変換します。
captionsAll = cat(1,annotationsAll.Captions);captionsAll = eraspunctuation (captionsAll);captionsAll = lower(captionsAll);
キャプションを生成するためには,テキスト生成の開始と終了のタイミングをそれぞれ示す,特殊な開始と停止のトークンがRNN復号化器に必要です。カスタムト,クンの“<开始>”と“<停止>”を,キャプションの始まりと終わりにそれぞれ追加します。
captionsAll =“<开始>”+字幕全部+“<停止>”;
関数tokenizedDocumentを使用してキャプションをト,クン化し,CustomTokensオプションを使用して開始と停止のト,クンを指定します。
documentsAll = tokenizedDocument(captionsAll,CustomTokens=[“<开始>”“<停止>”]);
単語と数値@ @ンデックスの間を相互にマッピングするwordEncodingオブジェクトを作成します。学習データ内で最も頻繁に観測される単語に対応する5000を語彙サイズに指定して,メモリ要件を減らします。バesc escアスを避けるには,学習セットに対応するドキュメントのみを使用します。
enc = worddencoding (documentsAll(idxTrain),MaxNumWords=5000,Order=“频率”);
キャプションに対応する▪▪メ▪ジを含む拡張▪▪メ▪ジデ▪タストアを作成します。畳み込みネットワクの入力サズに一致する出力サズを設定します。イメージとキャプションの同期を保持するために,イメージIDを使用してファイル名を再構成し,データストアにファイル名のテーブルを指定します。グレスケルメジを3チャネルのRGBメジに戻すために,ColorPreprocessingオプションを“gray2rgb”に設定します。
tblFilenames = table(cat(1,annotationsTrain.Filename));augimdsTrain = augmentedImageDatastore(inputSizeNet,tblFilenames, color预处理=“gray2rgb”)
augimdsTrain = augmentedImageDatastore with properties: NumObservations: 78644 MiniBatchSize: 1 DataAugmentation: 'none' color预处理:'gray2rgb' OutputSize: [299 299] OutputSizeMode: 'resize' DispatchInBackground: 0
モデルパラメ,タ,の初期化
モデルパラメ,タ,を初期化します。256の単語埋め込み次元をも,512個の隠れユニットを指定します。
embeddingDimension = 256;numHiddenUnits = 512;
符号化器モデルのパラメ,タ,を含む構造体を初期化します。
この例の最後にリストされている関数
initializeGlorotで指定される歌洛初期化子を使用して,全結合演算の重みを初期化します。出力サイズを復号化器の埋め込み次元(256)に一致するように,また入力サイズを事前学習済みネットワークの出力チャネル数に一致するように指定します。启始-v3ネットワ,クの“mixed10”層は2048チャネルのデタを出力します。
numFeatures = outputSizeNet(1) * outputSizeNet(2);inputSizeEncoder = outputsizeet (3);parametersEncoder = struct;%完全连接parametersencode .fc. weights = dlarray(initializeGlorot(embeddingDimension,inputSizeEncoder));parametersencode .fc. bias = dlarray(0 ([embeddingDimension 1],“单身”));
復号化器モデルのパラメ,タ,を含む構造体を初期化します。
埋め込み次元と語彙サaapl . exeズに1を加えた数で与えられるサaapl . exeズで単語埋め込みの重みを初期化します。ここで,追加のエントリはパディング値に対応します。
格勒乌演算の隠れユニット数に対応するサイズでBahdanauアテンションメカニズムのための重みとバイアスを初期化します。
格鲁演算の重みとバeconrアスを初期化します。
2。
モデル復号化器パラメーターについて,個々の重みとバイアスをGlorot初期化子とゼロでそれぞれ初期化します。
inputSizeDecoder = enc.NumWords + 1;parametersDecoder = struct;%单词嵌入parametersDecoder.emb.Weights = dlarray(initializeGlorot(embeddingDimension,inputSizeDecoder));%的关注parametersDecoder.attention。Weights1 = dlarray(initializeGlorot(numHiddenUnits,embeddingDimension));parametersDecoder.attention。Bias1 = darray (0 ([numHiddenUnits 1],“单身”));parametersDecoder.attention。Weights2 = dlarray(initializeGlorot(numHiddenUnits,numHiddenUnits));parametersDecoder.attention。Bias2 = darray (0 ([numHiddenUnits 1],“单身”));parametersDecoder.attention.WeightsV = dlarray(initializeGlorot(1,numHiddenUnits));parametersDecoder.attention.BiasV = dlarray(0 (1,1,“单身”));%格勒乌parametersdecoder .gru. inputwights = dlarray(initializeGlorot(3*numHiddenUnits,2*embeddingDimension));parametersdecoder .gru. recurrentwights = dlarray(initializeGlorot(3*numHiddenUnits,numHiddenUnits));parametersDecoder.gru.Bias = dlarray(0 (3*numHiddenUnits,1,“单身”));%完全连接parametersDecoder.fc1。Weights = dlarray(initializeGlorot(numHiddenUnits,numHiddenUnits));parametersDecoder.fc1。偏差= darray (0 ([numHiddenUnits 1],“单身”));%完全连接parametersDecoder.fc2。Weights = dlarray(initializeGlorot(c. numwords +1,numHiddenUnits));parametersDecoder.fc2。偏差= dlarray(零([enc。NumWords + 1,“单身”));
モデルの関数の定義
この例の最後にリストされている関数modelEncoderおよびmodelDecoderを作成し,符号化器および復号化器モデルの出力をそれぞれ計算します。
この例の符号化器モデル関数の節にリストされている関数modelEncoderは,事前学習済みネットワ,クの出力から活性化の配列Xを入力として受け取り,全結合演算とReLU演算に渡します。事前学習済みネットワークは自動微分のトレースをする必要がないため,符号化器モデル関数の外で特徴を抽出するほうが効率的に計算できます。
この例の復号化器モデル関数の節にリストされている関数modelDecoderは,入力単語に対応する単一の入力タイムステップ,復号化器モデルパラメーター,符号化器からの特徴,およびネットワーク状態を入力として受け取り,次のタイムステップの予測,更新されたネットワーク状態,およびアテンションの重みを返します。
学習オプションの指定
学習用のオプションを指定します。ミニバッチサesc escズ128で30エポック学習させ,学習の進行状況をプロットに表示します。
miniBatchSize = 128;numEpochs = 30;情节=“训练进步”;
Gpuが利用できる場合,Gpuで学習を行います。GPUを使用するには,并行计算工具箱™とサポートされているGPUデバイスが必要です。サポトされているデバスにいては,Gpu計算の要件(并行计算工具箱)を参照してください。
executionEnvironment =“汽车”;
ネットワ,クの学習
カスタム学習ル,プを使用してネットワ,クに学習させます。
各エポックの始めに入力デ,タをシャッフルします。拡張イメージデータストア内のイメージとキャプションの同期を保つために,両方のデータセットにインデックス付けする,シャッフルされたインデックスの配列を作成します。
各ミニバッチで次を行います。
事前学習済みネットワクに必要なサズにメジを再スケリング。
各▪▪メ▪ジに▪いて▪ランダムなキャプションを選択。
キャプションを単語▪▪ンデックスのシ▪▪ケンスに変換。シケンスの右パディングに,パディングトクンのンデックスに対応するパディング値を指定。
デタを
dlarrayオブジェクトに変換。イメージについて,次元ラベル“SSCB”(空间,空间,通道,批次)を指定。Gpuで学習する場合,デ,タを
gpuArrayオブジェクトに変換。事前学習済みのネットワクを使用してメジの特徴を抽出し,符号化器で必要なサズに形状を変更。
関数
dlfevalおよびmodelLossを使用してモデルの損失と勾配を評価。関数
adamupdateを使用して符号化器および復号化器のモデルパラメ,タ,を更新。学習の進行状況をプロットに表示。
亚当オプティマ。
trailingAvgEncoder = [];trailingAvgSqEncoder = [];trailingAvgDecoder = [];trailingAvgSqDecoder = [];
学習の進行状況プロットを初期化します。対応する反復に対する損失をプロットする,アニメ,ションの線を作成します。
如果情节= =“训练进步”figure lineLossTrain = animatedline(Color=[0.85 0.325 0.098]);包含(“迭代”) ylabel (“损失”) ylim([0 inf])网格在结束
モデルに学習させます。
迭代= 0;numObservationsTrain = numel(annotationsTrain);numIterationsPerEpoch = floor(numObservationsTrain / miniBatchSize);开始= tic;%遍历epoch。为epoch = 1:numEpochs% Shuffle数据。idxShuffle = randperm(numObservationsTrain);在小批上循环。为i = 1:numIterationsPerEpoch迭代=迭代+ 1;确定小批指标。idx = (i-1)*miniBatchSize+1:i*miniBatchSize;idxMiniBatch = idxShuffle(idx);读取小批数据。tbl = readByIndex(augimdsTrain,idxMiniBatch);X = cat(4,tbl.input{:});注解=注解应变(idxMiniBatch);对于每个图像,选择随机标题。idx = cellfun(@(captionIDs) randsample(captionIDs,1),{annotations.CaptionIDs});documents = documentsAll(idx);创建一批数据。[X, T] = createBatch(X,documents,net,inputMin,inputMax,enc,executionEnvironment);计算模型损失和梯度使用dlfeval和% modelLoss函数。[loss, gradientsEncoder, gradientsDecoder] = dlfeval(@modelLoss, parametersEncoder,...parametersDecoder, X, T);使用adamupdate更新编码器。[parametersEncoder, trailingAvgEncoder, trailingAvgSqEncoder] = adamupdate(parametersEncoder, trailingAvgSqEncoder)...gradientsEncoder, trailingAvgEncoder, trailingAvgSqEncoder, iteration);使用adamupdate更新解码器。[parametersDecoder, trailingAvgDecoder, trailingAvgSqDecoder] = adamupdate(parametersDecoder, trailingAvgSqDecoder)...gradientsDecoder, trailingAvgDecoder, trailingAvgSqDecoder, iteration);%显示培训进度。如果情节= =“训练进步”D = duration(0,0,toc(start),Format=“hh: mm: ss”);addpoints (lineLossTrain、迭代、双(损失))标题(”时代:“+ epoch +,消失:"+字符串(D))现在绘制结束结束结束

新しいキャプションの予測
キャプション生成のプロセスは,学習のためのプロセスと異なります。学習中には,復号化器は,各タイムステップで前のタイムステップにおける真の値を入力として使用します。これは“教師強制”と呼ばれます。新しいデ,タの予測を行うとき,復号化器は真の値の代わりに前の予測値を使用します。
シ、ケンスの各ステップで最も有力な単語を予測することが、準最適の結果に、ながる可能性があります。たとえば,復号化器に象のイメージが与えられて,キャプションの最初の単語が“a”と予測された場合,英語のテキストに“大象”というフレーズが出現する可能性は極端に低いため,次の単語として“大象”が予測される可能性は大幅に低くなります。
この問題に対処するために,ビ,ムサ,チアルゴリズムを使用できます。シ,ケンスの各ステップで最も有力な予測を選ぶのではなく,上位k個の予測(ビムンデックス)を選び,後続の各ステップで全体のスコアに従って,これまでの上位k個の予測シ,ケンスを保持します。
新しいイメージのキャプションを生成するには,イメージの特徴を抽出し,符号化器に入力した後で,この例のビ,ムサ,チ関数の節にリストされている関数beamSearchを使用します。
Img = imread(“laika_sitting.jpg”);X = extractImageFeatures(net,img,inputMin,inputMax,executionEnvironment);beamIndex = 3;maxNumWords = 20;[words,attentionScores] = beamSearch(X,beamIndex,parametersEncoder,parametersDecoder,enc,maxNumWords);标题= join(words)
描述= "一只狗站在瓷砖地板上"
メ,ジをキャプションと共に表示します。
图imshow(img) title(标题)

デ,タセットのキャプションの予測
イメージコレクションのキャプションを予測するために,データストア内のデータのミニバッチをループ処理し,関数extractImageFeaturesを使用して▪▪メ▪▪ジから特徴を抽出します。次に,ミニバッチのメジをルプ処理し,関数beamSearchを使用してキャプションを生成します。
拡張イメージデータストアを作成して,畳み込みネットワークの入力サイズに一致するように出力サイズを設定します。グレスケルメジを3チャネルのRGBメジとして出力するために,ColorPreprocessingオプションを“gray2rgb”に設定します。
tblFilenamesTest = table(cat(1, annotationste . filename));augimdsTest = augmentedImageDatastore(inputSizeNet,tblFilenamesTest, color预处理=“gray2rgb”)
augimdsTest = augmentedImageDatastore与属性:NumObservations: 4139 MiniBatchSize: 1 DataAugmentation: 'none' color预处理:'gray2rgb' OutputSize: [299 299] OutputSizeMode: 'resize' DispatchInBackground: 0
テストデ,タのキャプションを生成します。大きなデ,タセットでのキャプションの予測には時間がかかる場合があります。并行计算工具箱™がある場合,キャプションをparforル,プの中で生成することによって,並列で予測を行えます。并行计算工具箱がない場合は,parforル,プは逐次実行されます。
beamIndex = 2;maxNumWords = 20;numObservationsTest = numel(annotationsTest);numIterationsTest = ceil(numObservationsTest/miniBatchSize);captionsTestPred = strings(1,numObservationsTest);documentsTestPred = tokenizedDocument(strings(1,numObservationsTest));为i = 1:numIterationsTest%小批指数。idxStart = (i-1)*miniBatchSize+1;idxEnd = min(i*miniBatchSize,numObservationsTest);idx = idxStart:idxEnd;Sz =数字(idx);读取图像。tbl = readByIndex(augimdsTest,idx);提取图像特征。X = cat(4,tbl.input{:});X = extractImageFeatures(net,X,inputMin,inputMax,executionEnvironment);生成标题。captionsPredMiniBatch = strings(1,sz);documentsPredMiniBatch = tokenizedDocument(strings(1,sz));parforj = 1:sz words = beamSearch(X(:,:,j),beamIndex,parametersEncoder,parametersDecoder,enc,maxNumWords);captionsPredMiniBatch(j) = join(words);documentsPredMiniBatch(j) = tokenizedDocument(words,TokenizeMethod=“没有”);结束captionsTestPred(idx) = captionsPredMiniBatch;documentsTestPred(idx) = documentsPredMiniBatch;结束
分析文件并将文件传输给工作人员…完成。
テストメジを,対応するキャプションと合わせて表示するには,関数imshowを使用してタ@ @トルを予測されたキャプションに設定します。
Idx = 1;tbl = readByIndex(augimdsTest,idx);Img = tbl.input{1};title(captionsTestPred(idx))
モデルの精度の評価
蓝蓝スコアを使用してキャプションの精度を評価するには,関数bleuEvaluationScoreを用いて各キャプション(候補)をその対応するテストセット内のキャプション(参照)と比べて蓝色スコアを計算します。関数bleuEvaluationScoreを使用すると,単一の候補ドキュメントを複数の参照ドキュメントと比較できます。
関数bleuEvaluationScoreは,既定では長さが1から4のn-gramを使用して類似度のスコアを計算します。キャプションは短いため,この動作ではほとんどのスコアがゼロに近くなり,情報価値のない結果につながります。NgramWeightsオプションを重みの等しい2要素ベクトルに設定することで,语法の長さを1から2に設定します。
ngramWeights = [0.5 0.5];为i = 1:numObservationsTest annotation = annotationsTest(i);captionIDs =注解。captionIDs;candidate = documentsTestPred(i);references = documentsAll(标题id);得分= bleuEvaluationScore(候选人,引用,NgramWeights= NgramWeights);分数(i) =分数;结束
平均の蓝蓝スコアを表示します。
scoreMean =平均(分数)
scoreMean = 0.4224
ヒストグラムでスコアを可視化します。
图直方图(分数)“蓝色分数”) ylabel (“频率”)

アテンション関数
関数注意は,Bahdanauアテンションを使用してコンテキストベクトルとアテンションの重みを計算します。
函数[contextVector, attentionWeights] =注意(隐藏,特征,weights1,...bias1、weights2 bias2、weightsV biasV)模型尺寸。[embeddingDimension,numFeatures,miniBatchSize] = size(features);numHiddenUnits = size(weights1,1);%完全连接。Y1 =重塑(features,embeddingDimension, numFeatures*miniBatchSize);Y1 = fulllyconnect (Y1,weights1,bias1,DataFormat=“CB”);Y1 =重塑(Y1,numHiddenUnits,numFeatures,miniBatchSize);%完全连接。Y2 = fulllyconnect (hidden,weights2,bias2,DataFormat=“CB”);Y2 =重塑(Y2,numHiddenUnits,1,miniBatchSize);%加法,tanh。scores = tanh(Y1 + Y2);scores =重塑(scores, numHiddenUnits, numFeatures*miniBatchSize);%完全连接,softmax。attentionWeights = fulllyconnect (scores,weightsV,biasV,DataFormat=“CB”);注意重量=重塑(注意重量,1,numFeatures,miniBatchSize);attentionWeights = softmax(attentionWeights,DataFormat=“渣打银行”);%的上下文。contextVector = attentionWeights .* features;contextVector = squeeze(sum(contextVector,2));结束
埋め込み関数
関数嵌入は,。
函数Z =嵌入(X,权重)将输入重塑为向量[N, T] = size(X, 1:2);X =重塑(X, N*T, 1);嵌入矩阵的索引Z =权重(:,X);通过分离批次和序列尺寸来重塑输出Z =重塑(Z, [], N, T);结束
特徴抽出関数
関数extractImageFeaturesは,学習済みのdlnetworkオブジェクト,入力イメージ,イメージ再スケーリングの統計,および実行環境を入力として受け取り,事前学習済みのネットワークから抽出した特徴を含むdlarrayを返します。
函数X = extractImageFeatures(net,X,inputMin,inputMax,executionEnvironment)调整大小和缩放。inputSize = net.Layers(1).InputSize(1:2);X = imresize(X,inputSize);X = rescale(X,-1,1,InputMin= InputMin,InputMax= InputMax);%转换为darray。X = dlarray(X,“SSCB”);%转换为gpuArray。如果(executionEnvironment = =“汽车”&& canUseGPU) || executionEnvironment ==“图形”X = gpuArray(X);结束提取特征并重塑。X = predict(net,X);sz = size(X);numFeatures = sz(1) * sz(2);inputSizeEncoder = sz(3);miniBatchSize = sz(4);X =重塑(X,[numFeatures inputSizeEncoder miniBatchSize]);结束
バッチ作成関数
関数createBatchは,データのミニバッチ,トークン化されたキャプション,事前学習済みのネットワーク,イメージ再スケーリングの統計,単語符号化,および実行環境を入力として受け取り,学習用に抽出されたイメージの特徴とキャプションに対応するデータのミニバッチを返します。
函数[X, T] = createBatch(X,documents,net,inputMin,inputMax,enc,executionEnvironment) X = extractImageFeatures(net,X,inputMin,inputMax,executionEnvironment);将文档转换为单词索引序列。T = doc2sequence(enc,documents,PaddingDirection=“正确”, PaddingValue = enc.NumWords + 1);T = cat(1,T{:});将小批量数据转换为大数组。T = dlarray(T);如果在GPU上训练,则将数据转换为gpuArray。如果(executionEnvironment = =“汽车”&& canUseGPU) || executionEnvironment ==“图形”T = gpuArray(T);结束结束
符号化器モデル関数
関数modelEncoderは,活性化の配列Xを入力として受け取り,全結合演算とReLU演算に渡します。全結合演算は,チャネル次元だけに対して操作を行います。チャネル次元にのみ全結合演算を適用するには,他のチャネルを単一の次元にフラット化し,関数fullyconnectのDataFormatオプションを用いてこの次元をバッチ次元として指定します。
函数Y = modelEncoder(X,parametersEncoder) [numFeatures,inputSizeEncoder,miniBatchSize] = size(X);%完全连接weights = parametersencode .fc. weights;bias = parametersencode .fc. bias;embeddingDimension = size(weights,1);X = permute(X,[2 1 3]);X =重塑(X,inputSizeEncoder,numFeatures*miniBatchSize);Y = fulllyconnect (X,权重,偏差,DataFormat=“CB”);Y =重塑(Y,embeddingDimension,numFeatures,miniBatchSize);% ReLUY = relu(Y);结束
復号化器モデル関数
関数modelDecoderは,単一タX,復号化器モデルパラメーター,符号化器からの特徴,およびネットワーク状態を入力として受け取り,次のタイムステップ用の予測,更新されたネットワーク状態,およびアテンションの重みを返します。
函数[Y,state,attentionWeights] = modelDecoder(X,parametersDecoder,features,state) hiddenState = state.gru. hiddenState;%的关注weights1 = parametersDecoder.attention.Weights1;bias1 = parametersdecode .attention. bias1;weights2 = parametersDecoder.attention.Weights2;bias2 = parametersDecoder.attention.Bias2;weightsV = parametersDecoder.attention.WeightsV;biasV = parametersdecode .attention. biasV;[contextVector, attentionWeights] = attention(hiddenState,features,weights1,bias1,weights2,bias2,weightsV,biasV);%嵌入weights = parametersDecoder.emb.Weights;X =嵌入(X,权重);%连接Y = cat(1,contextVector,X);%格勒乌inputwights = parametersdecoder .gru. inputwights;recurrentwights = parametersdecoder .gru. recurrentwights;bias = parametersDecoder.gru.Bias;[Y, hiddenState] = gru(Y, hiddenState, inputwights, recurrentwights, bias, DataFormat=“认知行为治疗”);%更新状态state.gru.HiddenState =隐藏状态;%完全连接weights = parametersDecoder.fc1.Weights;bias = parametersDecoder.fc1.Bias;Y = fulllyconnect (Y,权重,偏差,DataFormat=“CB”);%完全连接weights = parametersDecoder.fc2.Weights;bias = parametersDecoder.fc2.Bias;Y = fulllyconnect (Y,权重,偏差,DataFormat=“CB”);结束
モデルの損失
関数modelLossは,符号化器と復号化器のパラメ,タ,符号化器の特徴X,およびタ,ゲットのキャプションTを入力として受け取り,損失,その損失についての符号化器と復号化器のパラメーターの勾配,および予測を返します。
函数(损失、gradientsEncoder gradientsDecoder YPred] =...modelLoss(parametersEncoder,parametersDecoder,X,T) miniBatchSize = size(X,3);sequenceLength = size(T,2) - 1;vocabSize = size(parametersDecoder.emb.Weights,2);型号编码器features = modelEncoder(X,parametersEncoder);初始化状态numHiddenUnits = size(parametersDecoder.attention.Weights1,1);State = struct;state.gru.HiddenState = dlarray(0 ([numHiddenUnits miniBatchSize],“单身”));YPred = dlarray(0 ([vocabSize miniBatchSize sequenceLength],“喜欢”, X));损失= dlarray(single(0));padToken = vocabSize;为t = 1:sequenceLength decoderInput = t (:,t);YReal = T(:, T +1);[YPred(:,:,t),state] = modelDecoder(decoderInput,parametersDecoder,features,state);mask = YReal ~= padToken;loss = loss + sparseCrossEntropyAndSoftmax(YPred(:,:,t),YReal,mask);结束计算梯度[gradientsEncoder,gradientsDecoder] = dlgradient(loss, parametersEncoder,parametersDecoder);结束
スパ,スな交差エントロピ,およびソフトマックス損失関数
関数sparseCrossEntropyAndSoftmaxは,予測Y,対応するタ,ゲットT,およびシ,ケンスパディングマスクを入力として受け取り,関数softmaxを適用して交差エントロピ,損失を返します。
函数loss = sparseCrossEntropyAndSoftmax(Y, T, mask) miniBatchSize = size(Y, 2);% Softmax。Y = softmax(Y,DataFormat=“CB”);查找与目标单词对应的行。idx = sub2ind(size(Y), T', 1:miniBatchSize);Y = Y(idx);%远离0。Y = max(Y, single(1e-8));%掩码损失。loss = log(Y) .* mask';损失= -sum(损失,“所有”) ./ miniBatchSize;结束
ビ,ムサ,チ関数
関数beamSearchは,X,ビームインデックス,符号化器ネットワークおよび復号化器ネットワークのパラメーター,単語符号化,および最大シーケンス長を入力として受け取り,ビームサーチアルゴリズムを使用してイメージのキャプション用の単語を返します。
函数[words,attentionScores] = beamSearch(X,beamIndex,parametersEncoder,parametersDecoder,...enc, maxNumWords)%模型尺寸numFeatures = size(X,1);numHiddenUnits = size(parametersDecoder.attention.Weights1,1);提取特征features = modelEncoder(X,parametersEncoder);初始化状态State = struct;state.gru.HiddenState = dlarray(0 ([numHiddenUnits 1],“喜欢”, X));初始化候选候选人= struct;候选人。状态=状态;候选人。话说=“<开始>”;候选人。得分= 0;候选人。注意分数= dlarray(零([numFeatures maxNumWords],“喜欢”, X));候选人。StopFlag= false; t = 0;%循环单词而t < maxNumWords t = t + 1;candidatesNew = [];%遍历候选人为I = 1:数字(候选人)当预测到停止令牌时停止生成如果候选人(i)。StopFlag继续结束%候选人详细信息状态=候选人(i).状态;words =考生(i).Words;分数=考生(i).分数;注意分数=考生(i).注意分数;%预测下一个令牌decoderInput = word2ind(enc,words(end));[YPred,state,attentionScores(:,t)] = modelDecoder(decoderInput,parametersDecoder,features,state);YPred = softmax(YPred,DataFormat=“CB”);[scoresTop,idxTop] = maxk(extractdata(YPred),beamIndex);idxTop = gather(idxTop);循环顶部的预测为j = 1:beamIndex candidate = struct;candidateWord = ind2word(enc,idxTop(j));candidateScore = scoresTop(j);如果candidateWord = =“<停止>”候选人。StopFlag= true; attentionScores(:,t+1:end) = [];其他的候选人。StopFlag= false;结束候选人。状态=状态;候选人。话说=[words candidateWord]; candidate.Score = score + log(candidateScore); candidate.AttentionScores = attentionScores; candidatesNew = [candidatesNew candidate];结束结束%寻找最佳候选人[~,idx] = maxk([candidatesNew.Score],beamIndex);候选人=候选人新(idx);当所有候选对象都有停止令牌时停止预测如果([candidates.StopFlag])打破结束结束%找到最佳候选人words = candidate (1).Words(2:end-1);attentionScores =考生(1).AttentionScores;结束
葛洛特重み初期化関数
関数initializeGlorotは,格洛洛特の初期化に従って,重みの配列を生成します。
函数weights = initializeGlorot(numOut, numIn) varWeights = sqrt(6 / (numIn + numOut));权重= varWeights * (2 * rand([numOut, numIn],“单身”) - 1);结束
参考
word2ind(文本分析工具箱)|tokenizedDocument(文本分析工具箱)|wordEncoding(文本分析工具箱)|dlarray|adamupdate|dlupdate|dlfeval|dlgradient|crossentropy|softmax|lstm|doc2sequence(文本分析工具箱)|格勒乌
関連するトピック
您也可以从以下列表中选择一个网站: