基于DDPG Agent的四足机器人运动
这个例子展示了如何使用深度确定性策略梯度(deep deterministic policy gradient, DDPG) agent训练四足机器人行走。本例中的机器人使用Simscape™Multibody™建模。有关DDPG代理的更多信息,请参见双延迟深度确定性策略梯度代理.
将必要的参数加载到MATLAB®的基本工作空间中。
initializeRobotParameters
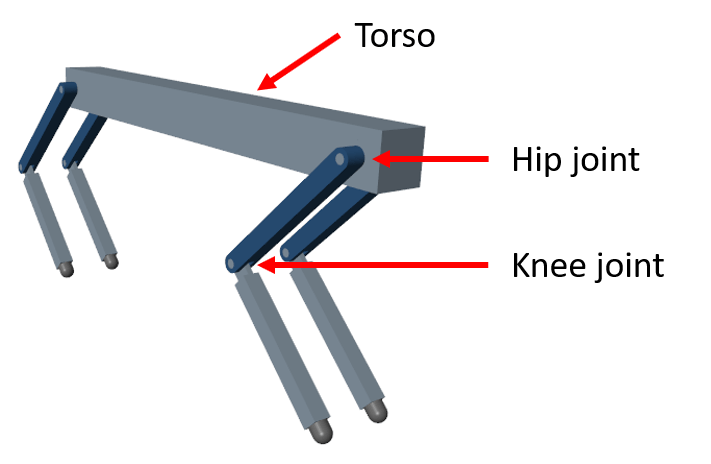
四足机器人模型
本例的环境是一个四足机器人,训练目标是使机器人以最小的控制努力沿直线行走。
该机器人采用Simscape多体模型和Simscape多体接触力库.主要结构部件是四条腿和一个躯干。腿通过转动关节与躯干相连。RL Agent块提供的动作值被缩放并转换为关节扭矩值。这些关节转矩值被转动关节用来计算运动。
打开模型。
mdl=“rlQuadrupedRobot”;open_system (mdl)
警告:无法识别的函数或变量'CloneDetectionUI.internal.CloneDetectionPerspective.register'。

观察
机器人环境向代理提供了44个观测值,每个观测值在–1和1之间标准化。这些观测值是:
躯干重心的Y(垂直)和Z(横向)位置
表示躯干方向的四元数
重心处躯干的X(向前)、Y(垂直)和Z(横向)速度
躯干的滚转,俯仰和偏航率
每条腿髋关节和膝关节的角度位置和速度
每条腿接触地面时的法向力和摩擦力
上一时间步的动作值(每个关节的扭矩)
对于所有四条腿,髋关节和膝关节角度的初始值分别设置为-0.8234和1.6468 rad。关节的中立位置为0 rad。当腿伸展到最大时,腿处于中立位置,并与地面垂直对齐。
行动
代理生成八个在-1和1之间标准化的动作。乘以比例因子后,这些动作对应于旋转关节的八个关节扭矩信号。每个关节的总关节扭矩界限为+/-10 N·m。
奖励
在培训期间的每个时间步骤,都会向代理提供以下奖励。此奖励功能通过为正向前进速度提供正向奖励来鼓励代理向前移动。它还鼓励代理人通过提供持续的奖励来避免提前终止合同( )在每个时间步。奖励函数中的剩余项是阻止不必要状态的惩罚,例如与所需高度和方向的较大偏差或使用过大的关节扭矩。
哪里
是躯干重心在x方向上的速度。
和 分别是环境的采样时间和最终模拟时间。
为躯干质心从0.75米期望高度的比例高度误差。
是躯干的俯仰角度。
是关节的动作值 从上一时间步开始。
情节终止
在训练或模拟过程中,如果出现以下任何情况,则该情节终止。
躯干重心离地面的高度低于0.5 m(下降)。
躯干的头部或尾部低于地面。
任何膝关节都在地面以下。
滚转、俯仰或偏航角在边界外(分别为+/ - 0.1745、+/ - 0.1745和+/ - 0.3491 rad)。
创建环境接口
指定观测集的参数。
numObs=44;obsInfo=rlNumericSpec([numObs 1]);obsInfo.Name=“观察”;
指定操作集的参数。
numAct=8;actInfo=rlNumericSpec([numact1],“LowerLimit”, 1“上限”1);actInfo。Name =“扭矩”;
使用强化学习模型创建环境。
黑色= [mdl,“/RL代理”]; 环境=rlSim万博1manbetxulinkEnv(mdl、blk、obsInfo、actInfo);
在训练期间,重置功能会将随机偏差引入初始关节角度和角速度。
env。ResetFcn = @quadrupedResetFcn;
创建DDPG代理
DDPG代理使用评判值函数表示法近似给定观察和行动的长期回报。代理还使用参与者表示法确定给定观察采取的行动。本例中的参与者和评论家网络受[2]启发。
有关创建深度神经网络值函数表示的更多信息,请参见创建策略和值函数表示.有关为DDPG代理创建神经网络的示例,请参见培训DDPG代理控制双积分系统.
在MATLAB工作空间中创建网络使用创建网络辅助函数。
创建网络
您还可以使用深层网络设计师应用程序。
查看网络配置。
绘图(关键网络)

使用指定代理选项rlDDPGAgentOptions.
agentOptions = rlDDPGAgentOptions;agentOptions。SampleTime = t;agentOptions。DiscountFactor = 0.99;agentOptions。MiniBatchSize = 250;agentOptions。ExperienceBufferLength = 1 e6;agentOptions。TargetSmoothFactor = 1e-3; agentOptions.NoiseOptions.MeanAttractionConstant = 0.15; agentOptions.NoiseOptions.Variance = 0.1;
创建RLDDPG试剂代理的对象。
代理=rlDDPGAgent(演员、评论家、代理);
指定培训选项
要培训代理,首先指定以下培训选项:
每一集最多10000集,每一集最多持续时间
maxSteps时间步长。在“事件管理器”对话框中显示培训进度(设置
阴谋选项)并禁用命令行显示(设置详细的选项)。当代理在250个连续事件中收到超过190个平均累积奖励时,停止训练。
当累计奖励超过200时,为每一集保存一份代理。
maxEpisodes = 10000;maxSteps =地板(Tf / Ts);trainOpts = rlTrainingOptions (...“MaxEpisodes”,每集,...“MaxStepsPerEpisode”maxSteps,...“ScoreAveragingWindowLength”, 250,...“详细”符合事实的...“情节”,“培训进度”,...“停止培训标准”,“AverageReward”,...“StopTrainingValue”,190,...“SaveAgentCriteria”,“情节报酬”,...“SaveAgentValue”,200);
要并行地培训代理,请指定以下培训选项。并行培训需要并行计算工具箱™软件。如果您没有安装并行计算工具箱™软件,请设置UseParallel到错误的.
设定
UseParallel选择t后悔.异步并行训练代理。
每走32步后,每个工作者将经验发送给主机。
DDPG代理要求工人发送
“经验”给主人。
trainOpts.UseParallel=true;trainOpts.ParallelizationOptions.Mode=“异步”;trainOpts.ParallelizationOptions.StepsUntilDataIsSent=32;trainOpts.ParallelizationOptions.DataToSendFromWorkers=“经验”;
列车员
使用火车函数。由于机器人模型的复杂性,此过程计算量大,需要几个小时才能完成。为了在运行此示例时节省时间,请通过设置溺爱到错误的.自己训练代理人,设置溺爱到真正的.由于并行训练的随机性,您可以从下图中看到不同的训练结果。
doTraining=false;如果溺爱%培训代理人。trainingStats =火车(代理,env, trainOpts);其他的%为示例加载预训练的代理。装载(“rlQuadrupedAgent.mat”,“代理人”)终止

模拟训练的代理
修复随机生成器种子的再现性。
rng(0)
要验证经过训练的agent的性能,请在robot环境中对其进行模拟。有关agent模拟的更多信息,请参阅模拟选项和模拟.
simOptions=rlSimulationOptions(“MaxSteps”, maxSteps);经验= sim (env,代理,simOptions);

关于如何训练一个DDPG代理行走一个两足机器人和模拟Simscape™多体™的类人步行者的例子,请参见使用强化学习代理训练两足机器人行走和训练类人助行器(Simscape多体)分别地
工具书类
[1] Heess、Nicolas、Dhruva TB、Srinivasan Sriram、Jay Lemmon、Josh Merel、Greg Wayne、Yuval Tassa等,“丰富环境中运动行为的出现”。ArXiv:1707.02286[Cs]2017年7月10日。https://arxiv.org/abs/1707.02286.
Lillicrap, Timothy P, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver和Daan Wierstra。“深度强化学习的连续控制”。ArXiv:1509.02971[Cs,Stat],2019年7月5日。https://arxiv.org/abs/1509.02971.
另见
相关话题
相关话题
你也可以从以下列表中选择一个网站: