このページの翻訳は最新ではありません。ここをクリックして,英語の最新版を参照してください。
FeatureSelectionNCARegressionクラス
近傍成分分析(NCA)を使用する回帰用の特徴選択
説明
FeatureSelectionNCARegressionオブジェクトには,近傍成分分析(NCA)モデルのデータ,あてはめの情報,特徴量の重み,その他のモデルパラメーターが格納されます。fsrncaは,NCAを対角的に適用して特徴量の重みを学習し,FeatureSelectionNCARegressionオブジェクトのインスタンスを返します。この関数は,特徴量の重みを正則化することにより特徴選択を実現します。
構築
FeatureSelectionNCAClassificationオブジェクトを作成するには,fsrncaを使用します。
プロパティ
例
FeatureSelectionNCARegressionオブジェクトの調査
標本データを読み込みます。
负载进口- 85
最初の15列には連続予測子変数が,16列目には応答変数(自動車の価格)が含まれています。近傍成分分析モデル用の変数を定義します。
预测= X (: 1:15);Y = X (: 16);
回帰用の近傍成分分析(NCA)モデルをあてはめて,関連する特徴量を判別します。
mdl = fsrnca(预测,Y);
返されたNCAモデルmdlはFeatureSelectionNCARegressionオブジェクトです。このオブジェクトには,学習データ,モデルおよび最適化に関する情報が格納されています。このオブジェクトのプロパティ(特徴量の重みなど)には,ドット表記を使用してアクセスできます。
特徴量の重みをプロットします。
图()图(mdl。FeatureWeights,“罗”)包含(“功能指数”) ylabel (“功能重量”网格)在
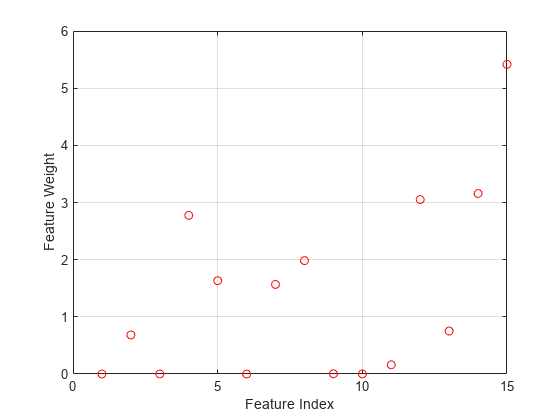
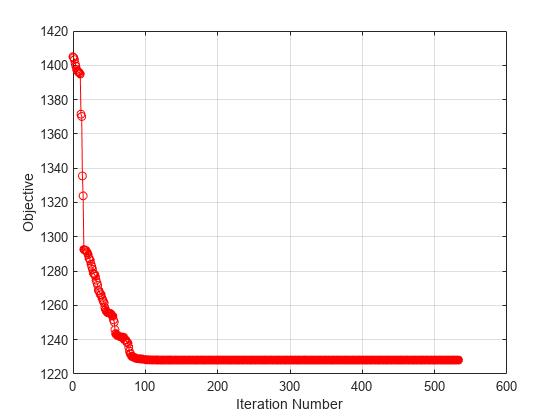
無関係な特徴量の重みはゼロになります。fsrncaを呼び出すときに“详细”,1オプションを指定すると,最適化の情報がコマンドラインに表示されます。目的関数と反復回数をプロットして最適化プロセスを可視化することもできます。
图()图(mdl.FitInfo.Iteration mdl.FitInfo.Objective,“ro - - - - - -”网格)在包含(的迭代次数) ylabel (“目标”)
ModelParametersプロパティは,モデルに関する詳細情報が含まれている结构体です。このプロパティのフィールドには,ドット表記を使用してアクセスできます。たとえば,データが標準化されているかどうかを調べます。
mdl.ModelParameters.Standardize
ans =逻辑0
0は,NCAモデルをあてはめる前にデータが標準化されていないことを意味します。各予測子のスケールが非常に異なる場合は,fsrncaを呼び出すときに名前と値のペアの引数“标准化”,1を使用して予測子を標準化することができます。
コピーのセマンティクス
値。値のクラスがコピー操作に与える影響については,オブジェクトのコピーを参照してください。
你也可以从以下列表中选择一个网站:
