このページの翻訳は最新ではありません。ここをクリックして,英語の最新版を参照してください。
ランダムフォレストの予測子の選択
この例では,回帰木のランダムフォレストを成長させるときに,データセットに適した分割予測子選択手法を選択する方法を示します。また,学習データに含める最も重要な予測子を決定する方法も示します。
データの読み込みと前処理
carbig与えられを読み込みます。气缸、model_year.および起源はカテゴリカル変数であるとします。
负载carbig汽缸=分类(气缸);model_year =分类(model_year);来源=分类(Cellstr(origin));X =表(圆柱,位移,马力,重量,加速,型号,原点);
予測子内のレベルの測定
標準购物车アルゴリズムには,一意な値(レベル)が少ない予測子(カテゴリカル変数など)よりも,多数のレベルをもつ予測子(連続変数など)を分割する傾向があります。データが異種混合である場合,または予測子変数間でレベルの数が大きく異なる場合は,標準购物车ではなく曲率検定または交互作用検定を分割予測子選択に使用することを検討してください。
各各のレベルのをします,データを行ます。
分类を使用してすべての変数をカテゴリカルデータ型に変換する类别を使用してすべての一意なカテゴリを決定し,欠損値は無視する元素个数を使用してカテゴリの個数を数える
次に,varfunを使用してこの関数を各変数に適用します。
countLevels = @ (x)元素个数(类别(类别(x)));numLevels = varfun (countLevels X,“OutputFormat”,“统一”);
予測子変数間でレベルの数を比較します。
图酒吧(numLevels)标题(“预测因子之间的水平数量”)Xlabel('predictor变量')ylabel(的层数) h = gca;h.xticklabel = x.properties.variablenames(1:结束-1);h.XTickLabelRotation = 45;h.TickLabelInterpreter =“没有”;

連続変数には,カテゴリカル変数より多くのレベルがあります。レベル数は予測子によって大きく異なるので,標準购物车を使用してランダムフォレストの木の各ノードで分割予測子を選択すると,予測子の重要度の推定が不正確になる可能性があります。このようなケースでは,曲率検定または交互作用検定を使用します。アルゴリズムを指定するには,名前と値のペアの引数“PredictorSelection”を使用します。詳細は,分享予测子选択选択选択の选択を参照してください。
回帰木回帰木のバギングアンサンブルアンサンブルにに习をさ
バギングされた200本の回帰木のアンサンブルに学習をさせて,予測子の重要度の値を推定します。以下の名前と値のペアの引数を使用して,木学習器を定義します。
“NumVariablesToSample”、“所有”——すべての予測子変数が各木で使用されることを保証するため,すべての予測子変数を各ノードで使用します。'预测圈','互动曲率'- 交互作用検定検定指定予测ますするよう指定ますますてよう指定します。“代孕”,“上”——データセットに欠損値が含まれているので,精度を高めるために代理分岐を使用するよう指定します。
t = templatetree(“NumVariablesToSample”,“所有”,...“PredictorSelection”,“interaction-curvature”,“代孕”,“上”);rng (1);再现性的百分比Mdl = fitrensemble (X,英里/加仑,“方法”,'包',“NumLearningCycles”, 200,...“学习者”t);
MDL.は回归释迦缩短モデルです。
out-of-bag予測を使用して のモデルを推定します。
yhat = Oobpredict(MDL);r2 = corr(mdl.y,yhat)^ 2
R2 = 0.8744
MDL.は,平均の周辺で変動性の87%を説明します。
予測子の重要度の推定
木同士で出球袋観测値の顺序を変更することにより,予测子の重要度の値を推定します。
Impoob = OobperMutedPredictorimportance(MDL);
impOOBは予测子の重要度推定が格式さている1行7列のでで,mdl.predictornames.内の予測子に対応しています。この推定は,多くのレベルが含まれている予測子に偏ってはいません。
予測子の重要度の推定を比較します。
图酒吧(impOOB)标题(“无偏见预测重点估计”)Xlabel('predictor变量')ylabel(“重要性”) h = gca;h.XTickLabel = Mdl.PredictorNames;h.XTickLabelRotation = 45;h.TickLabelInterpreter =“没有”;

重要度の推定値が大きいほど重要な予測子です。棒グラフは,最も重要な予測子がmodel_year.であり,次に重要なのは气缸と重量であることを示しています。変数model_year.および气缸の異なるレベルはそれぞれ13個および5個ですが,変数重量300年には個以上のレベルがあります。
out-of-bag観測値およびそれらの推定の順序を変更して予測子の重要度の推定を比較します。推定は,各予測子の分割による平均二乗誤差のゲインを合計して得られます。また,代理分岐によって推定した予測子の関連尺度を取得します。
[impGain, predAssociation] = predictorImportance (Mdl);图1:numel(Mdl.PredictorNames),[impOOB' impGain']“预测因子重要性估计比较”)Xlabel('predictor变量')ylabel(“重要性”) h = gca;h.XTickLabel = Mdl.PredictorNames;h.XTickLabelRotation = 45;h.TickLabelInterpreter =“没有”;传奇(“OOB排列的,“MSE改进”网格)在
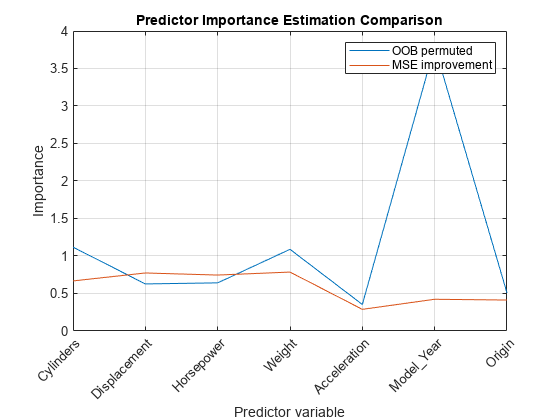
冒险の値値,幂数位移、马力および重量は同じように重要であるようです。
挖掘は予測子の関連尺度が格納されている7行7列の行列です。行と列はmdl.predictornames.の予測子に対応します。关键词予测は,観測値を分割する決定規則間の類似度を示す値です。最適な代理決定分岐は関連性予測尺度が最大になります。挖掘の要素を使用すると,予測子のペア間における関連性の強さを推定できます。値が大きいほど予測子のペアの関連性が高くなります。
图ImageC(Predassociation)标题('预测者协会估计') colorbar h = gca;h.XTickLabel = Mdl.PredictorNames;h.XTickLabelRotation = 45;h.TickLabelInterpreter =“没有”;h.YTickLabel = Mdl.PredictorNames;
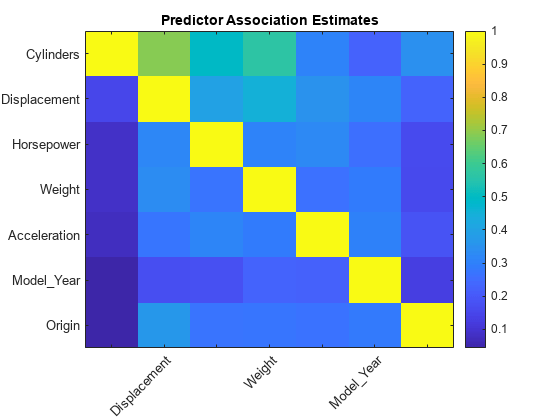
predAssociation(1、2)
ans = 0.6871
最大の関連は气缸と位移の間にありますが2つの予測子の間に強い関係があることを示すほど大きい値ではありません。
缩小したた子セットの使使使によるフォレストの成
ランダムフォレスト内の予測子数が増えると予測時間が長くなるので,可能な限り少ない個数の予測子を使用してモデルを作成することが推奨されます。
最良の2つの予測子のみを使用して,200本の回帰木が含まれているランダムフォレストを成長させます。templateTreeの“NumVariablesToSample”の既定値は,回帰の場合は予測子の個数の1/3なので,fitrensemble.はランダムフォレストアルゴリズムアルゴリズム使使。
t = templatetree(“PredictorSelection”,“interaction-curvature”,“代孕”,“上”,...“复制”,真正的);%用于随机预测器选择的重现性MdlReduced = fitrensemble (X (: {'model_year'“重量”}),英里/加仑,“方法”,'包',...“NumLearningCycles”, 200,“学习者”t);
縮小したモデルの を計算します。
yhatreduced = Oobpredict(mdlReduce);R2R2RDURED = COR(MDL.Y,Yhatreduce)^ 2
r2Reduced = 0.8653
縮小したモデルの は完全なモデルの に近くなっています。この結果は,縮小したモデルが予測に十分であることを示しています。
参考
templateTree|fitrensemble.|oobPredict|oobPermutedPredictorImportance|predictorImportance|corr
関連するトピック
您还可以从以下列表中选择一个网站:
