深度学习HDL工具箱可从MATLAB内部提供深度学习推断的FPGA原型,因此您可以快速迭代并收敛于在满足FPGA约束时为您的系统需求提供性能的网络。
但是,如果您想自定义FPGA实施,以提高性能或定制自定义板怎么办?为此,您可以使用MATLAB配置处理器并驱动HDL编码器以生成带有RTL和AXI接口的IP核心。
这一切都是基于具有通用卷积和完全连接的模块的深度学习处理器体系结构,因此您可以对自定义网络进行编程以及控制正在运行哪个图层的逻辑以及其激活输入和输出。由于每个层的参数需要存储在外部DDR内存中,因此处理器还包括高带宽内存访问。
您可以根据您的系统需求自定义此深度学习处理器,再加上自定义深度学习网络的能力,提供了许多选项,以优化应用程序的FPGA实现。
为了说明,让我们看一个应用程序,该应用程序使用经过训练以对徽标进行分类的系列网络。假设我们需要每秒处理15帧。
因此,我们只是加载训练有素的网络。
我们将设置一个具有所有默认设置的自定义处理器配置,并以220 MHz运行。注意卷积模块和完全连接模块的数据类型和平行线程的数量。默认情况下,这是针对ZCU102板的设置,这是我们正在使用的。
然后,我们将处理器配置应用于受过训练的网络的工作流对象
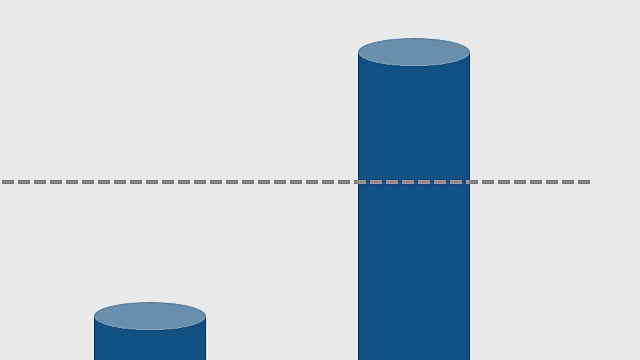
现在,我们可以在部署该自定义处理器之前估算该自定义处理器的性能。结果是这里的总延迟,该延迟为220 MHz意味着帧速率每秒不到6帧,这将无法满足我们的系统要求。
在这里,协作很重要,因为我们有选择。假设我们致力于该委员会。而且,我们的深度学习专家认为我们无法删除任何层并获得相同的准确性,但是我们也许可以量化INT8。从32位到8位单词长度使我们能够并行执行更多乘务。
因此,我们将设置一个新的自定义处理器配置对象,并将卷积和完全连接的层设置为INT8,并将平行线程计数增加4倍。
现在,我们需要量化网络本身,以估算其在深度学习处理器上的性能。您可以在文档中了解有关此过程的更多信息。运行需要一分钟,并为给定校准数据存储的数字范围返回。通常,我们会运行更多的校准图像,然后用另一组验证,但是…
让我们看看这种新处理器配置的估计结果 - 现在我们每秒最多可达16帧,这足以满足我们的虚构要求。
从这里开始,buildProcessor函数将完成其余的工作。它调用HDL编码器为您配置的处理器生成无独立的合成RTL。而且,如果您已经设置了参考设计,它将生成带有AXI寄存器映射的IP核心,因此它可以直接插入实现。而且,如果您已经设置并定义了实现工作流程,则它将一直通过生成bitstream来编程设备。
我们可以查看在Vivado的实现结果。我们将在220 MHz目标上遇到时间安排,此处显示了资源使用情况。
这表明,在深度学习网络的设计与深度学习处理器的实现之间以及在MATLAB中进行的操作有多容易。