fcm
模糊c均值聚类
描述
例子
使用模糊c均值聚类聚类数据
加载数据。
负载fcmdata.dat
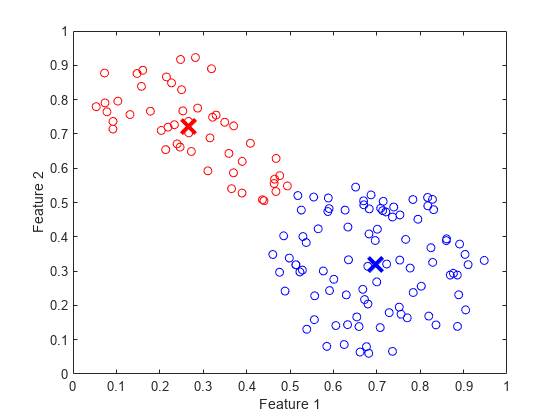
找到2使用模糊c均值聚类。
(中心、U) = fcm (fcmdata, 2);
迭代计数= 1,obj。fcn = 8.970479 Iteration count = 2, obj. fcn = 8.970479fcn迭代数= 3 = 7.197402,obj。fcn = 6.325579 Iteration count = 4, obj. php . php . php . php . php . php . php。fcn = 4.586142迭代计数= 5,obj。fcn = 3.893114;fcn = 3.810804 Iteration count = 7, obj. log(迭代次数)fcn = 3.799801迭代计数= 8,obj。fcn = 3.797862 Iteration count = 9, obj. fcn = 3.797862fcn = 3.797508 Iteration count = 10, obj. fcn = 3.797508 fcn = 3.797444 Iteration count = 11, obj. fcn = 3.797432 Iteration count = 12, obj. fcn = 3.797430
将每个数据点分类到隶属度最大的聚类中。
maxU = max (U);index1 = find(U(1,:) == maxU);index2 = find(U(2,:) == maxU);
绘制集群数据和集群中心。
情节(fcmdata (index1, 1), fcmdata (index1, 2),“ob”)举行在情节(fcmdata (index2, 1), fcmdata (index2, 2),”或“)情节(中心(1,1),中心(1、2),“xb”,“MarkerSize”15岁的“线宽”3)图(中心(2,1),中心(2,2),“xr”,“MarkerSize”15岁的“线宽”, 3)从
指定集群之间的模糊重叠
创建一个随机数据集。
data =兰德(100 2);
为了增加聚类之间的模糊重叠,指定一个较大的模糊划分矩阵指数。
options = [3.0 NaN NaN 0];
集群的数据。
(中心、U) = fcm(数据、2选项);
配置集群终止条件
加载集群数据。
负载clusterdemo.dat
设置集群终止条件,当出现以下任一情况时,优化停止:
迭代次数达到最大值
25.目标函数改进小于
0.001在两个连续迭代之间。
options = [NaN 25 0.001 0];
第一种选择是南,将模糊划分矩阵指数设置为其默认值2.将第四个选项设置为0抑制目标函数显示。
集群的数据。
(中心、U objFun) = fcm (clusterdemo 3选项);
要确定哪个终止条件停止了聚类,请查看目标函数向量。
objFun
objFun =13×154.7257 42.9867 42.8554 42.1857 39.0857 31.6814 28.5736 27.1806 20.7359 15.7147⋮
优化停止,因为目标函数改进小于0.001在最后两次迭代之间。
输入参数
输出参数
提示
使用FCM聚类生成一个模糊推理系统,使用
genfis命令。例如,假设您使用以下语法对数据进行集群:(中心、U) = fcm(数据、数控选项);
第一个
米列数据对应输入变量,其余列对应输出变量。您可以使用相同的训练数据和FCM聚类配置生成一个模糊系统。这样做:
配置集群选项。
选择= genfisOptions (“FCMClustering”);opt.NumClusters =数控;opt.Exponent =选项(1);opt.MaxNumIteration =选项(2);opt.MinImprovement =选项(3);opt.Verbose =选项(4);提取输入和输出变量数据。
inputData =数据(:,1:M);outputData =数据(:,M + 1:结束);
生成FIS结构。
fis = genfis (inputData outputData,选择);
模糊系统,
金融中间人,每个聚类包含一个模糊规则,每个输入和输出变量每个聚类有一个隶属函数。有关更多信息,请参见genfis和genfisOptions.
算法
模糊c均值(FCM)是一种聚类方法,它允许每个数据点属于多个不同隶属度的聚类。
FCM基于以下目标函数的最小化
在哪里
D为数据点的个数。
N为集群的数量。
米控制模糊重叠度的模糊划分矩阵指数,用米> 1.模糊重叠是指聚类之间的边界有多模糊,即在多个聚类中具有重要成员关系的数据点的数量。
x我是我数据点。
cj中心是什么j集群。
μij是会员的程度吗x我在j集群。对于给定的数据点,x我,则所有集群的成员关系值之和为1。
fcm集群化过程中执行如下步骤:
随机初始化集群成员的值,μij.
计算集群中心:
更新μij根据以下几点:
计算目标函数,J米.
重复步骤2-4直到J米改进小于指定的最小阈值或直到指定的最大迭代次数之后。
参考文献
[1] Bezdek,李鸿源基于模糊目标函数的模式识别算法,全会出版社,纽约,1981年。
你也可以从以下列表中选择一个网站:
