2型模糊推理系统
宇宙中的任何值的话语,一个传统的1型隶属函数只有一个成员的价值。因此,1型隶属函数模型的隶属程度在一个给定的语言,它不隶属程度的不确定性模型。这种不确定性模型,您可以使用间隔2型隶属度函数。在这样的2型隶属度函数,成员的程度可以有一系列的值。
对于使用2型模糊推理系统的示例,请参阅模糊PID控制与2型金融中间人和使用2型FIS预测混沌时间序列。
间隔2型隶属度函数
间隔2型隶属函数被定义为一个上下隶属函数。上隶属函数(UMF)相当于传统的1型隶属函数。较低的隶属函数(LMF)是小于或等于上隶属函数对所有可能的输入值。UMF和LMF之间的地区不确定性的足迹(4)。下图显示了UMF(红色),LMF的(蓝色),和笨人(阴影)2型三角隶属函数。
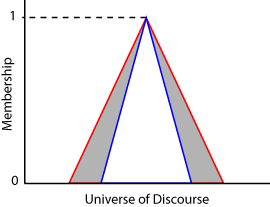
为每个输入值在论域,隶属程度是值的范围之间的LMF和UMF值。
2型模糊推理系统
使用模糊逻辑工具箱™软件,您可以创建和2型Mamdani Sugeno模糊推理系统。
在2型Mamdani系统中,输入和输出隶属度函数都是2型模糊集。
在2型Sugeno系统中,只有输入隶属函数是二型模糊集。输出隶属度函数是一样的- 1型Sugeno系统常数或一个线性函数的输入值。
创建2型Mamdani和Sugeno系统在命令行中,使用mamfistype2和sugfistype2对象,分别。这些对象有相同的参数为1型mamfis和sugfis还有一个额外的对象TypeReductionMethod参数。
您可以创建一个2型模糊推理系统通过将现有的1型系统,如使用创建的genfis函数。为此,使用convertToType2函数。
一旦你创建一个2型模糊推理系统,您可以:
您还可以创建2型模糊推理系统使用模糊逻辑设计应用程序。
二型模糊系统的模糊推理过程
前期处理
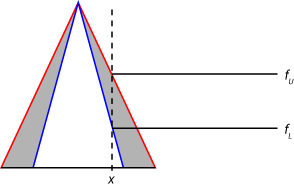
对于2型模糊推理系统,输入值被发现fuzzified umf文件的相应的隶属程度和LMFs规则前提。这样做会产生两个每个2型隶属函数的模糊值。例如,下图显示的模糊性会员价值上隶属函数(fU)和较低的隶属函数(fl)。
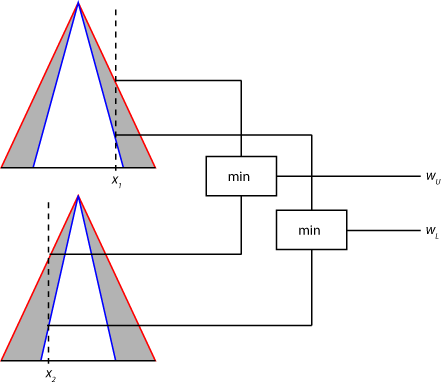
接下来,一系列规则解雇的优势是发现通过应用模糊算子的fuzzified值2型隶属度函数,如下图所示。这个范围的最大值(wU)是应用模糊算子的结果umf文件模糊值。最小值(wl)是应用模糊算子的结果从LMFs模糊值
前期处理Mamdani和Sugeno系统都是一样的。
后续处理
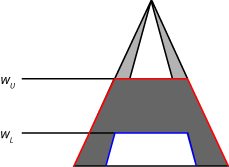
对于Mamdani系统,言下之意方法片段(最小值含义)或尺度(刺激含义)的UMF和LMF输出2型隶属函数使用规则靶场的限制。这个过程会产生一个输出模糊集对于每个规则。下图显示了输出模糊集(深灰色区域)产生的应用最小值暗示UMF(红色)和LMF(蓝色)。
2型Sugeno系统,输出水平z我为我th规则是计算在相同的方式为1型Sugeno系统。
在这里,j是输入指数,xj的价值吗jth输入变量,c术语上隶属函数参数
与1型Sugeno系统,发射的优点不习惯来处理每条规则的结果。相反,输出电平和规则发射的优点在聚合过程中使用。
聚合
聚合阶段的目标是获得一个单一的二型模糊集的规则输出模糊集。
2型Mamdani系统,软件发现一个聚合二型模糊集应用聚合方法和LMFs umf文件的输出模糊集的所有规则。下图显示了两个二型模糊集的聚合(两个规则的输出系统)使用马克斯聚合。
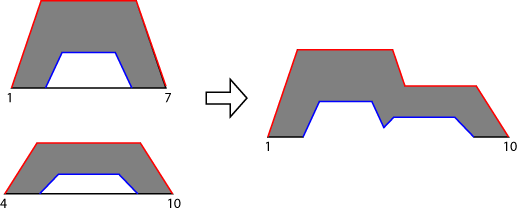
对于2型Sugeno系统,总模糊集导出使用以下步骤:
排序规则的产出水平(z我)所有的规则为升序。这些输出电平值定义为总二型模糊集论域。
对于每个输出电平,使用最大射程值定义UMF值从相应的规则。
对于每个输出电平,定义LMF价值最低靶场使用价值从相应的规则。
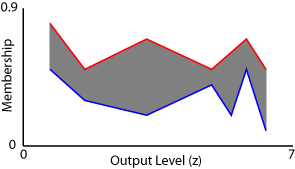
例如,假设您有一个2型Sugeno系统有七个规则。此外,假设这些规则有以下输出水平和靶场的限制。
| 规则 | 输出电平(z) | 最小发射值 | 最大发射值 |
|---|---|---|---|
| 1 | 6.3 | 0.1 | 0.5 |
| 2 | 4.9 | 0.4 | 0.5 |
| 3 | 1.6 | 0.3 | 0.5 |
| 4 | 5.8 | 0.5 | 0.7 |
| 5 | 5.4 | 0.2 | 0.6 |
| 6 | 0.7 | 0.5 | 0.8 |
| 7 | 3.2 | 0.2 | 0.7 |
下图显示了这个Sugeno聚合二型模糊集系统及其相关UMF(红色)和LMF(蓝色)。
减少类型和去模糊化
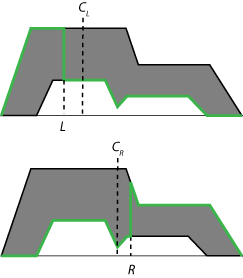
找到最后的输出值的推理过程,首先减少到一个聚合二型模糊集间隔1型模糊集,这是一个较低的范围限制cl和上限cR。这个区间1型模糊集通常被称为二型模糊集的重心。在理论上,这重心质心的平均值的1型模糊集嵌入到2型模糊集。在实践中,不可能计算的精确值cl和cR。相反,使用迭代type-reduction方法来估计这些值。
对于一个给定的总二型模糊集,近似的值cl和cR是下面的1型模糊集的质心(绿色)。
数学上,这些重心是发现使用以下方程。[1]
在这里:
N是在输出变量样本的数量范围,指定使用吗
evalfisOptions。x我是我样本输出值。
μumf是上面的隶属函数。
μlmf较低的隶属函数。
l和R是开关分估计的各种type-reduction方法。支持方法的列表,请参阅万博1manbetxType-Reduction方法。
Mamdani和Sugeno系统,最后defuzzified输出值(y)是两个质心值的平均值从还原过程类型。
Type-Reduction方法
模糊逻辑工具箱软件支持4个内置type-reduction万博1manbetx方法。这些算法的初始化方法,不同的假设,计算效率,和终止条件。
设置type-reduction二型模糊系统的方法,设置TypeReduction财产的mamfistype2或sugfistype2对象。
| 方法 | TypeReduction属性值 |
描述 |
|---|---|---|
| Karnik-Mendel(公里)[2] | “karnikmendel” |
首先type-reduction方法开发 |
| 增强Karnik-Mendel(11月)[3] | “11” |
修改Karnik-Mendel算法和一种改进的初始化,修改后的终止条件,提高了计算效率 |
| 迭代算法的停止条件(机构间常设委员会[4] | “关于” |
蛮力方法迭代改进 |
| 增强迭代算法的停止条件(EIASC)[5] | “eiasc” |
机构间常设委员会算法的改进版本 |
一般来说,这些方法的计算效率提高移动桌子。
您也可以使用自己的自定义type-reduction方法。有关更多信息,请参见建立模糊系统使用自定义函数。
引用
[1]孟德尔,杰瑞米。哈尼Hagras Woei-Wan Tan,威廉·w·米勒,郝。介绍2型模糊逻辑控制:理论和应用程序。新泽西州霍博肯:IEEE出版社,约翰威利& Sons, 2014。
[2]尼克,Nilesh N。和杰瑞·m·孟德尔。“二型模糊集的重心。”信息科学132年,没有。1 - 4(2001年2月):195 - 220。https://doi.org/10.1016/s0020 - 0255 (01) 00069 - x。
[3],d和J.M.孟德尔。“强化Karnik-Mendel算法。”IEEE模糊系统17 (2009):923 - 934。
[4]杜兰,K。、h·伯纳尔和m . Melgarejo。“改进的迭代算法计算广义区间二型模糊集的重心,“北美模糊信息处理学会年会(2008):190 - 194
[5],d和m .聂。“type-reduction算法的比较和实际实现2型模糊集和系统。”FUZZ-IEEE学报》(2011):2131 - 2138