培训双边机器人使用加强学习代理行走
此示例显示如何使用深度确定性策略梯度(DDPG)代理和双延迟深度确定性策略梯度(TD3)代理使用深度确定性策略梯度(DDPG)和双延迟的机器人来训练Biped机器人。在该示例中,您还可以比较这些培训代理的性能。该示例中的机器人在Simscape™MultiBody™中建模。
有关这些代理的更多信息,请参见深度确定性政策梯度代理和双延迟深度确定性策略梯度代理.
为了在本例中进行比较,本例在两足机器人环境下用相同的模型参数训练两个agent。该示例还将代理配置为具有以下通用设置。
Biped机器人的初始条件策略
演员和评论家的网络结构,受到[1]的启发
演员和评论家代表的选择
培训选项(样本时间,折扣系数,小批量大小,经验缓冲长度,探索噪音)
Biped机器人模型
此示例的增强学习环境是一种双倍机器人。培训目标是使用最小的控制工作使机器人走进直线。

将模型的参数加载到MATLAB®工作空间中。
robotParametersrl.
打开Simulin万博1manbetxk模型。
mdl =“rlWalkingBipedRobot”;Open_System(MDL)
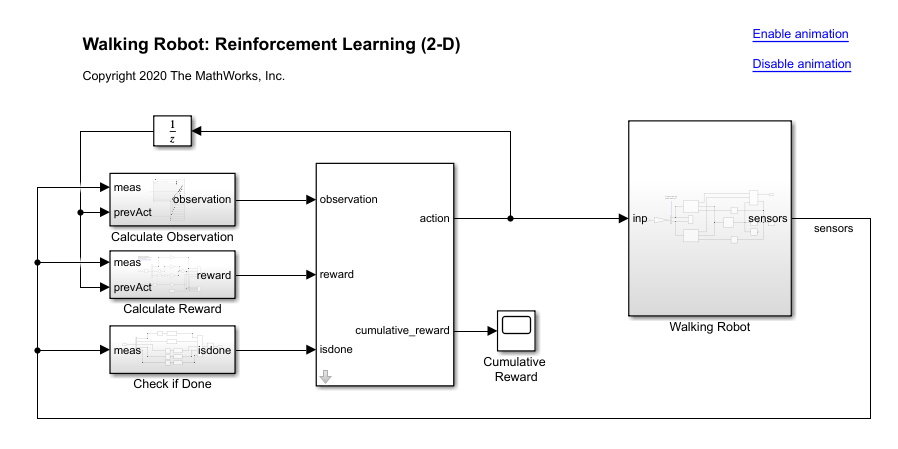
机器人使用Simscape Multibody建模。
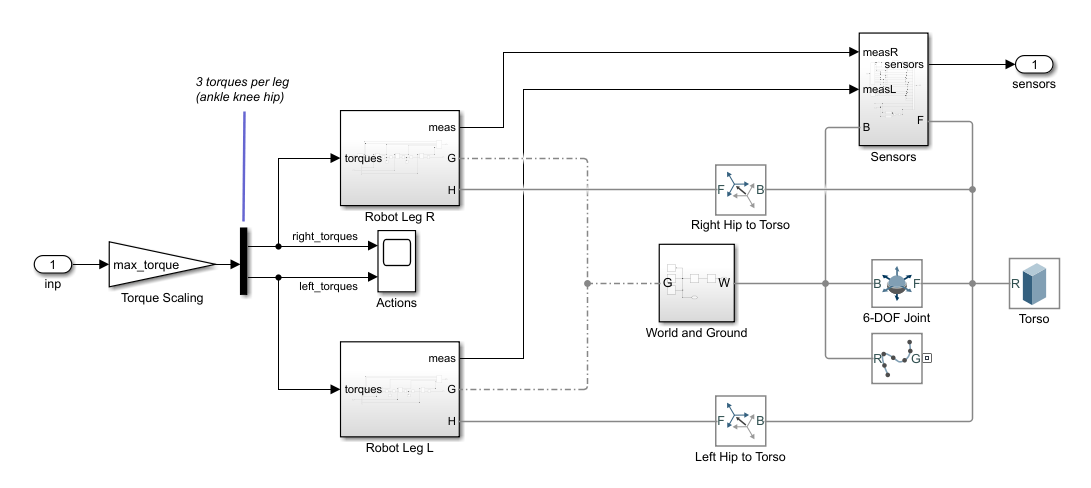
对于此模型:
在中性的0弧度位置,双腿伸直,脚踝平。
脚接触使用空间接触力(Simscape多体)块。
agent可以通过施加来自机器人的扭矩信号来控制机器人两条腿上的3个独立关节(踝关节、膝关节和髋关节)
-3到3.N·m。实际计算的动作信号被归一化-1和1.
环境为代理提供了以下29个观察。
躯干重心的Y(横向)和Z(垂直)平移。Z方向的平移归一化到与其他观测值相似的范围。
x(前进),y(横向)和z(垂直)平移速度。
躯干的偏航,俯仰和滚转角度。
偏航,俯仰和翻滚的躯干角速度。
两条腿上的三个关节(脚踝,膝盖,臀部)的角位置和速度。
上一个时间步骤的动作值。
如果发生以下任一条件,则会终止。
机器人躯干质心在z方向上小于0.1μm(机器人跌落)或在任一个方向上超过1μm(机器人移动到侧面太远)。
辊,间距或偏航的绝对值大于0.7854 rad。
以下是奖励功能 ,在每次步骤中提供的,它受到了[2]的影响。
这里:
是机器人X方向(向前朝向目标)的翻译速度。
是来自目标直线轨迹的机器人的横向平移位移。
为机器人质心的归一化垂直平移位移。
是关节的扭矩我从上一步一步。
为环境的采样时间。
是环境的最终仿真时间。
这个奖励功能通过为正向速度提供正向奖励来鼓励代理向前移动。它还通过提供持续的奖励( )。奖励功能中的其他术语是对横向和纵向翻译的重大改变以及使用额外控制努力的惩罚。
创建环境界面
创建观察规范。
numobs = 29;ObsInfo = rlnumericspec([numobs 1]);ObsInfo.name =.'观察';
创建动作规范。
numAct = 6;actInfo = rlNumericSpec([numAct 1],'lowerimit',-1,“UpperLimit”,1);Actinfo.name =.“foot_torque”;
为行走机器人模型创建环境界面。
blk = [mdl,' / RL代理'];env = rl万博1manbetxSimulinkEnv (mdl,黑色,obsInfo actInfo);env。ResetFcn = @(in) walkerResetFcn(in,upper_leg_length/100,lower_leg_length/100,h/100);
选择并创建用于培训的代理
这个示例提供了使用DDPG或TD3代理培训机器人的选项。要用你选择的代理来模拟机器人,设置鼓励相应的国旗。
Agentselection =.'td3';转变鼓励案件'ddpg'代理= createdDpgagent(numobs,homeinfo,numact,actinfo,ts);案件'td3'代理= createTD3Agent (numObs obsInfo、numAct actInfo, Ts);除此以外DISP('输入DDPG或TD3以获得Agentselection')结束
的createdDpgagent.和createTD3Agent辅助函数执行以下操作。
创建演员和批评网络。
为演员和影评人表示指定选项。
使用创建的网络和指定的选项创建演员和影评人表示。
配置代理特定选项。
创建代理。
DDPG代理商
DDPG代理使用批评价值函数表示来估计长期奖励给出的观察和行动。DDPG代理决定通过使用演员表示来考虑观察的行动。此示例的演员和批评网络是由[1]的启发。
有关创建DDPG代理的详细信息,请参阅createdDpgagent.辅助功能。有关配置DDPG代理选项的信息,请参阅rlDDPGAgentOptions.
有关创建深度神经网络值函数表示的更多信息,请参阅创建策略和值函数表示.有关为DDPG代理创建神经网络的示例,请参阅培训DDPG Agent控制双积分系统.
TD3代理商
TD3代理近似于使用两个批评函数表示,给定的长期奖励给出的观察和动作。TD3代理决定使用演员表示来考虑观察的行动。用于该代理的演员和批评网络的结构与用于DDPG代理的批评网络相同。
DDPG代理可以高估Q值。由于代理使用Q值来更新其策略(Actor),因此所产生的策略可以是次优和累积训练错误可能导致不同行为。TD3算法是DDPG的扩展,其改进使得通过防止Q值的高估来使其更加坚固[3]。
两个批评网络 - TD3代理商独立学习两个批评网络,并使用最小值函数估计以更新Actor(策略)。这样做可以防止在随后的步骤和高估Q值中累积错误。
添加目标策略噪声 - 将剪切噪声添加到值函数在类似操作上平滑Q函数值。这样做可以防止学习错误的嘈杂值估计的尖锐峰值。
延迟策略和目标更新 - 对于TD3代理,延迟Actor网络更新允许在更新策略之前将Q函数的更多时间减少错误(更接近所需的目标)。这样做可以防止价值估计的方差并导致更高质量的政策更新。
有关创建TD3代理的详细信息,请参阅createTD3Agent辅助功能。有关配置TD3代理选项的信息,请参阅rlTD3AgentOptions.
指定培训选项和火车代理
对于此示例,DDPG和TD3代理的培训选项是相同的。
每次集发作最初运行2000次剧集的每个培训课程
maxsteps.时间的步骤。在Episode Manager对话框中显示培训进度(设置
绘图选项),并禁用命令行显示(设置verb选项)。仅在达到最大剧集数时终止培训(
maxEpisodes)。这样做允许比较整个训练会话中多个代理的学习曲线。
有关更多信息和其他选项,请参见rltringOptions..
maxepisodes = 2000;maxsteps =楼层(tf / ts);训练= rltrainingOptions(......'maxepisodes',maxepisodes,......“MaxStepsPerEpisode”,maxsteps,......“ScoreAveragingWindowLength”,250,......'verbose',错误的,......“阴谋”,'培训 - 进展',......“StopTrainingCriteria”,'episodecount',......'stoptriningvalue',maxepisodes,......'SaveAgentCriteria','episodecount',......“SaveAgentValue”,maxepisodes);
要平行培训代理,请指定以下培训选项。并行培训需要并行计算工具箱™。如果您没有安装并行计算工具箱软件,请设置UseParallel到假.
设定
UseParallelt选项后悔.并行异步训练代理。
在每32步之后,让每个工作者将经验发送到并行池客户端(开始培训的MATLAB®过程)。DDPG和TD3代理商要求工作人员向客户发送经验。
trainOpts。UseParallel = true;trainOpts.ParallelizationOptions.Mode ='async';trainOpts.ParallelizationOptions.StepsUntilDataIsSent = 32;trainOpts.ParallelizationOptions.DataToSendFromWorkers =“经验”;
训练代理人使用火车功能。此过程是计算密集的,需要几个小时才能为每个代理完成。要在运行此示例的同时节省时间,请通过设置加载预制代理doTraining到假.训练代理人,套装doTraining到真的.由于并行培训中的随机性,您可以期待不同的培训结果。使用四名工人并行培训预制代理人。
dotraining = false;如果doTraining%训练代理人。TrainingStats =火车(代理商,ENV,训练);其他的%加载所选代理类型的预培训代理。如果Strcmp(Agentselection,'ddpg')负载('rlwalkingbipedrebotdddpg.mat','代理人')其他的加载(“rlWalkingBipedRobotTD3.mat”,'代理人')结束结束


对于前述示例训练曲线,DDPG和TD3代理的每个训练步骤的平均时间分别为0.11和0.12秒。TD3代理每一步采取更多培训时间,因为它与用于DDPG的单个评论家相比,它更新了两个批评网络。
模拟训练有素的代理人
修复随机发生器种子以进行再现性。
RNG(0)
要验证培训的代理的性能,请在Biped机器人环境中模拟它。有关代理模拟的更多信息,请参阅rlSimulationOptions和sim卡.
simOptions = rlSimulationOptions (“MaxSteps”,maxsteps);体验= SIM(ENV,Agent,SimOptions);

比较代理表现
对于下面的agent比较,每个agent每次使用不同的随机种子进行5次训练。由于随机探索噪声和并行训练的随机性,每次跑的学习曲线是不同的。由于多次运行的代理训练需要几天时间才能完成,所以这个比较使用的是预先训练过的代理。
对于DDPG和TD3 agents,绘制集奖励(上图)和集Q0值(下图)的平均值和标准差。情景Q0值是在给定初始环境观察的情况下,每一情景开始时对贴现长期回报的评论家估计。对于一个设计良好的影评人来说,Q0情节的价值接近于真正的贴现长期回报。
CompateDerformance(“DDPGAgent”,'td3agent')


基于学习曲线比较图:
DDPG经纪人似乎学得更快(平均在第600集左右),但达到了局部最小值。TD3开始较慢,但最终会获得比DDPG更高的奖励,因为它避免了高估Q值。
TD3代理显示其学习曲线的稳定改善,这表明与DDPG代理相比的稳定性提高。
根据Q0的对比情节:
对于TD3代理商,与DDPG代理商相比,批评折扣长期奖励(2000集)的估算率较低。这种差异是因为TD3算法采用保守方法在更新其目标时使用至少两个Q函数更新其目标。由于目标的更新延迟,此行为进一步增强。
虽然对这2000年的TD3估计较低,但与DDPG药剂不同,TD3药剂在Q0值中显示出稳定的增长。
在此示例中,培训在2000集中停止。对于较大的培训期,TD3代理具有稳定增加的估计值表明,趋势会聚到真正的折扣长期奖励。
关于如何训练人形机器人使用DDPG代理行走的另一个例子,参见火车人形沃克(Simscape多体).有关如何使用DDPG代理训练四足机器人的示例,请参阅使用DDPG代理的四足机器人机器人.
参考文献
Lillicrap, Timothy P, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver和Daan Wierstra。“深度强化学习的连续控制”。预印本,2019年7月5日提交。https://arxiv.org/abs/1509.02971.
[2] Heess,Nicolas,Dhruva TB,Srinivasan Sriram,Jay Lemmon,Josh Merel,Greg Wayne,Yuval Tassa,等。“富裕环境中运动行为的出现。”预印刷品,2017年7月10日提交。https://arxiv.org/abs/1707.02286.
[3]富士岛,斯科特,赫克·瓦蹄和大卫梅尔。“解决演员批评方法中的函数近似误差。”预印文,2018年10月22日提交。https://arxiv.org/abs/1802.09477.
另请参阅
相关话题
相关话题
您还可以从以下列表中选择一个网站: