이페이지의최신내용은아직번역되지않았습니다。최신내용은영문으로볼수있습니다。
主成分分析
원시데이터에대한주성분분석
구문
설명
예제
데이터세트의주성분
표본데이터세트를불러옵니다。
加载哈尔德
성분데이터는4개변수에대한13개의관측값을가집니다。
성분데이터에대한주성분을구합니다。
多项式系数= pca(成分)
多项式系数=4×4-0.0678 -0.6460 0.5673 - 0.5062 - 0.05440 0.4933 0.0290 0.7553 0.4036 0.5156 0.7309 -0.1085 -0.4684 0.4844
多项式系数4개의행은성분변수에대한계수를포함하고,열4개은주성분에대응됩니다。
누락된데이터가있을때의PCA
데이터세트에결측값이있을때의주성분계수를구합니다。
표본데이터세트를불러옵니다。
加载进口- 85
데이터행렬X는3열~ 15열에13개의연속형변수가있습니다。휠베이스,길이,너비,높이,전비중량,엔진크기,구경,스트로크,압축비,마력,피크rpm,시내주행거,리고속도로주행거리가이에해당됩니다。구경변수와스트로크변수는행56 ~ 59행에네개의결측값이있으며,마력변수와피크rpm변수는행131 ~ 132행에두개의결측값이있습니다。
주성분분석을수행합니다。
多项式系数= pca (X (:, 3:15));
기본적으로,主成分分析는“行”,“完成”이름 - 값쌍의인수로지정된동작을수행합니다。이옵션은계산을수행하기전에南값을갖는관측값을제거합니다。南이있는행은대응되는위치,즉56행~ 59행,131행및132행에서分数및tsquared에다시삽입됩니다。
“成对”를사용하여주성분분석을수행합니다。
多项式系数= pca (X (:, 3:15),“行”,“成对”);
이경우,主成分分析는X의열我또는Ĵ에서南값이없는행을사용하여공분산행렬의(i, j)요소를계산합니다。참고로,결과로생성되는공분산행렬은양의정부호가아닐수있습니다。이옵션은主成分分析가사용하는알고리즘이고유값분해인경우에만적용됩니다。이예제에서볼수있듯이,알고리즘을지정하지않으면主成分分析가알고리즘을“eig”로설정합니다。사용자가“成对”옵션과함께알고리즘으로“圣言”를요구하면,主成分分析는경고메시지를반환하고,알고리즘을“eig”로설정한후연산을계속합니다。
“行”,“所有”이름——값쌍의인수를사용하는경우이옵션이데이터세트에결측값이없다고가정하기때문에主成分分析가종료됩니다。
多项式系数= pca (X (:, 3:15),“行”,'所有');
使用pca的错误(第180行)原始数据包含NaN缺失值,而'Rows'选项被设置为'all'。考虑使用“完整”或“成对”选项。
가중PCA
주성분분석을수행하는동안역가변분산을가중치로사용합니다。
표본데이터세트를불러옵니다。
加载哈尔德
성분에대한분산의역을가변가중치로사용하여주성분분석을수행합니다。
[wcoeff, ~,潜伏,~,解释]= pca(成分,…“VariableWeights”,“方差”)
wcoeff =4×4-2.7998 2.9940 -3.9736 1.4180 -8.7743 -6.4411 4.8927 9.9863 2.5240 -3.8749 -4.0845 1.7196 9.1714 7.5529 3.2710 11.3273
潜在的=4×12.2357 1.5761 0.1866 0.0016
解释了=4×155.8926 39.4017 4.6652 0.0406
참고로,계수행렬wcoeff는정규직교가아닙니다。
정규직교계수행렬을계산합니다。
coeffort = inv(diag(std(成分))* wcoeff
coefforth =4×40.4760 0.5090 0.2411 0.3144 0.6418 0.3941 -0.6050 -0.6377 0.2685 0.5412 0.1954 0.6767
새계수행렬coefforth의정규직교성을확인합니다。
coefforth * coefforth’
ans =4×41.0000 0.0000 -0.0000 0.0000 -0.0000 -0.0000 -0.0000 -0.0000 -0.0000 -0.0000 0.0000 -0.0000 0.0000 -0.0000 0.0000
누락된데이터에대한ALS를사용한PCA
데이터에결측값이있을때교대최소제곱법(ALS)알고리즘을사용하여주성분을구합니다。
표본데이터를불러옵니다。
加载哈尔德
성분데이터는4개변수에대한13개의관측값을가집니다。
ALS알고리즘을사용하여주성분분석을수행하고성분계수를표시합니다。
[多项式系数,分数,潜伏,tsquared解释]= pca(成分);多项式系数
多项式系数=4×4-0.0678 -0.6460 0.5673 - 0.5062 - 0.05440 0.4933 0.0290 0.7553 0.4036 0.5156 0.7309 -0.1085 -0.4684 0.4844
결측값을임의로추가합니다。
y =成分;rng (“默认”);%,持续重现IX =随机(“互可操作性框架”,0,1,大小(Y))<0.30;Y(ⅸ)= NaN的
y =13×47 26日6南1 29日15 52南南8 20 11 31日南47 7 52 6 33南55南南南71南6 1 31日南44 2南南22 21 47 4 26⋮
현재대략적으로데이터의가30%南으로표시되는결측값을가집니다。
ALS알고리즘을사용하여주성분분석을수행하고성분계수를표시합니다。
[COEFF1,score1,潜,tsquared,所解释的,MU1] = PCA(Y,…“算法”,“als”);coeff1
coeff1 =4×4-0.0362 0.8215 -0.5252 0.2190 -0.6831 -0.0998 0.1828 0.6999 0.0169 0.5575 0.8215 -0.1185 0.7292 -0.0657 0.1261 0.6694
추정된평균을표시합니다。
mu1
mu1 =1×48.9956 47.9088 9.0451 28.5515
관측된데이터를재구성합니다。
t = score1*coeff1' + repmat(mu1,13,1)
t =13×47.0000 26.0000 6.0000 51.5250 1.0000 29.0000 15.0000 52.0000 10.7819 53.0230 8.0000 20.0000 11.0000 31.0000 13.5500 47.0000 7.0000 52.0000 6.0000 33.0000 10.4818 55.0000 7.8328 17.9362 3.0982 71.0000 11.9491 6.0000 1.0000 31.0000 -0.5161 44.0000 2.0000 53.7914 5.7710 22.0000 21.0000 47.0000 4.0000 26.0000⋮
ALS알고리즘은데이터에포함된결측값을추정합니다。
결과를비교하는또다른방법은계수벡터에의해생성된(跨度)두공간사이의각도를구하는것입니다。ALS를사용하여결측값이있는데이터에대해구한계수와전체데이터에대해구한계수사이의각도를구합니다。
子空间(多项式系数,coeff1)
ans = 8.1666 e-16
이각도는작은값입니다。이는누락된데이터가없을때“行”,“完成”이름 - 값쌍의인수와함께主成分分析를사용하는경우생성된결과와누락된데이터가있을때'算法', 'ALS'이름 - 값쌍의인수와함께主成分分析를사용하는경우생성된결과가서로근접하다는것을나타냅니다。
“行”,“完成”이름——값쌍의인수를사용하여주성분분석을수행하고성분계수를표시합니다。
[coeff2 score2,潜伏,tsquared,解释说,mu2] = pca (y,…“行”,“完成”);coeff2
coeff2 =4×3-0.2054 0.8587 -0.6694 -0.3720 0.5510 0.1474 -0.3513 -0.5187 0.6986 -0.0298 0.6518
이경우,主成分分析가결측값이있는행을제거하므로y는결측값이없는네개의행만가집니다。따라서主成分分析는세개의주성분만반환합니다。공분산행렬이양의준정부호가아니고主成分分析가오류메시지를반환하므로“行”,“成对”옵션을사용할수없습니다。
목록별(Listwise)삭제를사용하여결측값이있는데이터에대해구한계수와전체데이터에대해구한계수사이의각도를구합니다(“行”,“完成”인경우)。
子空间(多项式系数(:1:3),coeff2)
ans = 0.3576
두공간사이의각도는상당히큽니다。이는두결과가다르다는것을나타냅니다。
추정된평균을표시합니다。
mu2
mu2 =1×47.8889 46.9091 9.8750 29.6000
이경우,이평균이바로y의표본평균입니다。
관측된데이터를재구성합니다。
score2 * coeff2’
ans =13×4楠楠楠楠-7.5162 -18.3545 4.0968 22.0056楠楠楠楠楠楠楠楠-0.5644 5.3213 -3.3432 3.6040楠楠楠楠楠楠楠楠楠楠楠楠楠楠楠楠12.8315 -0.1076 -6.3333 -3.7758⋮
이는南값을포함하는행을삭제하는것이ALS알고리즘만큼효과가좋지않다는것을보여줍니다。데이터에결측값이많은경우ALS를사용하는것이더좋습니다。
주성분계수,점수분,산
주성분에대한계수,점수,분산을구합니다。
표본데이터세트를불러옵니다。
加载哈尔德
성분데이터는4개변수에대한13개의관측값을가집니다。
성분데이터의성분에대한주성분계수,점수,분산을구합니다。
[多项式系数,分数,潜伏]= pca(成分)
多项式系数=4×4-0.0678 -0.6460 0.5673 - 0.5062 - 0.05440 0.4933 0.0290 0.7553 0.4036 0.5156 0.7309 -0.1085 -0.4684 0.4844
得分=13×436.8218 -6.8709 -4.5909 0.3967 29.6073 4.6109 -2.2476 -0.3958 -12.9818 -4.2049 0.9022 -1.1261 23.7147 -6.6341 1.8547 -0.3786 -0.5532 -4.4617 -6.0874 0.1424 -10.8125 -3.6466 0.9130 -0.1350 -32.5882 8.9798 -1.6063 0.0818 22.6064 10.7259 3.2365 0.3243 -9.2626 8.9854 -0.0169 -0.5437 -3.2840 -14.1573 7.0465 0.3405⋮
潜在的=4×1517.7969 67.4964 12.4054 0.2372
分数의열은각각하나의주성분에대응됩니다。벡터潜在的는네개의주성분에대한분산을저장합니다。
중심화된성분데이터를재구성합니다。
Xcentered =得分*系数_”
Xcentered =13×4-0.4615 -22.1538 -5.7692 -6.4615 30.0000 -19.1538 3.2308 22.0000 3.5385 7.8462 -3.7692 -10.0000 3.5385 -17.1538 -3.7692 17.0000 -0.4615 3.8462 -5.7692 3.0000 3.5385 6.8462 -2.7692 -8.0000 -4.4615 22.8462 5.2308 -24.0000 -6.4615 -17.1538 10.2308 14.0000 -5.4615 5.8462 6.2308 -8.0000 13.5385 -1.1538 -7.7692 -4.0000⋮
Xcentered의새데이터는대응되는열에서열평균을빼는방식으로중심화된원래성분데이터입니다。
각변수에대한정규직교주성분계수와각관측값에대한주성분점수를하나의플롯에시각화합니다。
biplot(多项式系数(:,1:2),“分数”分数(:1:2),“varlabels”,{“v_1”,“v_2”,“v_3”,“两者”});
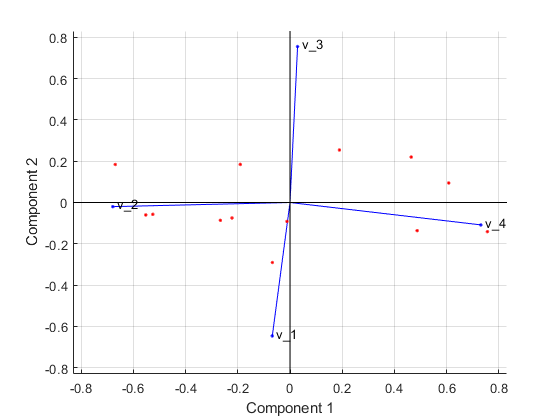
네개변수모두이행렬도에서벡터로표현되며,벡터의방향과길이는각변수가플롯의두주성분에서얼마나큰비중을차지하는지를나타냅니다。예를들어,가로축에있는첫번째주성분은세번째변수와네번째변수에대한양의계수를가집니다。따라서,벡터 및 는플롯의우반면쪽을향합니다。첫번째주성분의최대계수는네번째계수이며,이는변수 에대응됩니다。
세로축에있는두번째주성분은변수 , , 에대해서는음의계수를가지고변수 에대해서는양의계수를가집니다。
13개이2차원행렬도는관측값각각에대한점도포함하며,이점은플롯에서두개주성분에대한각관측값의점수를나타내는좌표를가집니다。예를들어,플롯의왼쪽가장자리근처에있는점은첫번째주성분에대해최소점수를가집니다。점은최대점수값과최대계수길이에대해스케일링되므로,플롯에서점의상대위치만확인할수있습니다。
Ť제곱통계량
호텔링T(霍特林)의제곱통계량값을구합니다。
표본데이터세트를불러옵니다。
加载哈尔德
성분데이터는4개변수에대한13개의관측값을가집니다。
주성분분석을수행하고T제곱값을요청합니다。
[多项式系数,分数,潜伏,tsquared] = pca(成分);tsquared
tsquared =13×15.6803 3.0758 6.0002 2.6198 3.3681 0.5668 3.4818 3.9794 2.6086 7.4818⋮
처음두주성분만요청하고요청된주성분의감소된공간에서제T곱값을계산합니다。
[多项式系数,分数,潜伏,tsquared] = pca(成分,“NumComponents”2);tsquared
tsquared =13×15.6803 3.0758 6.0002 2.6198 3.3681 0.5668 3.4818 3.9794 2.6086 7.4818⋮
참고로,감소된성분공간을지정하는경우에도,主成分分析는네개성분을모두사용하여전체공간에서제T곱값을계산합니다。
T감소된공간의제곱값은감소된공간에서마할라노비스거리에대응됩니다。
tsqreduced =陵(得分,得分)
tsqreduced =13×13.3179 2.0079 0.5874 1.7382 0.2955 0.4228 3.2457 2.6914 1.3619 2.9903⋮
전체공간의Ť제곱값과감소된공간의마할라노비스거리의차이를구하여삭제된공간에서의Ť제곱값을계산합니다。
tsq= tsquared - tsq约简
tsqdiscarded =13×12.3624 1.0679 5.4128 0.8816 3.0726 0.1440 0.2362 1.2880 1.2467 4.4915⋮
주성분으로설명되는변동성백분율
주성분으로설명되는변동성백분율을구합니다。주성분공간에서의데이터표현을표시합니다。
표본데이터세트를불러옵니다。
加载进口- 85
데이터행렬X는3열~ 15열에13개의연속형변수가있습니다。휠베이스,길이,너비,높이,전비중량,엔진크기,구경,스트로크,압축비,마력,피크rpm,시내주행거,리고속도로주행거리가이에해당됩니다。
이러한변수의주성분으로설명되는변동성백분율을구합니다。
[多项式系数,分数,潜伏,tsquared解释]= pca (X (:, 3:15));解释
解释了=13×164.3429 35.4484 0.1550 0.0379 0.0078 0.0048 0.0013 0.0011 0.0005 0.0002⋮
처음세개성분은모든변동성의99.95%를설명합니다。
처음세개주성분으로구성된공간에서데이터표현을시각화합니다。
scatter3(分数(:1),分数(:,2),得分(:,3)轴平等的包含(第一主成分的)ylabel (第二主成分的)zlabel (第三主成分的)

데이터는첫번째주성분축을따라가장큰변동성을표시합니다。이는첫번째축에서선택가능한모든선택에서의가장큰분산입니다。두번째주성분축을따른변동성은두번째축에서선택할수있는남아있는모든선택에서의가장큰분산입니다。세번째주성분축은세번째로큰변동성을가지며,이는두번째주성분축을따른변동성보다상당히작습니다。네번째주성분축에서열세번째주성분축까지는검사할가치가없습니다。이들축은데이터의전체변동성중0.05%만설명하기때문입니다。
특정출력값을생략하려면그에해당하는요소의위치에~를사용하면됩니다。예를들어T제곱값을얻지않으려는경우다음을지정하십시오。
[系数_,得分,潜,〜,说明] = PCA(X(:,3:15));
새데이터에PCA를적용하고C / c++코드생성하기
하나의데이터세트에대해주성분을구하고다른데이터세트에PCA를적용합니다。이절차는머신러닝모델을위한훈련데이터세트와검정데이터세트가있는경우에유용합니다。예를들어,PCA를사용하여훈련데이터세트를전처리한다음모델을훈련시킬수있습니다。훈련된모델을검정데이터세트를사용하여검정하려면훈련데이터에서얻은PCA변환을검정데이터세트에적용해야합니다。
이예제에서는C / c++코드를생성하는방법도설명합니다。主成分分析는코드생성을지원하므로,훈련데이터세트를사용하여PCA를수행하는코드를생성한다음PCA를검정데이터세트에적용할수있습니다。그런다음장치에코드를배포합니다。이워크플로에서는훈련데이터를전달해야하는데,그크기가상당히클수있습니다。장치의메모리를절약하기위해훈련과예측을분리할수있습니다。MATLAB®에서主成分分析를사용하고,장치에서생성된코드의새데이터에PCA를적용합니다。
C / c++코드를생성하려면MATLAB®编码器™가필요합니다。
새데이터에PCA적용하기
readtable을사용하여데이터세트를테이블로불러옵니다。데이터세트는파일CreditRating_Historical.dat에있습니다。이파일은과거신용등급데이터를포함합니다。
creditrating = readtable (“CreditRating_Historical.dat”);企业资信(1:5,:)
ans =5×8表ID WC_TA RE_TA EBIT_TA MVE_BVTD S_TA行业评级_____ _____ _____累积________ _____ ________ 62394 0.013 0.104 0.036 0.447 0.142 3 {“BB”} 48608 0.232 0.335 0.062 1.969 0.281 8 {A} 42444 0.311 0.367 0.074 1.935 0.366 1 {A} 48631 0.194 0.263 0.062 1.017 0.228 - 4 {BBB的}43768 0.121 0.413 0.057 3.647 0.466 12 {' AAA '}
첫번째열은각관측값의ID이고,마지막열은등급입니다。두번째열부터일곱번째열까지를예측변수데이터로지정하고,마지막열(评分)을응답변수로지정합니다。
X = table2array (creditrating (: 2:7));Y = creditrating.Rating;
처음100개의관측값을검정데이터로사용하고나머지를훈련데이터로사용합니다。
XTEST = X(1:100,:);XTrain = X(101:结束,:);YTest = Y(1:100);YTrain = Y(101:结束);
훈련데이터세트XTrain에대한주성분을구합니다。
[系数_,scoreTrain,〜,〜,所解释的,μ= PCA(XTrain);
이코드는4개의출력값(多项式系数,scoreTrain,解释,μ)을반환합니다。解释(설명된총분산의백분율)를사용하여최의95%소변동성을설명하는데필요한성분의개수를구합니다。多项式系数(주성분계수)및μ(XTrain에대한추정된평균)를사용하여PCA를검정데이터세트에적용합니다。모델을훈련시킬때는XTrain대신scoreTrain(주성분점수)을사용하십시오。
주성분으로설명되는변동성백분율을표시합니다。
解释
解释了=6×158.2614 41.2606 0.3875 0.0632 0.0269 0.0005
처음두개성분은모든변동성의95%이상을설명합니다。而루프를사용하여최소95%의변동성을설명하는데필요한성분의개수를프로그래밍방식으로구합니다。
sum_explained = 0;idx = 0;而sum_explained <95 IDX = IDX + 1;sum_explained = sum_explained +解释(IDX);结束idx
idx = 2
처음두개성분을사용하여분류트리를훈련시킵니다。
scoreTrain95 = scoreTrain (:, 1: idx);mdl = fitctree (scoreTrain95 YTrain);
mdl은ClassificationTree모델입니다。
훈련된모델을검정세트에대해사용하려면훈련데이터세트에서얻은PCA를사용하여검정데이터세트를변환해야합니다。XTest에서μ를빼고多项式系数를곱하여검정데이터세트의주성분점수를구합니다。처음두개성분의점수만필요하므로처음두개계수多项式系数(:1:idx)를사용합니다。
scoreTest95 =(XTEST-MU)*系数_(:,1:IDX);
훈련된모델mdl과변환된검정데이터세트scoreTest를预测함수에전달하여검정세트에대한신용등급을예측합니다。
YTest_predicted =预测(MDL,scoreTest95);
코드생성하기
데이터에PCA를적용하고훈련된모델을사용하여신용등급을예측하는코드를생성합니다。C / c++코드를생성하려면MATLAB®编码器™가필요합니다。
saveLearnerForCoder를사용하여분류모델을파일myMdl.mat에저장합니다。
saveLearnerForCoder (mdl'myMdl');
검정데이터세트(XTest)와PCA정보(多项式系数및μ)를받아서검정데이터의신용등급을반환하는myPCAPredict라는이름의진입점함수를정의합니다。
진입점함수의함수시그니처뒤에% # codegen컴파일러지시문(또는杂注)을추가하여MATLAB알고리즘을위한코드를생성하고자함을표시합니다。이지시문을추가하면MATLAB코드분석기에코드생성중에오류를유발할수있는위반을진단하여수정할수있도록지원해달라는명령을내리게됩니다。
类型myPCAPredict%显示内容的myPCAPredict.m
函数标签= myPCAPredict(XTest,coeff,mu) %#codegen %转换数据使用PCA scoreTest = bsxfun(@ -,XTest,mu)*coeff;%加载训练分类模型mdl = loadLearnerForCoder('myMdl');%预测评分使用加载的模型标签=预测(mdl,计分);
myPCAPredict는多项式系数및μ를사용하여새데이터에PCA를적용한다음변환된데이터를사용하여신용등급을예측합니다。이렇게하면크기가상당히클수있는훈련데이터를전달하지않아도됩니다。
참고:이페이지의오른쪽위섹션에있는버튼을클릭하고이예제를MATLAB®에서열면예제폴더가열립니다。이폴더에는진입점함수파일이포함되어있습니다。
codegen을사용하여코드를생성합니다。C와c++는정적유형언어이므로컴파일시점에진입점함수의모든변수의속성을결정해야합니다。데이터형과정확한입력배열크기를지정하려면arg游戏옵션을사용하여특정데이터형과배열크기를포함하는값세트를나타내는MATLAB®표현식을전달하십시오。컴파일시점에몇몇관측값이알려지지않은경우에는coder.typeof를사용하여입력값을가변크기로지정할수도있습니다。자세한내용은为代码生成指定可变大小的参数항목을참조하십시오。
codegenmyPCAPredictarg游戏{coder.typeof (XTest[正无穷,6],[1,0]),多项式系数(:,1:idx),μ}
codegen은플랫폼별확장자를갖는墨西哥人함수myPCAPredict_mex를생성합니다。
생성된코드를확인합니다。
YTest_predicted_mex = myPCAPredict_mex (XTest多项式系数(:1:idx),μ);isequal (YTest_predicted YTest_predicted_mex)
ans =逻辑1
isequal이논리값1 (真正的)을반환합니다。이는모든입력값이동일하다는의미입니다。비교를통해mdl의预测함수와myPCAPredict_mex함수가동일한신용등급을반환함을확인할수있습니다。
코드생성에대한자세한내용은代码生成简介항목및代码生成和分类学习应用항목을참조하십시오。후자항목에서는분류학습기앱을사용하여PCA를수행하고모델을훈련시키는방법과훈련된모델을기반으로새데이터에대해레이블을예측하는C / C ++코드를생성하는방법을설명합니다。
입력인수
출력인수
세부정보
참고문헌
[1]乔利夫,I. T.主成分分析。第2版,Springer,2002。
多元分析原理。牛津大学出版社,1988年。
[3] Seber,G. A. F.多元观察。Wiley出版社,1984年。
[4]杰克逊,J. E. A.用户指南到主成分分析。Wiley出版社,1988年。
[5] Roweis, S. " EM算法的PCA和SPCA。,发表于1997年神经信息处理系统进展会议论文集。第10卷(NIPS 1997),麻州剑桥:麻省理工学院出版社,1998年,第626-632页。
[6]伊林,A.和T.赖科。“在缺失值存在的情况下进行主成分分析的实用方法。“j·马赫。学习。Res . .第11卷,2010年8月,1957-2000页。
확장기능
R2012b에개발됨
你也可以从以下列表中选择一个网站:
