텍스트산점도플롯을사용하여단어임베딩시각화하기
이예제에서는2차원및3차원t-SNE와텍스트산점도플롯을사용하여단어임베딩을시각화하는방법을보여줍니다。
단어임베딩은단어집의단어를실수형벡터로매핑합니다。벡터는유사한단어들이유사한벡터를갖도록단어의의미체계를캡처합니다。또한어떤임베딩은“이탈리아와프랑스의관계는로마와파리의관계와같다”처럼단어사이의관계도캡처합니다。벡터형식에서이관계는 입니다。
사전훈련된단어임베딩불러오기
사전훈련된단어임베딩을fastTextWordEmbedding을사용하여불러옵니다。이함수를사용하려면文本分析工具箱™模型快速文本英语160亿令牌词嵌入지원패키지가필합니다。이지원패키지가설치되어있지않으면함수에서다운로드링크를제공합니다。
emb = fasttextwordem寝料
emb = worddembedbedwith properties:维数:300词汇:[1×999994 string]
word2vec및vec2word를사용하여단어임베딩을탐색합니다。word2vec을사용하여단어意大利,罗马및巴黎를벡터로변환합니다。
意大利= e2vec (emb;“意大利”);* * * * * * * * * * * *“罗马”);巴黎= word2vec(emb,“巴黎”);
意大利-罗马+巴黎에의해주어지는벡터를계산합니다。이벡터에는단어意大利에서 단어罗马의의미를제외하고단어巴黎의의미를포함시킨의미관계가내포되어있습니다。
Vec =意大利-罗马+巴黎
vec =1×300单行向量0.1606 -0.0690 0.1183 -0.0349 0.0672 0.0907 -0.1820 -0.0080 0.0320 -0.0936 -0.0329 -0.1548 0.1737 -0.0937 -0.1619 0.0777 -0.0843 0.0066 0.0600 -0.2059 -0.0268 0.1350 -0.0900 0.0314 0.0686 -0.0338 0.1841 0.1708 0.0276 0.0719 -0.1667 0.0231 0.0265 -0.1773 -0.1135 0.1018 -0.2339 0.1008 0.1057 -0.0958 0.0911 -0.0184 0.0740 -0.1081 0.0826 0.0463 0.0043
vec2word를사용하여임베딩에서vec에가장가까운단어를찾습니다。
Word = vec2word(emb,vec)
字= "法国"
2차원텍스트산점도플롯만들기
tsne및textscatter를사용해서2-d텍스트산점도플롯을만들어단어임베딩을시각화합니다。
word2vec을사용하여처음5000개단어를벡터로변환합니다。V는길이가300表단어벡터로구성된행렬입니다。
words = emb.Vocabulary(1:5000);V = word2vec(emb,words);大小(V)
ans =1×25000 300
tsne를사용하여2차원공간에단어벡터를임베딩합니다。이함수를실행하는데몇분정도소될수있습니다。수렴정보를@ @시하려면“详细”이름-값쌍을1로설정하십시오。
XY = tsne(V);
2d텍스트산점도플롯에서XY에의해지정된좌@ @에단어를플로팅합니다。가독성을위해textscatter는기본적으로모든입력단어를` ` `시하지는않으며마커를대신` ` ` `시합니다。
图textscatter(XY,words)“词嵌入t-SNE图”)

플롯의한부분을확대합니다。
Xlim ([-18 -5]) ylim([11 21])

3d텍스트산점도플롯만들기
tsne및textscatter를사용해서3d텍스트산점도플롯을만들어단어임베딩을시각화합니다。
word2vec을사용하여처음5000개단어를벡터로변환합니다。V는길이가300表단어벡터로구성된행렬입니다。
words = emb.Vocabulary(1:5000);V = word2vec(emb,words);大小(V)
ans =1×25000 300
차원수를3으로지정하여tsne를사용해서3차원공간에단어벡터를포함시킵니다。이함수를실행하는데몇분정도소될수있습니다。수렴정보를@ @시하려는경우“详细”이름-값쌍을1로설정할수있습니다。
XYZ = tsne(V,“NumDimensions”3);
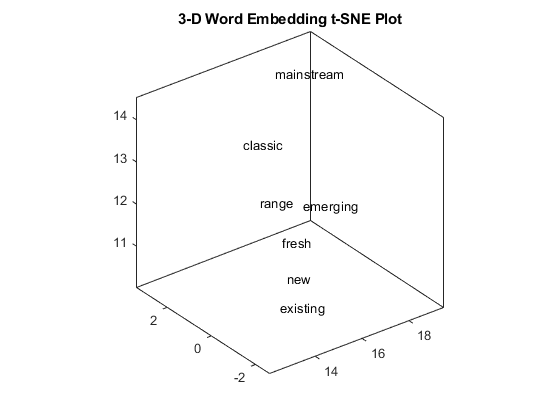
3-d텍스트산점도플롯에서xyz에의해지정된좌에단어를플로팅합니다。
figure ts = textscatter3(XYZ,words);标题(“三维词嵌入t-SNE图”)

플롯의한부분을확대합니다。
xlim ([12.04 - 19.48]) ylim ([-2.66 - 3.40]) zlim ([10.03 - 14.53])
군집분석수행
word2vec을사용하여처음5000개단어를벡터로변환합니다。V는길이가300表단어벡터로구성된행렬입니다。
words = emb.Vocabulary(1:5000);V = word2vec(emb,words);大小(V)
ans =1×25000 300
kmeans를사용하여25개군집을검색합니다。
cidx = kmeans(V,25,“距离”,“sqeuclidean”);
앞에서계산된二维t-SNE데이터좌표를사용하여텍스트산점도플롯에서군집을시각화합니다。
图textscatter (XY,话说,“ColorData”分类(cidx));标题(“词嵌入t-SNE图”)
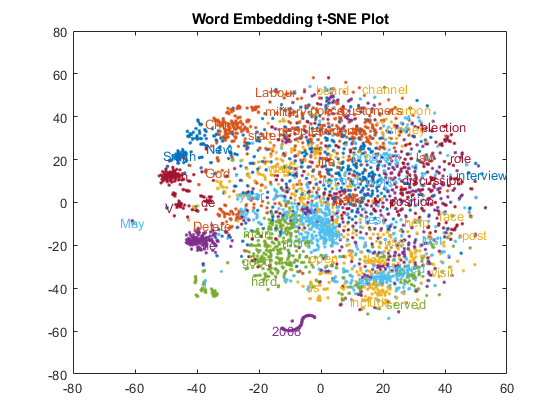
플롯의한부분을확대합니다。
Xlim ([13 24]) ylim([-47 -35])

참고 항목
readWordEmbedding|textscatter|textscatter3|word2vec|vec2word|wordEmbedding|tokenizedDocument
관련 항목
您也可以从以下列表中选择一个网站: