stretchAudio
Time-stretch音频
描述
例子
使用TSM
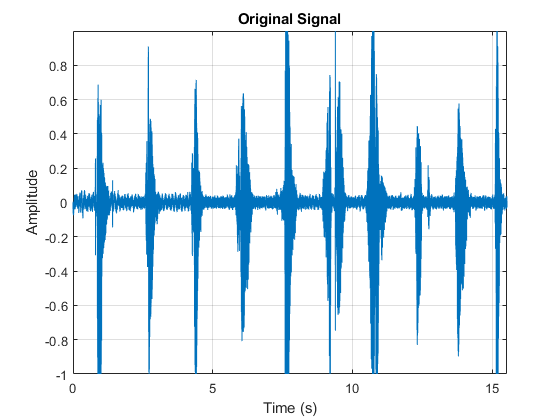
读取音频信号。听音频信号,并绘制它的时间。
[audioIn, fs] = audioread (“Counting-16-44p1-mono-15secs.wav”);t =(0:大小(audioIn, 1) 1) / fs;情节(t, audioIn)包含(“时间(s)”) ylabel (“振幅”)标题(原始信号的)轴紧网格在
声音(audioIn fs)
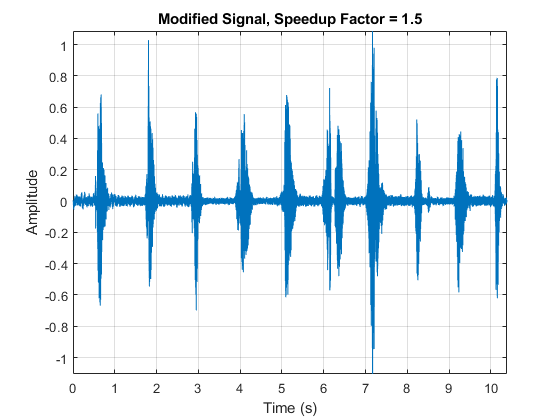
使用stretchAudio要应用1.5的加速因子。倾听修改后的音频信号,并绘制出它随时间的变化。采样率保持不变,但信号的持续时间减少了。
audioOut = stretchAudio (audioIn, 1.5);t =(0:大小(audioOut, 1) 1) / fs;情节(t, audioOut)包含(“时间(s)”) ylabel (“振幅”)标题(“修改信号,加速因子= 1.5”)轴紧网格在
声音(audioOut fs)
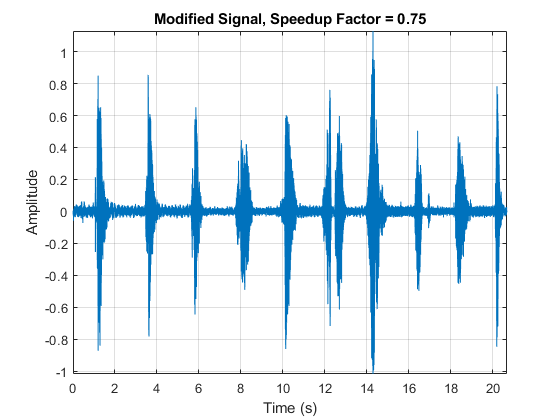
将原始音频信号降低0.75倍。倾听修改后的音频信号,并绘制出它随时间的变化。采样率与原始音频保持不变,但信号持续时间增加。
audioOut = stretchAudio (audioIn, 0.75);t =(0:大小(audioOut, 1) 1) / fs;情节(t, audioOut)包含(“时间(s)”) ylabel (“振幅”)标题('修正信号,加速因子= 0.75')轴紧网格在
声音(audioOut fs)
将TSM应用于频域音频
stretchAudio万博1manbetx当使用默认的声码器方法时,支持在频域音频上的TSM。将TSM应用于频域音频,可以为多个TSM因子重用STFT计算。
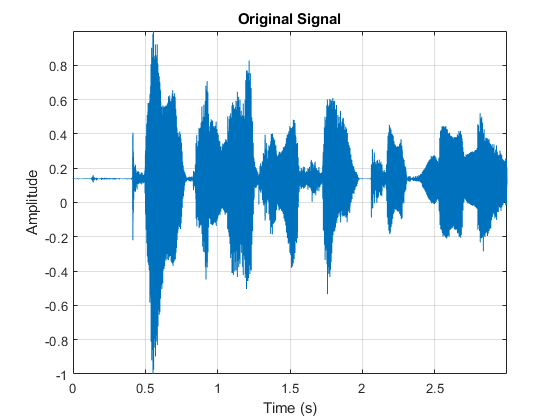
读取音频信号。听音频信号,并绘制它的时间。
[audioIn, fs] = audioread (“FemaleSpeech-16-8-mono-3secs.wav”);t = (0:size(audioIn,1)-1)/fs;情节(t, audioIn)包含(“时间(s)”) ylabel (“振幅”)标题(原始信号的)轴紧网格在
将音频信号转换到频域。
赢得=√损害(256“周期”));ovrlp = 192;S = stft (audioIn“窗口”,赢了,“OverlapLength”ovrlp,“中心”、假);
将音频信号的速度提高到1.4倍。指定用于创建频域表示的窗口和重叠长度。
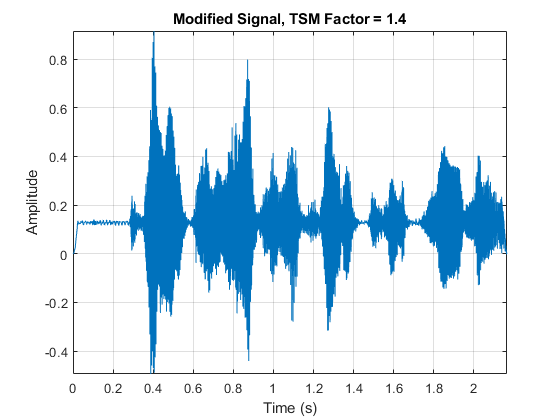
α= 1.4;audioOut = stretchAudio(年代,α,“窗口”,赢了,“OverlapLength”, ovrlp);t = (0:size(audioOut,1)-1)/fs;情节(t, audioOut)包含(“时间(s)”) ylabel (“振幅”)标题(‘修改信号,TSM因子= 1.4’)轴紧网格在
将音频信号降低0.8倍。指定用于创建频域表示的窗口和重叠长度。
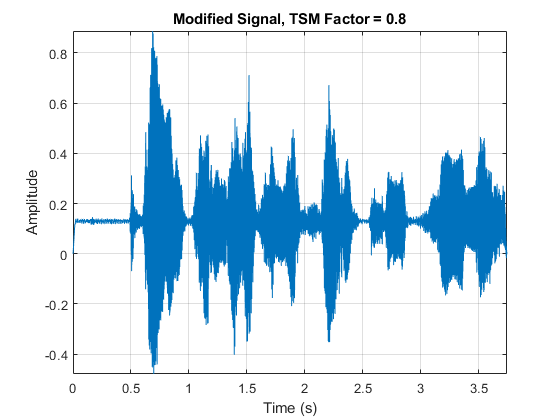
α= 0.8;audioOut = stretchAudio(年代,α,“窗口”,赢了,“OverlapLength”, ovrlp);t = (0:size(audioOut,1)-1)/fs;情节(t, audioOut)包含(“时间(s)”) ylabel (“振幅”)标题(‘修正信号,TSM因子= 0.8’)轴紧网格在
使用锁相提高保真度
缺省的TSM方法(声码器)允许您附加地应用锁相以提高原始音频的保真度。
读取音频信号。听音频信号,并绘制它的时间。
[audioIn, fs] = audioread (“SpeechDFT-16-8-mono-5secs.wav”);t = (0:size(audioIn,1)-1)/fs;情节(t, audioIn)包含(“时间(s)”) ylabel (“振幅”)标题(原始信号的)轴紧网格在

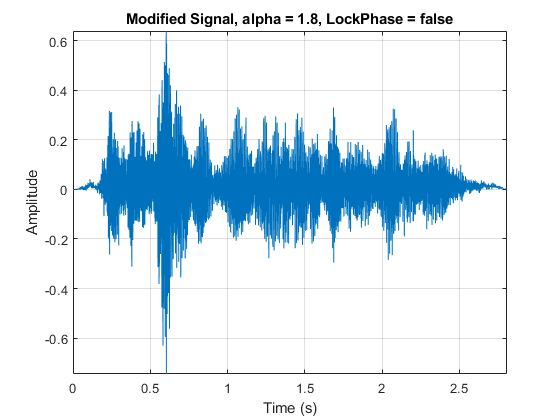
相位锁定向TSM添加了一个重要的计算负载,而且并不总是必需的。缺省情况下,不启用锁相功能。对输入音频信号应用1.8的加速因子。听音频信号,并绘制它的时间。
α= 1.8;tic audioOut = stretchAudio(audioIn,alpha);processingTimeWithoutPhaseLocking = toc
processingTimeWithoutPhaseLocking = 0.0798
t = (0:size(audioOut,1)-1)/fs;情节(t, audioOut)包含(“时间(s)”) ylabel (“振幅”)标题('修改的信号,alpha = 1.8, LockPhase = false')轴紧网格在
对输入音频信号应用相同的1.8加速因子,这次启用锁相。听音频信号,并绘制它的时间。
audioOut = stretchAudio(audioIn,alpha,“LockPhase”,真正的);processingTimeWithPhaseLocking = toc
processingTimeWithPhaseLocking = 0.1154
t = (0:size(audioOut,1)-1)/fs;情节(t, audioOut)包含(“时间(s)”) ylabel (“振幅”)标题('修改的信号,alpha = 1.8, LockPhase = true')轴紧网格在

使用WSOLA Delta提高保真度
波形相似重叠添加(WSOLA) TSM方法使您可以指定最大的采样数量来搜索最佳的信号对齐。缺省情况下,WSOLA delta是分析窗口中的样本数量减去相邻分析窗口之间重叠的样本数量。增加WSOLA增量会增加计算负荷,但也可能增加保真度。
读取音频信号。听音频信号的前10秒。
[audioIn, fs] = audioread (“rockguitar - 16 - 96立体声- 72 secs.flac”);声音(audioIn (1:10 * fs,:), fs)
使用WSOLA方法对输入音频信号应用0.75的TSM因子。听产生的音频信号的前10秒。
α= 0.75;audioOut = stretchAudio(audioIn,alpha,“方法”,“wsola”);processingTimeWithDefaultWSOLADelta = toc
processingTimeWithDefaultWSOLADelta = 19.4403
声音(audioOut (1:10 * fs,:), fs)
对输入音频信号应用0.75的TSM因子,这次将WSOLA增量增加到1024。听产生的音频信号的前10秒。
audioOut = stretchAudio(audioIn,alpha,“方法”,“wsola”,“WSOLADelta”, 1024);processingTimeWithIncreasedWSOLADelta = toc
processingTimeWithIncreasedWSOLADelta = 25.5306
声音(audioOut (1:10 * fs,:), fs)
输入参数
输出参数
算法
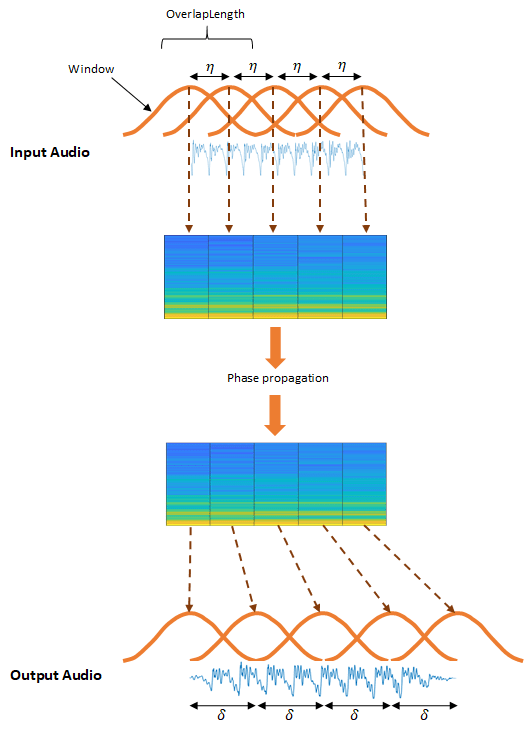
阶段声码器
WSOLA
WSOLA算法是一种基于时域的TSM算法[1][2].WSOLA是重叠和添加(OLA)算法的扩展。在OLA算法中,时域信号在区间η处加窗,其中η=元素个数(.为了构造时间尺度的修正输出音频,窗口间隔为δ,其中δ≈η/α。其中,α为TSM因子窗口) - - -OverlapLengthα输入参数。

OLA算法在重建幅度谱方面做得很好,但会引入窗口间的相位跳跃。WSOLA算法试图通过搜索来平滑相位跳转WSOLADelta样本在η区间的一个窗口,使相位跳跃最小化。该算法迭代搜索最佳窗口,使每个连续窗口相对于之前选择的窗口被选择。

如果WSOLADelta被设置为0,则算法化简为OLA。
参考文献
[1] Driedger, Johnathan和Meinard Müller。音乐信号的时标修正研究进展应用科学.2016年第2期第6卷。
[2] Driedger, Johnathan。“音乐音频信号的时间尺度修正算法”,硕士论文,萨尔兰大学,Saarbrücken,德国,2011。
扩展功能
你也可以从以下列表中选择一个网站: