fitensemble
学习者适合合奏分类和回归
句法
描述
fitensemble可以提高或包决策树学习者或判别分析分类器。该函数还可以训练KNN或判别分析分类器的随机子空间集合。
对于比较简单的界面,配合分类和回归合奏,而是使用fitcensemble和fitrensemble,分别。同时,fitcensemble和fitrensemble提供贝叶斯优化选项。
例子
估计升压乐团的Resubstitution损失
估计一个训练有素的决策树分类集合的替换损失。
加载电离层数据集。
加载电离层;
训练基于AdaBoost,100个学习周期,整个数据集的决策树合奏。
ClassTreeEns = fitensemble(X,Y,'AdaBoostM1',100,“树”);
ClassTreeEns是一个训练有素的ClassificationEnsemble综合识别。
确定累计替换损失(即,the cumulative misclassification error of the labels in the training data).
rsLoss = resubLoss(ClassTreeEns,'模式',“累积”);
rsLoss是一个100×1向量,其中元件k包含第一次之后的替换损失k学习周期。
绘制了学习的周期数的累计resubstitution损失。
情节(rsLoss);xlabel("学习周期的数量");ylabel (“Resubstitution损失”);

一般情况下,随着训练后的分类集合中决策树数目的增加,再替代损失减小。
替换损失的减少可能表明软件对集成进行了合理的训练。然而,你不能通过这种减少来推断整体的预测能力。为了测量集合的预测能力,通过以下方法估计泛化误差:
将数据随机划分为训练集和交叉验证集。通过指定
‘坚持’,holdoutProportion当你用fitensemble。经过训练的合奏
kfoldLoss,其中估计泛化误差。
火车回归集成
使用一个经过训练的,增强的回归树集合来预测汽车的燃油经济性。选择气缸的数量、气缸所取代的体积、马力和重量作为预测指标。然后,使用较少的预测因子训练一个集合,并将其样本内预测精度与第一个集合进行比较。
加载carsmall数据集。将训练数据存储在一个表中。
加载carsmallTBL =表(缸,排气量,马力,体重,MPG);
指定一个回归树模板,该模板使用代理分割来提高在存在南值。
t = templateTree (“代孕”,“上”);
使用LSBoost和100个学习周期训练回归树集成。
Mdl1 = fitensemble(资源描述,“英里”,'LSBoost',100,T);
Mdl1是一个训练有素的RegressionEnsemble回归集成。因为英里/加仑是MATLAB®工作空间中的一个变量,您可以通过输入相同的结果吗
Mdl1 = fitensemble(TBL,MPG, 'LSBoost',100,T);
使用训练有素的回归系综来预测一辆排量为200立方英寸、马力为150马力、重量为3000磅的四缸汽车的燃油经济性。
predMPG =预测(Mdl1,[4 200 150 3000])
predMPG = 22.8462
这些规格的汽车的平均燃油经济性是21.78英里每加仑。
培养使用所有预测新合奏TBL除了位移。
公式=“MPG ~气缸+马力+重量”;Mdl2 = fitensemble(资源描述公式,'LSBoost',100,T);
比较MSEs之间的替换Mdl1和MDL2。
MSE1 = resubLoss(Mdl1)
mse1 = 6.4721
MSE2 = resubLoss(MDL2)
mse2 = 7.8599
在所有预测因子上训练的集合的样本内MSE较低。
估计升压乐团的泛化
估计决策树的训练有素,提高分类集成的泛化误差。
加载电离层数据集。
加载电离层;
培养使用AdaBoostM1决策树合奏,100个学习周期,并随机选择的所述数据的一半。该软件使用验证剩下一半的算法。
RNG(2);%的再现性ClassTreeEns = fitensemble(X,Y,'AdaBoostM1',100,“树”,...“坚持”,0.5);
ClassTreeEns是一个训练有素的ClassificationEnsemble综合识别。
确定累计泛化误差,即,the cumulative misclassification error of the labels in the validation data).
genError = kfoldLoss (ClassTreeEns,'模式',“累积”);
genError是一个100×1向量,其中元件k包含第一个后的泛化误差k学习周期。
画出泛化误差在学习周期数。
情节(genError);xlabel("学习周期的数量");ylabel (“泛化”);
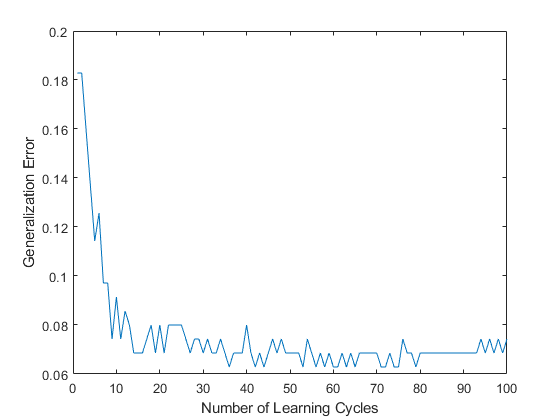
当25个弱学习者组成集成分类器时,累积泛化误差降低到7%左右。
找出一个组合的最佳分割和树的数目
您可以控制树的深度决策树的合奏。您还可以控制在ECOC模型树的深度使用包含决策树二进制学习者MaxNumSplits,MinLeafSize,或MinParentSize名称 - 值对的参数。
在对决策树进行bagging时,
fitensemble默认情况下生成深度决策树。您可以种植较浅的树来减少模型的复杂性或计算时间。在增强决策树时,
fitensemble默认情况下会生成树桩(一个分裂的树)。您可以种植更深的树以获得更好的精度。
加载carsmall数据集。指定变量加速度,位移,马力和重量作为预测,和英里/加仑作为响应。
加载carsmallX = [加速位移马力重量];Y = MPG;
树的深度控制器为促进回归树的默认值是:
1对于MaxNumSplits。此选项增长树桩。5对于MinLeafSize10对于MinParentSize
为了寻找最佳的分割次数:
训练一套成套设备。以指数方式增加后续合奏的最大分裂次数,从残肢到最多n- 1次分裂,其中n为训练样本容量。同时,将每个集成的学习率从1降低到0.1。
交叉验证集成。
估计每个合奏交叉验证均方误差(MSE)。
比较交叉验证的中小企业。具有最低一个执行最佳的合奏,并指示拆分的对所述数据集的最优最大数目,株数,和学习速率。
成长和跨验证了深刻的回归树和树桩。指定因为数据包含缺失值使用替代拆分。这些作为基准。
MdlDeep = fitrtree(X,Y,'CrossVal',“上”,'MergeLeaves',“关闭”,...“MinParentSize”,1“代孕”,“上”);MdlStump = fitrtree (X, Y,“MaxNumSplits”,1'CrossVal',“上”,“代孕”,“上”);
使用150棵回归树训练助推系统。使用5倍交叉验证对集成进行交叉验证。使用序列中的值更改最大拆分数 ,在那里米是这样的: 不大于n- 1,n为训练样本容量。对于每个变量,将学习率调整到集合{0.1,0.25,0.5,1}中的每个值;
n =大小(X, 1);m =层(log2(n - 1));lr = [0.1 0.25 0.5 1];maxNumSplits = 2。^ (0: m);numTrees = 150;Mdl =细胞(元素个数(maxNumSplits),元素个数(lr));rng (1);%的再现性对于k = 1:元素个数(lr);对于J = 1:numel(maxNumSplits);t = templateTree (“MaxNumSplits”maxNumSplits (j),“代孕”,“上”);MDL {J,K} = fitensemble(X,Y,'LSBoost'numTrees t...“类型”,“回归”,'KFold'5,'LearnRate'、lr (k));结束;结束;
计算每个合奏交叉验证MSE。
kflAll = @ (x) kfoldLoss (x,'模式',“累积”);errorCell = cellfun(kflAll,铜牌,'制服'、假);错误=整形(cell2mat(errorCell),[numTrees numel(maxnum) numel(lr)]);errorDeep = kfoldLoss (MdlDeep);errorStump = kfoldLoss (MdlStump);
情节如何交叉验证MSE表现为在几个歌舞团,深树的整体增加树木的数量,而树墩。绘制相对于曲线在同一情节的学习速度,并绘制单独地块的不同树的复杂性。选择树的复杂性水平的一个子集。
mnsPlot = [1轮(numel(maxNumSplits)/ 2)numel(maxNumSplits)];数字;对于K = 1:3;副区(2,2,k)的;图(挤压(错误(:,mnsPlot(K),:))“线宽”,2);轴紧;持有在;H = GCA;情节(h.XLim,[errorDeep errorDeep]“。b”,“线宽”,2);情节(h.XLim,[errorStump errorStump]“r”,“线宽”,2);情节(h.XLim,分钟(分钟(误差(:,mnsPlot(K),。)))* [1 1],'--k');h.YLim = [10 50];xlabel树木的数量;ylabel“旨在MSE”;标题(sprintf ('MaxNumSplits =%0.3克'maxNumSplits (mnsPlot (k))));持有离;结束;HL =图例([cellstr(num2str(LR”,'学习率=%0.2F'));...“深树”;“树桩”;“闵。MSE”]);hL.Position (1) = 0.6;
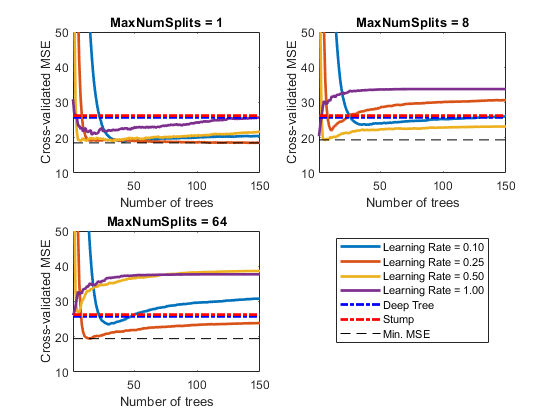
每条曲线都包含一个最小的交叉验证MSE,该MSE发生在集成中树的最优数量上。
确定产生最低MSE的最大分割数、树的数量和学习率。
[minErr, minErrIdxLin] = min(错误(:));[idxNumTrees, idxMNS idxLR] = ind2sub(大小(错误),minErrIdxLin);流(“\ nMin。MSE = % 0.5 f 'minErr)
最小MSE = 18.50574
流(“\ nOptimal参数值:\ nNum。树木=%d”,idxNumTrees);
最佳参数值:民。树木= 12
流('\ nmaxnum= %d\nLearning Rate = %0.2f\n',...maxNumSplits(idxMNS),LR(idxLR))
MaxNumSplits = 4学习率= 0.25
有关优化此集成的另一种方法,请参阅优化一个增强的回归集成。
输入参数
输出参数
提示
n了解可以从几十到几千元不等。通常情况下,具有良好的预测能力合奏从几百需要到几千个弱学习。不过,你不必一次训练的合奏了很多次。您可以通过不断增长的几十个学生开始,检查合奏表演,然后,如果必要的话,使用培养出更多的弱学习的简历对于分类问题,或者的简历回归问题。合奏表演取决于合奏的设置和弱学习者的设置。也就是说,如果您用默认参数指定了弱学习者,那么集成的性能就会很差。因此,像集成设置一样,使用模板调整弱学习者的参数并选择最小化泛化误差的值是一个很好的实践。
如果您指定重新取样使用
重新取样,那么它是很好的做法,重新采样到整个数据集。也就是说,使用默认设置1对于FResample。在分类问题中(即,
类型是'分类'):如果ensemble-aggregation方法(
方法)是“包”和:误分类成本(
成本)是高度不均衡,那么,在袋的样品,该软件过采样从具有较大的点球类独特的看法。类先验概率(
之前)是高度扭曲,该软件从具有较大的先验概率类的过采样独特的看法。
对于较小的样品尺寸,这些组合可导致来自具有大的惩罚或先验概率的类外的袋观察的低的相对频率。因此,所估计的外的包误差是高度可变的,它可以是难以解释。为了避免大的估计出的袋误差方差,特别是用于小样本大小,使用设定一个更平衡的误分类成本矩阵
成本或者用一个不那么倾斜的先验概率向量之前。因为一些输入和输出参数的顺序对应于不同类别的训练数据,这是很好的做法使用来指定类顺序
一会名称-值对的论点。要快速确定类的顺序,请从未分类的训练数据中删除所有观察结果(即缺少标签),获取并显示所有不同类的数组,然后为其指定数组
一会。例如,假设响应变量(Y)是标签的单元阵列。该代码指定了变量的类顺序类名。Ycat =分类(Y);一会=类别(Ycat)
分类分配<定义>未分类的意见和类别不包括<定义>从它的输出。因此,如果您对标签的单元数组使用此代码,或者对分类数组使用类似的代码,那么您不必删除缺少标签的观察结果来获得不同类的列表。要指定从代表最低的标签到代表最多的标签的类顺序,然后快速确定类顺序(如前一项所示),但是在将列表传递给之前,要按频率排列列表中的类
一会。从前面的例子中可以看出,这段代码指定了从最低到最高的类顺序classNamesLH。Ycat =分类(Y);一会=类别(Ycat);频率= countcats (Ycat);[~,idx] =(频率)进行排序;classNamesLH =一会(idx);
算法
有关ensemble-aggregation算法的详细信息,请参阅整体算法。
如果您指定
方法成为一个增强算法学习者成为决策树,软件就会成长树桩默认。的决定残端是连接到两个终端,叶节点一个根节点。您可以通过指定调整树深度MaxNumSplits,MinLeafSize和MinParentSize使用的名称-值对参数templateTree。fitensemble通过对误分类代价大的类进行过采样和对误分类代价小的类进行欠采样来生成袋中样本。因此,袋外样本中来自具有较大误分类成本的类的观察值较少,而来自具有较小误分类成本的类的观察值较多。如果您使用一个小的数据集和一个高度倾斜的成本矩阵来训练一个分类集合,那么每个类的out-of-bag观察值可能很低。因此,估计的out-of-bag误差可能有很大的方差,并且很难解释。对于具有较大先验概率的类,也会出现相同的现象。对于RUSBoost ensemble-aggregation方法(
方法)、名称-值对参数RatioToSmallest指定每个类相对于最低表示类的抽样比例。例如,假设训练数据中有两个类:一个和B。一个有100个观测和B有10个观测值。此外,假设代表性最低的类有米训练数据中的观察结果。如果你设置
“RatioToSmallest”, 2, 然后年代*米2 * 10=20.。所以,fitensemble列车采用从第20类观察每位学员一个和从类20周的观察B。如果你设置‘RatioToSmallest’, (2 - 2),则得到相同的结果。如果你设置
'RatioToSmallest',[2,1], 然后s1*米2 * 10=20.和s2*米1 * 10=10。所以,fitensemble列车采用从第20类观察每位学员一个和课堂上的10次观察B。
对于决策树,并为双核系统和上述的合奏,
fitensemble使用Intel并行化培训®线程构建模块(TBB)。如欲了解有关英特尔TBB的详细信息,请参阅https://software.intel.com/en-us/intel-tbb。
参考
[1] Breiman,L.“套袋预测因子”。机器学习。第26卷,第123-140页,1996年。
[2] Breiman, L.《随机森林》。机器学习。卷。45,第5-32,2001年。
一个更稳健的提升算法。的arXiv:0905.2138v1,2009年。
[4] Freund, y。和r。e。Schapire。“在线学习决策理论的推广与应用。”计算机与系统科学卷。55,第119-139,1997。
贪婪函数近似:一个梯度提升机。统计年鉴卷。29,第5号,第1189至1232年,2001。
[6] Friedman, J., T. Hastie,和R. Tibshirani。加法逻辑回归:促进的统计观点。统计年鉴卷。28,第2号,第337-407,2000。
[7] Hastie的,T.,R. Tibshirani,和J.弗里德曼。统计学习的要素section edition,施普林格,纽约,2008。
[8]何,T. K.“用于构建决策森林随机子空间方法”。IEEE交易模式分析与机器智能,第20卷,第8期,第832-844页,1998年。
[9] Schapire,R. E.,Y.弗氏,P.巴特利特和W.S.李。“促进保证金:为投票方法有效性的新的解释。”统计年鉴,第26卷,第5期,第1651-1686页,1998年。
b . Seiffert, C., T. Khoshgoftaar, J. Hulse,和A. Napolitano。“RUSBoost:在训练数据不准确的情况下提高击穿能力。”第十九届模式识别国际会议,第1-4页,2008年。
[11] Warmuth, M., J. Liao,和G. Ratsch。“完全纠正了提高利润率的算法。”Proc, 23日国际。机器学习,ACM,纽约,第1001-1008页,2006年。
另请参阅
ClassificationBaggedEnsemble|ClassificationEnsemble|ClassificationPartitionedEnsemble|RegressionBaggedEnsemble|RegressionEnsemble|RegressionPartitionedEnsemble|templateDiscriminant|templateKNN|templateTree
介绍了R2011a
你也可以从以下列表中选择一个网站:
