fitSVMPosterior
拟合后验概率
语法
描述
ScoreSVMModel= fitSVMPosterior (SVMModel)ScoreSVMModel,它是一个经过训练的支持向量机(SVM)分类万博1manbetx器,包含用于两类学习的最优分数到后验概率转换函数。
该软件使用支持向量机分类器拟合适当的分数-后验概率转换函数SVMModel,并使用存储的预测数据进行交叉验证(SVMModel。X)和类标签(SVMModel。Y).变换函数计算观察结果归为正类的后验概率(SVMModel.Classnames (2)).
如果类是不可分割的,那么变换函数就是乙状结肠函数.
如果这些类是完全可分离的,变换函数就是阶跃函数.
在两类学习中,如果其中一个类的相对频率为0,则变换函数为常数函数.
fitSVMPosterior不适合单课学习。如果
SVMModel是一个ClassificationSVM分类器,然后软件通过10倍交叉验证估计最优转换函数[1].否则,SVMModel一定是ClassificationPartitionedModel分类器。SVMModel指定交叉验证方法。软件将最优变换函数存储在
ScoreSVMModel。ScoreTransform.
ScoreSVMModel= fitSVMPosterior (SVMModel,资源描述,ResponseVarName)SVMModel.该软件利用表中的预测数据估计得分转换函数资源描述和类标签资源描述。ResponseVarName.
ScoreSVMModel= fitSVMPosterior (SVMModel,资源描述,Y)SVMModel.该软件利用表中的预测数据估计得分转换函数资源描述和类标签Y.
ScoreSVMModel= fitSVMPosterior (SVMModel,X,Y)SVMModel.该软件利用预测数据估计得分转换函数X和类标签Y.
ScoreSVMModel= fitSVMPosterior (<年代pan class="argument_placeholder">___名称,值)使用一个或多个指定的其他选项名称,值提供的Pair参数SVMModel是一个ClassificationSVM分类器。例如,您可以指定要使用的折叠数k-fold交叉验证。
[)此外,返回转换函数参数(ScoreSVMModel,ScoreTransform= fitSVMPosterior(<年代pan class="argument_placeholder">___ScoreTransform)使用前面语法中的任何输入参数。
例子
可分离类的得分-后验概率函数拟合
载入费雪的虹膜数据集。使用花瓣的长度和宽度训练分类器,并从数据中去除virginica物种。
负载<年代pan style="color:#A020F0">fisheririsclassKeep = ~strcmp(物种,<年代pan style="color:#A020F0">“virginica”);X = meas(classKeep,3:4);y =物种(classKeep);gscatter (X (: 1) X (:, 2), y);标题(<年代pan style="color:#A020F0">“虹膜测量散点图”)包含(<年代pan style="color:#A020F0">“花瓣长度”) ylabel (<年代pan style="color:#A020F0">“花瓣宽度”)传说(<年代pan style="color:#A020F0">“Setosa”,<年代pan style="color:#A020F0">“多色的”)
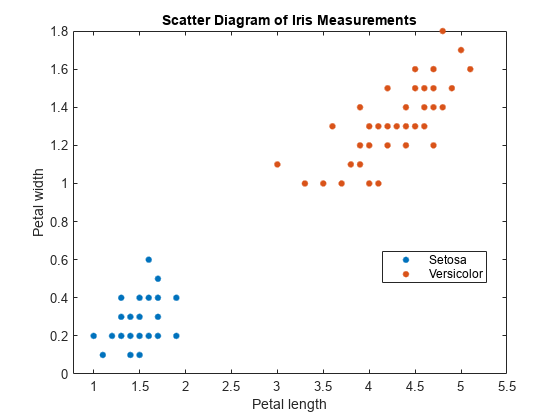
这些类是完全可分离的。因此,分数变换函数是一个阶跃函数。
使用这些数据训练SVM分类器。使用10倍交叉验证(默认)交叉验证分类器。
rng (1);CVSVMModel = fitcsvm(X,y,<年代pan style="color:#A020F0">“CrossVal”,<年代pan style="color:#A020F0">“上”);
CVSVMModel是经过训练的ClassificationPartitionedModel支持向量机分类器。
估计将分数转换为后验概率的阶跃函数。
[ScoreCVSVMModel,ScoreParameters] = fitsvm后部(CVSVMModel);
警告:类是完全分离的。最佳得分-后验变换是一个阶梯函数。
fitSVMPosterior做以下工作:
使用软件存储的数据
CVSVMModel来拟合变换函数每当类是可分离的时发出警告
存储阶跃函数
ScoreCSVMModel。ScoreTransform
显示评分函数类型及其参数值。
ScoreParameters
ScoreParameters =<年代pan class="emphasis">带有字段的结构:类型:'step' LowerBound: -0.8431 UpperBound: 0.6897 PositiveClassProbability: 0.5000
ScoreParameters是一个包含四个字段的结构数组:
分数转换函数类型(
类型)班级负边界对应的分数(
下界)班级正边界对应的分数(
UpperBound)正类概率(
PositiveClassProbability)
由于类是可分离的,阶梯函数将分数转换为两者之一0或1,即观察到的是彩色虹膜的后验概率。
不可分类的得分-后验概率函数拟合
加载电离层数据集。
负载<年代pan style="color:#A020F0">电离层
这个数据集的类是不可分离的。
训练SVM分类器。使用10倍交叉验证(默认)进行交叉验证。标准化预测器并指定类顺序是一种很好的做法。
rng (1)<年代pan style="color:#228B22">%用于重现性CVSVMModel = fitcsvm(X,Y,<年代pan style="color:#A020F0">“类名”, {<年代pan style="color:#A020F0">“b”,<年代pan style="color:#A020F0">‘g’},<年代pan style="color:#A020F0">“标准化”,真的,<年代pan style="color:#0000FF">...“CrossVal”,<年代pan style="color:#A020F0">“上”);ScoreTransform = CVSVMModel。ScoreTransform
ScoreTransform = 'none'
CVSVMModel是经过训练的ClassificationPartitionedModel支持向量机分类器。正类是‘g’.的ScoreTransform属性是没有一个.
估计将观察评分映射到被分类为的观察的后验概率的最佳评分函数‘g’.
[ScoreCVSVMModel,ScoreParameters] = fitsvm后部(CVSVMModel);ScoreTransform = ScoreCVSVMModel。ScoreTransform
ScoreTransform = '@(S)sigmoid(S,-9.481373e-01,-1.218931e-01)'
ScoreParameters
ScoreParameters =<年代pan class="emphasis">带有字段的结构:斜率:-0.9481截距:-0.1219
ScoreTransform为最优分数变换函数。ScoreParameters包含得分变换函数、斜率估计和截距估计。
你可以估计测试样本的后验概率ScoreCVSVMModel来kfoldPredict.
估计测试样本的后验概率
估计支持向量机算法测试集的正类后验概率。
加载电离层数据集。
负载<年代pan style="color:#A020F0">电离层
训练SVM分类器。指定20%的抵制样本。标准化预测器并指定类顺序是一种很好的做法。
rng (1)<年代pan style="color:#228B22">%用于重现性CVSVMModel = fitcsvm(X,Y,<年代pan style="color:#A020F0">“坚持”, 0.2,<年代pan style="color:#A020F0">“标准化”,真的,<年代pan style="color:#0000FF">...“类名”, {<年代pan style="color:#A020F0">“b”,<年代pan style="color:#A020F0">‘g’});
CVSVMModel是经过训练的ClassificationPartitionedModel旨在分类器。
估计将观察评分映射到被分类为的观察的后验概率的最佳评分函数‘g’.
ScoreCVSVMModel = fitsvm后部(CVSVMModel);
ScoreSVMModel是经过训练的ClassificationPartitionedModel交叉验证的分类器包含从训练数据估计的最优分数转换函数。
估计样本外正类后验概率。显示前10个样本外观察结果。
[~,OOSPostProbs] = kfoldPredict(ScoreCVSVMModel);indx = ~isnan(OOSPostProbs(:,2));hoObs = find(indx);<年代pan style="color:#228B22">坚持观察数字OOSPostProbs = [hoObs, OOSPostProbs(indx,2)];表(OOSPostProbs (1:10, 1), OOSPostProbs (1:10), 2),<年代pan style="color:#0000FF">...“VariableNames”, {<年代pan style="color:#A020F0">“ObservationIndex”,<年代pan style="color:#A020F0">“PosteriorProbability”})
ans =<年代pan class="emphasis">10×2表ObservationIndex PosteriorProbability ________________ ____________________ 6 0.17379 7 0.89638 8 0.0076606 9 0.91603 16 0.026714 22 4.6086e-06 23 0.9024 24 2.4131e-06 38 0.00042687 41 0.86427
输入参数
输出参数
更多关于
提示
该过程描述了一种预测正类后验概率的方法。
通过传递数据来训练SVM分类器
fitcsvm.结果是一个经过训练的SVM分类器,例如SVMModel,用来存储数据。软件设置分数转换函数属性(SVMModel。ScoreTransformation)没有一个.传递经过训练的SVM分类器
SVMModel来fitSVMPosterior或fitPosterior.结果,如:ScoreSVMModel,为训练后的SVM分类器SVMModel,除了软件设置ScoreSVMModel。ScoreTransformation到最优分数的变换函数。传递预测器数据矩阵和经过训练的SVM分类器,其中包含最优分数转换函数(
ScoreSVMModel)预测.的第二个输出参数中的第二列预测存储与预测器数据矩阵的每一行对应的正类后验概率。如果跳过第二步,那么
预测返回正的类得分而不是正的类后验概率。
在拟合后验概率之后,可以生成预测新数据标签的C/ c++代码。生成C/ c++代码需要<年代pan class="entity">MATLAB<年代up>®编码器™.详情请参见代码生成简介.
算法
如果您重新估计得分-后验概率转换函数,也就是说,如果您将SVM分类器传递给fitPosterior或fitSVMPosterior和它的ScoreTransform财产不是没有一个,然后软件:
显示警告
将原始转换函数重置为
“没有”在估计新的之前
参考文献
[1] Platt, J.“支持向量机的概率输出和与正则化似然方法的比较”。万博1manbetx:大余量分类器的研究进展.剑桥,马萨诸塞州:麻省理工学院出版社,2000年,第61-74页。
版本历史
在R2014a中介绍
另请参阅
ClassificationSVM|<年代pan itemscope itemtype="//www.tianjin-qmedu.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">CompactClassificationSVM|<年代pan itemscope itemtype="//www.tianjin-qmedu.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">ClassificationPartitionedModel|<年代pan itemscope itemtype="//www.tianjin-qmedu.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">fitcsvm|<年代pan itemscope itemtype="//www.tianjin-qmedu.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">预测|<年代pan itemscope itemtype="//www.tianjin-qmedu.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">fitPosterior|<年代pan itemscope itemtype="//www.tianjin-qmedu.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">fitPosterior|<年代pan itemscope itemtype="//www.tianjin-qmedu.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">kfoldPredict
您也可以从以下列表中选择网站: