识别,对象检测和语义细分
识别,分类,语义图像分割,使用功能检测对象检测以及使用CNN,Yolo和SSD进行深度学习对象检测
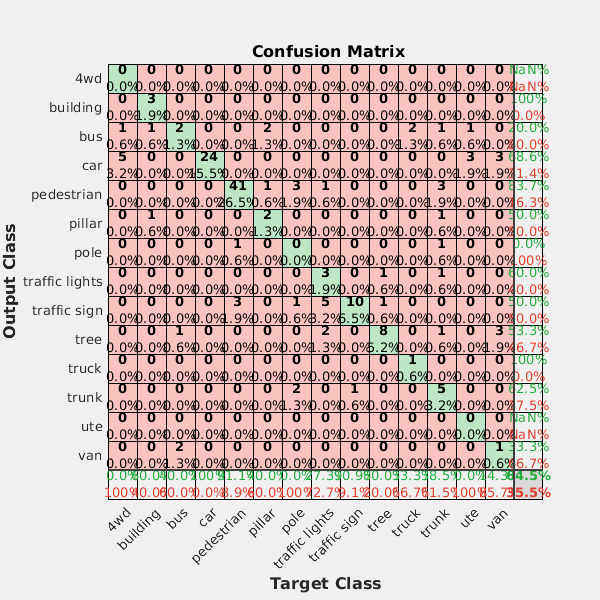
计算机视觉工具箱™支持几种用于图像分类,对象检测,万博1manbetx语义细分和识别的方法,包括:
深度学习和卷积神经网络(CNN)
一袋功能
模板匹配
斑点分析
Viola-Jones算法
CNN是一种流行的深度学习体系结构,它会直接从图像数据中自动学习有用的功能表示。功能袋将图像功能编码为适合图像分类和图像检索的紧凑表示形式。模板匹配使用小图像或模板在较大图像中找到匹配区域。BLOB分析使用分割和BLOB属性来识别感兴趣的对象。Viola-Jones算法使用类似HAAR的功能和一系列分类器来识别物体,包括面部,鼻子和眼睛。您可以训练此分类器以识别其他对象。
类别
特色示例






您还可以从以下列表中选择一个网站:
美洲
- AméricaLatina(Español)
- 加拿大(英语)
- 美国(英语)