我认为过拟合的原因可能是由于每个类的特征数量较少和数据集不平衡。此外,对于不平衡数据集问题,您可以探索加权交叉熵损失或焦点损失,而不是交叉熵损失函数。有关详细信息,请参阅的文档
focalLossLayer
.
序列标注的方法支持向量机(SVM)分类万博1manbetx
18次浏览(过去30天)
显示旧的注释
我是一个机器学习的初学者,试图开发一个模型来预测一个病人在医院里根据他们的心率,呼吸率和血氧饱和度提出的抱怨。我有三个类别,“O”,“M”,“W”,每个类别都有他们停留期间的心率(hr),反应率(rr)和血氧(o2)读数。序列的长度因主题而异,我目前将它们组织成一个细胞数组,每个细胞包含3个生命体征向量。
最初,我试图用以下层和选项实现一个LSTM:
miniBatchSize = 13;每次迭代使用的观察数%
inputSize = 3;%特征数(rr,hr,o2)
numHiddenUnits = 100;% LSTM层中的隐藏单元
numClasses = 3;分类选项的百分比
层= [...
sequenceInputLayer (inputSize)
bilstmLayer (numHiddenUnits“OutputMode”,“最后一次”)
dropoutLayer (0.3)
fullyConnectedLayer (numClasses)
softmaxLayer
classificationLayer]
maxEpochs = 100;
选项= trainingOptions(“亚当”,...
“ExecutionEnvironment”,“图形”,...
“GradientThreshold”, 1...
“MaxEpochs”maxEpochs,...
“MiniBatchSize”miniBatchSize,...
“SequenceLength”,“最长”,...
“洗牌”,“永远”,...
“详细”0,...
“阴谋”,“训练进步”,...
“LearnRateSchedule”,“分段”,...
“LearnRateDropPeriod”3,...
“LearnRateDropFactor”, 0.5,...
“InitialLearnRate”, 0.001);
net = trainNetwork(XTrain,YTrain',图层,选项);
这是基于什么
//www.tianjin-qmedu.com/help/deeplearning/ug/classify-sequence-data-using-lstm-networks.html。
这并不是很好,准确性和损失都在训练中波动:
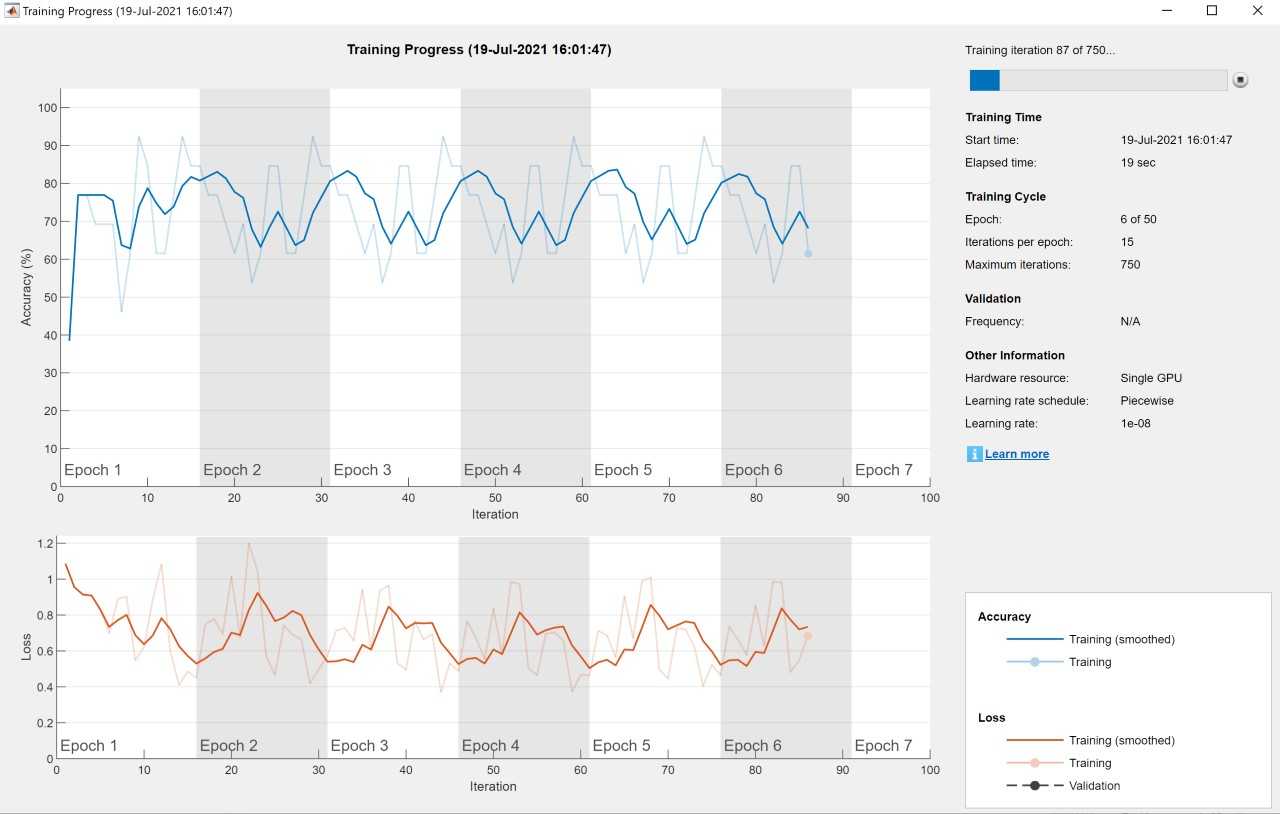
它也倾向于“过拟合”数据,并假设所有的遵从者都是“O”类,因为该类占训练集和测试集的大约75%。
我问了一个比我更熟悉机器学习的同事,他们建议使用SVM对序列进行分类。我的问题是我还没有找到一种方法来创建一个多类序列标记支持向量机分类器在matlab。我找到的所有示例都只使用选择特性,而且大多数都集中在二进制分类器上。
我的问题是,有没有人知道如何在matlab上创建一个多类序列来标记svm分类器,或者有任何资源或示例的链接,其中类似的事情已经完成。此外,如果这是不可能的或不是最好的行动方案,那么有没有人有任何想法,为什么我的LSTM网络有问题,和一些修复,我可以尝试或链接/资源。感谢。
0评论
另请参阅
您也可以从以下列表中选择一个网站: