可视化不同分类器的决策曲面
每个分类算法生成不同的决策规则。这些规则可以以决策表的形式可视化。此示例演示如何可视化不同分类算法的决策面。
加载数据以查看不同鸢尾属物种的萼片测量值的差异。可以使用包含萼片测量值的两列。
净负荷鱼腥草X=平均值(:,1:2);y=分类(物种);标签=类别(y);图(1)gscatter(X(:,1),X(:,2),物种,“rgb”,“osd”); xlabel(“萼片长度”); 伊拉贝尔(“萼片宽度”);

分类器{1}=NaiveBayes.fit(X,y);分类器{2}=ClassificationDiscriminant.fit(X,y);分类器{3}=ClassificationTree.fit(X,y);分类器{4}=ClassificationKNN.fit(X,y);分类器名称={“天真的贝叶斯”,“判别分析”,“分类树”,“最近的邻居”};
网格用于在实际数据值的某些范围内创建跨越整个空间的点网格。每个分类器用于对网格中的所有数据进行分类。
[xx1,xx2]=网格网格(4:01:8,2:01:4.5);图(2)对于ii=1:numel(分类器)ypred=predict(分类器{ii},[xx1(:)xx2(:)];h(ii)=子批次(2,2,ii);gscatter(xx1(:),xx2(:),ypred,“rgb”); 标题(名称{ii},“字体大小”(15)图例关轴牢固的终止图例(h(1),标签,“位置”,[0.35,0.01,0.35,0.05],“方向”,“水平”)
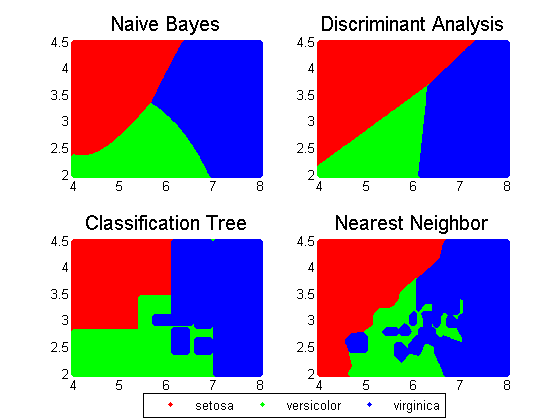
Fisher的虹膜数据包括对150个虹膜标本的萼片长度、萼片宽度、花瓣长度和花瓣宽度的测量。三个物种各有50个标本。此数据集随统计和机器学习工具箱™.