列车网络的使用自定义训练循环
这个例子展示了如何训练网络,把手写的数字和一个定制的学习速率的时间表。
你可以训练使用的大多数类型的神经网络trainNetwork和trainingOptions功能。如果trainingOptions函数不提供你需要的选项(例如,一个定制的学习速率的时间表),然后你可以定义自己的自定义训练循环使用dlarray和dlnetwork对象自动分化。为一个例子,演示如何培训pretrained深学习网络使用trainNetwork功能,请参阅学习使用Pretrained网络传输。
训练一个深层神经网络是一种优化的任务。通过考虑一个神经网络作为一个函数 ,在那里 网络的输入, 可学的参数集,您可以优化吗 减少一些损失值基于训练数据。例如,优化可学的参数 这样,对于一个给定的输入 与相应的目标 ,他们之间的误差最小化预测 和 。
取决于使用的损失函数类型的任务。例如:
对于分类任务,您可以最小化之间的交叉熵误差预测和目标。
对于回归的任务,您可以最小化之间的均方误差预测和目标。
您可以使用梯度下降优化目标:最小化损失 通过迭代更新可学的参数 通过采取措施对最小使用渐变的损失对可学的参数。梯度下降算法更新可学的参数通常使用的更新一步的变体形式 ,在那里 是迭代数, 是学习速率, 表示渐变(衍生品的损失对可学的参数)。
这个例子列车网络分类手写数字的基于时间的衰减学习速率的时间表:对于每一次迭代,求解器使用的学习速率 ,在那里t是迭代数, 最初的学习速率,k是衰减的。
负荷训练数据
数字数据加载图像数据存储使用imageDatastore功能和指定包含图像数据的文件夹。
dataFolder = fullfile (toolboxdir (“nnet”),“nndemos”,“nndatasets”,“DigitDataset”);imd = imageDatastore (dataFolder,…IncludeSubfolders = true,…。LabelSource =“foldernames”);
分区数据为训练集和验证集。留出10%的验证使用的数据splitEachLabel函数。
[imdsTrain, imdsValidation] = splitEachLabel (imd, 0.9,“随机”);
在这个例子中使用的网络28-by-28-by-1需要输入图像的大小。自动调整训练图像,使用一个增强图像数据存储。指定额外增加操作执行培训图片:随机翻译5像素的图像在水平和垂直轴。数据增加有助于防止网络过度拟合和记忆的训练图像的细节。
inputSize = [28 28 1];pixelRange = 5 [5];imageAugmenter = imageDataAugmenter (…RandXTranslation = pixelRange,…RandYTranslation = pixelRange);augimdsTrain = augmentedImageDatastore (inputSize (1:2), imdsTrain, DataAugmentation = imageAugmenter);
自动调整验证图像不执行进一步的数据,使用一个增强的图像数据存储不指定任何额外的预处理操作。
augimdsValidation = augmentedImageDatastore (inputSize (1:2), imdsValidation);
确定训练数据的类的数量。
类=类别(imdsTrain.Labels);numClasses =元素个数(类);
定义网络
定义网络图像分类。
图像输入,指定一个图像输入层与输入训练数据匹配的大小。
不正常的图像输入,设置
归一化选择输入层“没有”。指定三个convolution-batchnorm-ReLU块。
垫卷积的输入层,通过设置的输出具有相同的大小
填充选项“相同”。卷积第一层指定20过滤器的大小5。对于剩下的卷积层指定20过滤器的大小3。
对于分类,指定一个完全连接层与大小匹配的类的数量
输出映射到概率,包括softmax层。
当培训网络使用自定义循环,不包括一个输出层。
层= [imageInputLayer (inputSize正常化=“没有”)convolution2dLayer(5、20、填充=“相同”)batchNormalizationLayer reluLayer convolution2dLayer(3、20、填充=“相同”)batchNormalizationLayer reluLayer convolution2dLayer(3、20、填充=“相同”)batchNormalizationLayer reluLayer fullyConnectedLayer (numClasses) softmaxLayer];
创建一个dlnetwork数组对象的层。
净= dlnetwork(层)
网= dlnetwork属性:层:[12×1 nnet.cnn.layer.Layer]连接:[11×2表]可学的:[14×3表]状态:[6×3表]InputNames: {“imageinput”} OutputNames: {“softmax”}初始化:1观点总结总结。
定义模型损失函数
训练一个深层神经网络是一种优化的任务。通过考虑一个神经网络作为一个函数 ,在那里 网络的输入, 可学的参数集,您可以优化吗 减少一些损失值基于训练数据。例如,优化可学的参数 这样,对于一个给定的输入 与相应的目标 ,他们之间的误差最小化预测 和 。
创建函数modelLoss中列出,损失函数模型的例子中,这需要作为输入dlnetwork对象,mini-batch输入数据与相应的目标,并返回损失,损失的梯度对可学的参数,和网络状态。
指定培训选项
火车十世mini-batch大小为128。
numEpochs = 10;miniBatchSize = 128;
指定的选项个优化。指定一个初始学习衰变率0.01,0.01,0.9和动量。
initialLearnRate = 0.01;衰变= 0.01;动量= 0.9;
火车模型
创建一个minibatchqueue对象流程和管理mini-batches图像在训练。为每个mini-batch:
使用自定义mini-batch预处理功能
preprocessMiniBatch(在这个例子中定义)转换编码的标签在一个炎热的变量。格式的图像数据维度标签
“SSCB”(空间、空间、通道、批)。默认情况下,minibatchqueue把数据转换为对象dlarray对象与基本类型单。没有格式的类标签。火车在GPU如果一个是可用的。默认情况下,
minibatchqueue将每个输出转换为对象gpuArray如果一个GPU是可用的。使用GPU需要并行计算工具箱™和支持GPU设备。万博1manbetx支持设备的信息,请参阅万博1manbetxGPU计算的需求(并行计算工具箱)。
兆贝可= minibatchqueue (augimdsTrain,…MiniBatchSize = MiniBatchSize,…MiniBatchFcn = @preprocessMiniBatch,…MiniBatchFormat = [“SSCB””“]);
个解算器初始化速度参数。
速度= [];
计算迭代的总数的培训进度监控。
numObservationsTrain =元素个数(imdsTrain.Files);numIterationsPerEpoch =装天花板(numObservationsTrain / miniBatchSize);numIterations = numEpochs * numIterationsPerEpoch;
初始化TrainingProgressMonitor对象。因为计时器开始创建监视器对象时,确保你创建对象接近的训练循环。
监控= = trainingProgressMonitor(指标“损失”信息= (“时代”,“LearnRate”),包含=“迭代”);
列车网络使用自定义训练循环。对于每一个时代,洗牌和遍历mini-batches数据的数据。为每个mini-batch:
损失评估模型,使用渐变和状态
dlfeval和modelLoss功能和更新网络状态。确定基于时间的学习速率衰减学习速率的时间表。
更新网络参数使用
sgdmupdate函数。更新损失,学习速度,训练进度监控和时代价值。
停止,如果停止房地产是正确的。停止的属性值
TrainingProgressMonitor对象更改为真,当你点击停止按钮。
时代= 0;迭代= 0;%循环时期。而时代< numEpochs & & ~班长。停止时代=时代+ 1;%洗牌数据。洗牌(兆贝可);%在mini-batches循环。而hasdata(兆贝可)& & ~班长。停止迭代=迭代+ 1;% mini-batch读取的数据。[X, T] =下一个(兆贝可);%评估模型梯度、州和使用dlfeval和损失% modelLoss功能和更新网络状态。(损失、渐变、状态)= dlfeval (@modelLoss,净,X, T);网。=状态;%确定为基于时间的学习速率衰减学习速率的时间表。learnRate = initialLearnRate /(1 +衰变*迭代);%更新使用个优化网络参数。(净、速度)= sgdmupdate(净、渐变速度,learnRate动量);%更新培训进度监控。recordMetrics(监控、迭代损失=损失);updateInfo(监控、时代=时代LearnRate = LearnRate);班长。进步= 100 *迭代/ numIterations;结束结束
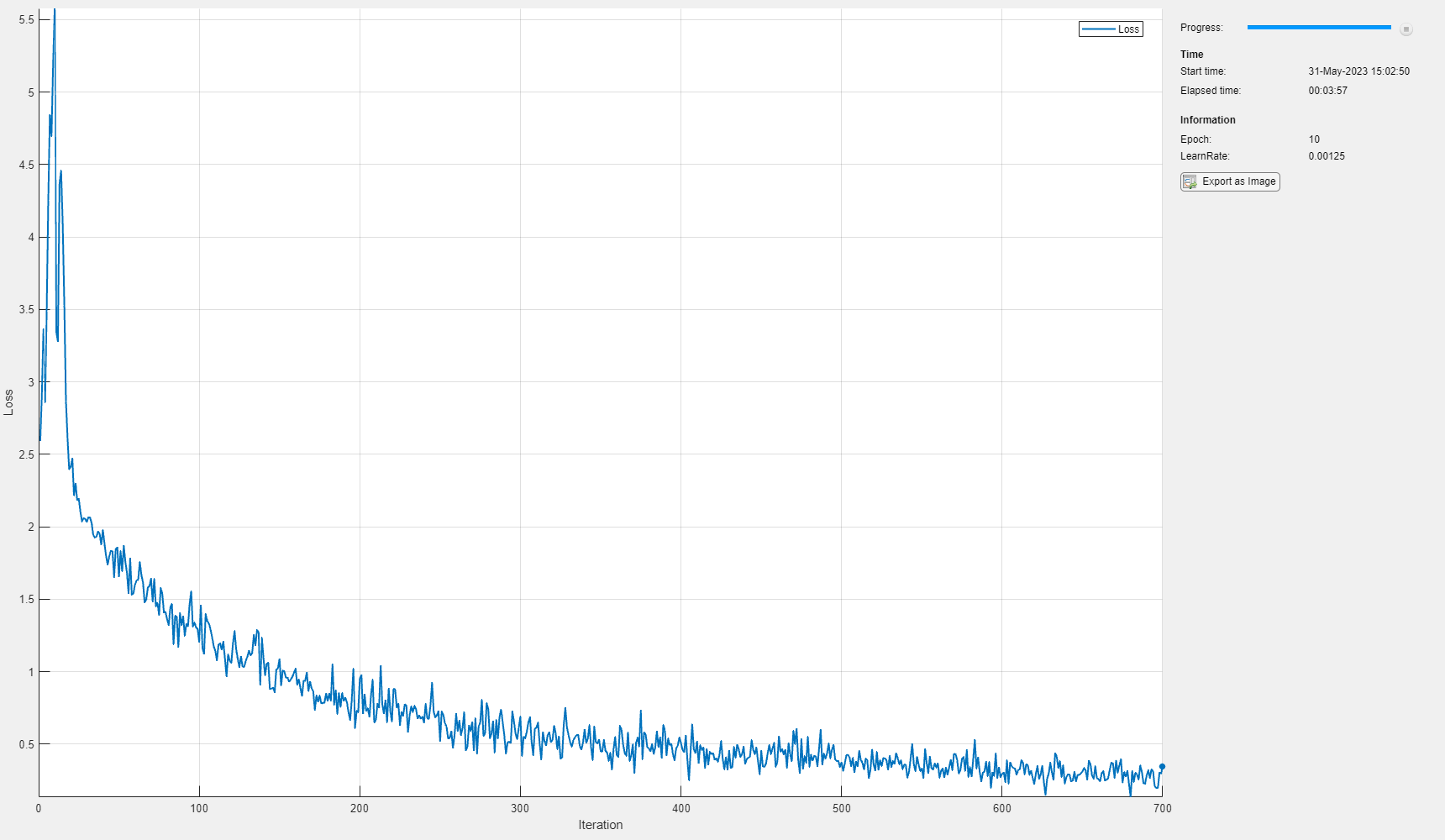
测试模型
测试模型的分类精度比较预测验证集和真正的标签。
训练后,使预测新数据不需要标签。创建minibatchqueue对象只包含测试数据的预测:
忽略标签测试,设置输出的数量mini-batch队列1。
指定相同的mini-batch大小用于培训。
预处理预测使用
preprocessMiniBatchPredictors函数,列出的例子。对于单一的输出数据存储,指定mini-batch格式
“SSCB”(空间、空间、通道、批)。
numOutputs = 1;mbqTest = minibatchqueue (augimdsValidation numOutputs,…MiniBatchSize = MiniBatchSize,…MiniBatchFcn = @preprocessMiniBatchPredictors,…MiniBatchFormat =“SSCB”);
使用循环mini-batches和分类图像modelPredictions函数,列出的例子。
欧美= modelPredictions(净、mbqTest、类);
评估分类精度。
tt = imdsValidation.Labels;精度=意味着(tt = =次)
精度= 0.9750
图表可视化预测在一个混乱。
次图confusionchart (tt)
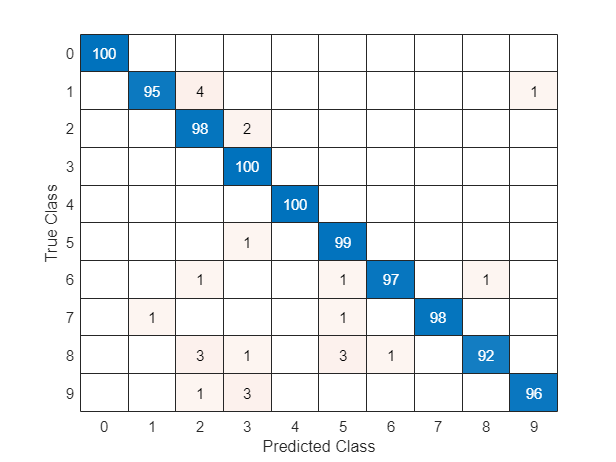
大值对应的类的对角线显示准确的预测。大值对应的类之间的非对角的表示强烈的困惑。
万博1manbetx支持功能
损失函数模型
的modelLoss函数接受一个dlnetwork对象净mini-batch的输入数据X与相应的目标T并返回损失,损失的梯度参数对可学的净,和网络状态。自动计算梯度,使用dlgradient函数。
函数(损失、渐变、状态)= modelLoss(净,X, T)%通过网络转发数据。[Y,状态]=前进(净,X);%计算熵的损失。损失= crossentropy (Y, T);%计算梯度的损失对可学的参数。梯度= dlgradient(损失、net.Learnables);结束
模型的预测函数
的modelPredictions函数接受一个dlnetwork对象净,一个minibatchqueue的输入数据兆贝可网络类,计算模型遍历所有数据的预测minibatchqueue对象。这个函数使用onehotdecode函数找到预测类最高的分数。
函数Y = modelPredictions(净、兆贝可类)Y = [];%在mini-batches循环。而hasdata(兆贝可)X =(兆贝可);%进行预测。成绩=预测(净,X);%解码标签和附加到输出。标签= onehotdecode(成绩、类1)';Y = [Y;标签);结束结束
小批预处理功能
的preprocessMiniBatch函数进行预处理的mini-batch预测和标签使用以下步骤:
使用预处理的图像
preprocessMiniBatchPredictors函数。从传入单元阵列提取标签数据和连接到一个直言沿着二维数组。
一个炎热的分类标签编码成数字数组。编码的第一个维度产生一个相匹配的形状编码阵列网络输出。
函数[X, T] = preprocessMiniBatch (dataX人数()%预处理预测。X = preprocessMiniBatchPredictors (dataX);%从细胞中提取标签数据和连接。猫(T = 2,人数({1:结束});%一个炎热的编码标签。T = onehotencode (T, 1);结束
Mini-Batch预测预处理功能
的preprocessMiniBatchPredictors函数进行预处理mini-batch预测因子的提取图像数据从输入单元阵列和连接到一个数字数组。灰度输入,连接在第四维度添加每个图像的三维空间,作为一个单通道维度。
函数X = preprocessMiniBatchPredictors (dataX)%连接。猫(X = 4, dataX{1:结束});结束
另请参阅
trainingProgressMonitor|dlarray|dlgradient|dlfeval|dlnetwork|向前|adamupdate|预测|minibatchqueue|onehotencode|onehotdecode