利用强化学习设计器设计和训练Agent
这个例子展示了如何使用强化学习设计师.
打开强化学习设计器应用程序
打开强化学习设计师应用程序。
增强学习设计器
最初,应用程序中未加载任何代理或环境。
进口车柱环境
当使用强化学习设计师,可以从MATLAB导入环境®工作区或创建预定义的环境。有关详细信息,请参阅为强化学习设计器创建MATLAB环境和为强化学习设计万博1manbetx器创建Simulink环境.
对于本例,使用预定义的离散车柱MATLAB环境强化学习选项卡,在环境节,选择新建>离散车杆.
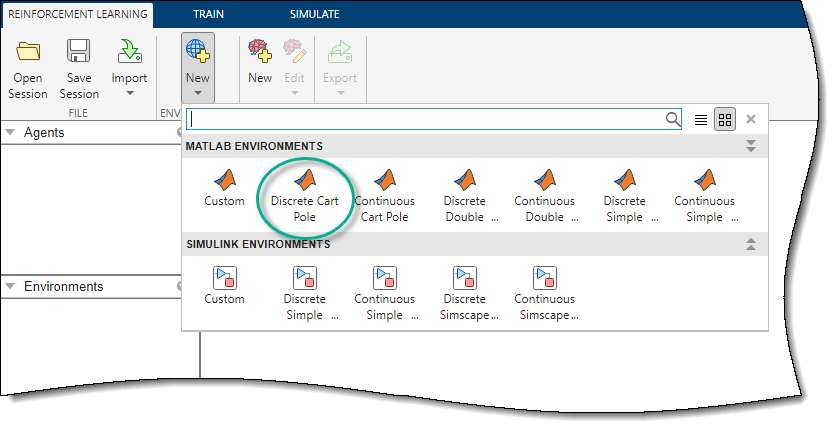
在环境窗格中,应用程序添加导入的离散式手推车环境。要重命名环境,请单击环境文本。您还可以在会话中导入多个环境。
要查看观察和行动空间的维度,请单击环境文本。应用程序将在中显示维度预览窗玻璃
![预览窗格显示状态空间和操作空间的维度分别为[4 1]和[1 1]](http://www.tianjin-qmedu.com/se/help/reinforcement-learning/ug/app_dqn_cartpole_03b.png)
这种环境有一个连续的四维观察空间(小车和杆子的位置和速度)和一个离散的一维行动空间,由两个可能的力组成,-10N或10N。此环境用于培训DQN代理以平衡大车杆系统有关预定义控制系统环境的更多信息,请参阅加载预定义的控制系统环境.
为导入的环境创建DQN代理
要创建代理,请在强化学习选项卡,在代理人部分,单击刚出现的。在“创建代理”对话框中,指定代理名称、环境和培训算法。默认代理配置使用导入的环境和DQN算法。对于本例,请将隐藏单元数从256更改为24。有关创建代理的详细信息,请参阅使用强化学习设计器创建代理.
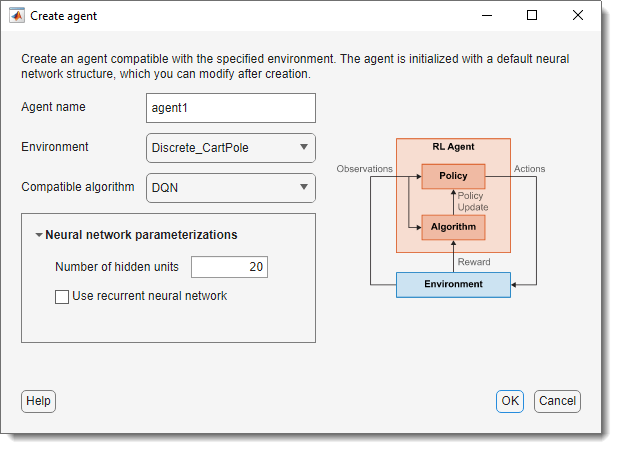
点击好啊.
应用程序将新代理添加到代理人窗格,并打开相应的探员1文件

有关DQN代理功能的简要摘要以及查看代理的观察和操作规范,请单击概述.

在中创建DQN代理时强化学习设计师,代理使用默认的深度神经网络结构作为其评论员。要查看评论员网络,请在DQN试剂选项卡,单击视图批评模型.
这个深度学习网络分析仪打开并显示评论结构。
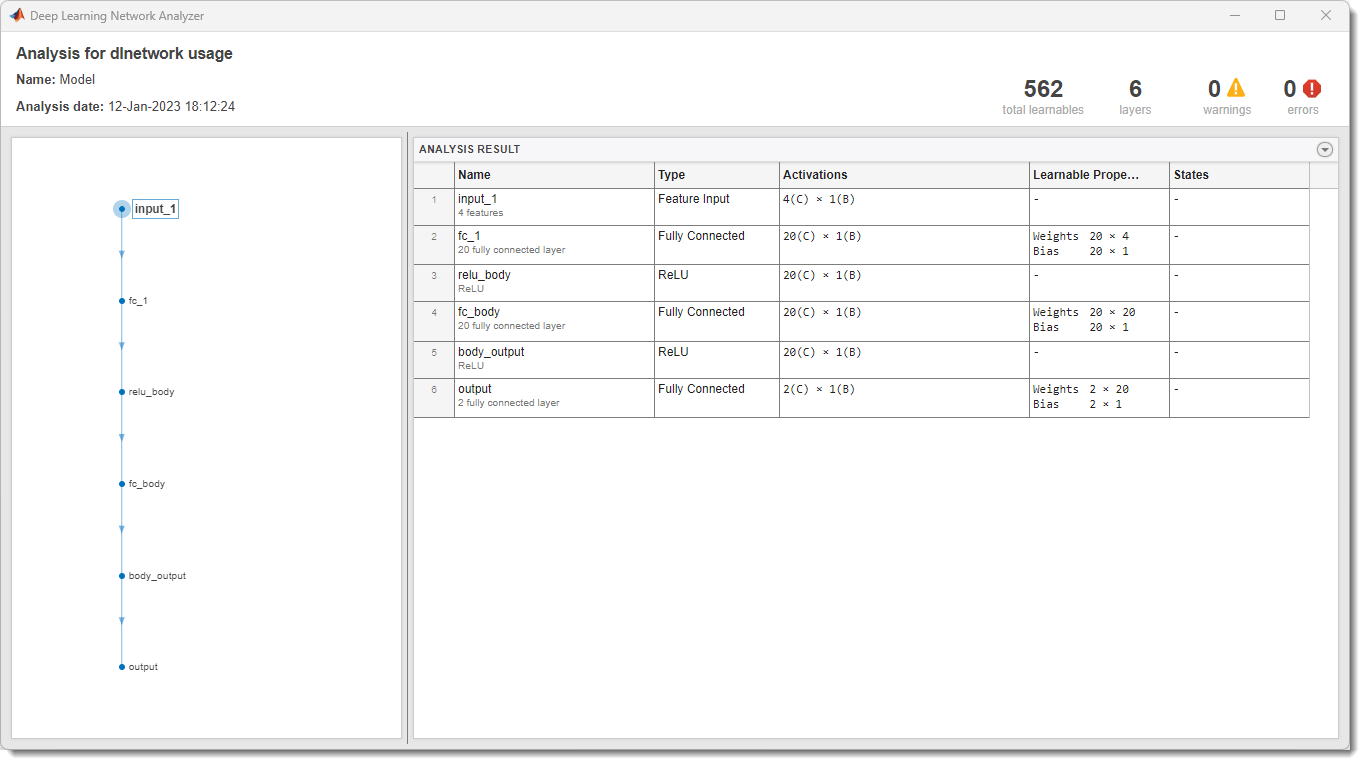
关闭深度学习网络分析仪.
列车员
培训你的经纪人,在火车选项卡,首先指定培训代理的选项。有关指定培训选项的信息,请参阅在强化学习设计器中指定模拟选项.
对于本例,请通过设置指定最大训练集数最大集数到1000。对于其他培训选项,请使用其默认值。停止的默认标准是每集的平均步数(在过去一段时间内5.情节)大于500.

要开始培训,请单击火车.
在培训期间,应用程序将打开培训班选项卡,并在中显示培训进度培训结果文件

此处,当每集的平均步数为500时,训练停止。清除第0集可以更好地形象化情节和平均奖励。
要接受培训结果,请在培训班选项卡,单击接受.在代理人窗格中,应用程序将添加经过培训的代理,经过培训的代理.
模拟代理并检查模拟结果
要模拟经过训练的agent,请在模拟选项卡,首先选择经过培训的代理在代理人下拉列表,然后配置模拟选项。对于本例,使用默认的剧集数(10)和最大集长(500)。有关指定模拟选项的详细信息,请参见在强化学习设计器中指定培训选项.
要模拟代理,请单击模拟.
应用程序将打开模拟会议标签。模拟完成后,将模拟结果文档显示了每集的奖励以及奖励平均值和标准差。
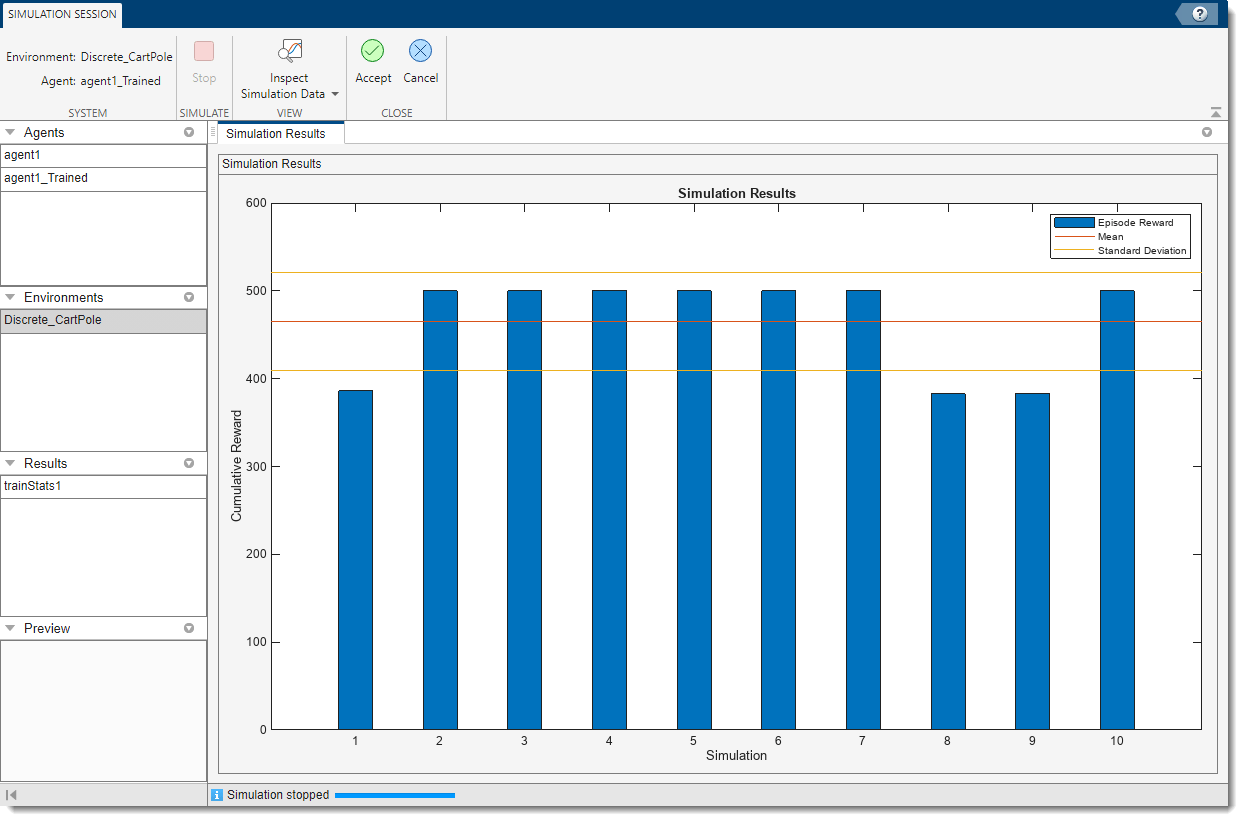
要分析模拟结果,请单击检查模拟数据.
在模拟数据检查器您可以查看每个模拟集保存的信号。有关详细信息,请参阅模拟数据检查器(万博1manbetxSimulink).
下图显示了第六个模拟集的推车杆系统的第一和第三状态(推车位置和杆角度)。即使推车位置发生适度摆动,代理也能够成功地平衡杆500步。您可以修改一些DQN代理选项,例如批量大小和TargetUpdateFrequency促进更快、更稳健的学习。有关详细信息,请参阅培训DQN代理以平衡大车杆系统.

关闭模拟数据检查器.
要接受模拟结果,请在模拟会议选项卡,单击接受.
在后果窗格中,应用程序将添加模拟结果结构,经验1.
导出代理和保存会话
要将经过训练的代理导出到MATLAB工作区以进行额外的模拟,请在强化学习选项卡,在下面出口,选择经过培训的代理。
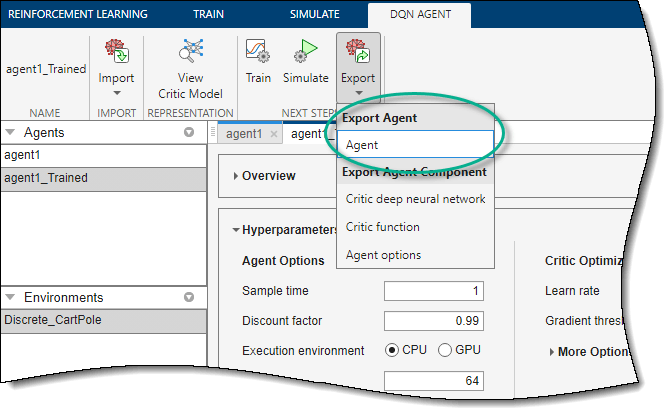
要保存应用程序会话,请在强化学习选项卡,单击保存会话. 将来,若要在结束时继续工作,可以在中打开会话强化学习设计师.
在命令行中模拟代理
要在MATLAB命令行中模拟agent,首先加载cart-pole环境。
env=rlPredefinedEnv(“CartPole离散型”);
cart pole环境有一个环境可视化工具,允许您查看系统在模拟和训练期间的行为。
绘制环境并使用先前从应用程序导出的经过培训的代理执行模拟。
绘图(环境)xpr2=sim(环境,代理1);
在仿真过程中,可视化工具显示小车和杆的运动。经过训练的agent能够稳定系统。
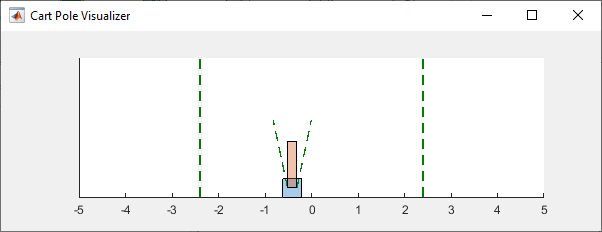
最后,显示模拟的累积奖励。
金额(xpr2.奖励)
环境=500
一如所料,奖金为500英镑。
另见
相关话题
您还可以从以下列表中选择网站: