培训DQN代理以平衡大车杆系统
此示例演示如何训练深度Q学习网络(DQN)代理来平衡在MATLAB®中建模的车杆系统。
有关DQN代理的更多信息,请参阅深度Q网络代理。有关在Simulink®中培训DQN代理的示例,请参阅万博1manbetx培训DQN代理摆动并平衡摆锤.
MATLAB环境下的Cart-Pole
本例中的强化学习环境是一根连接到手推车上未驱动接头的杆,它沿着无摩擦的轨道移动。培训目标是使杆直立而不摔倒。
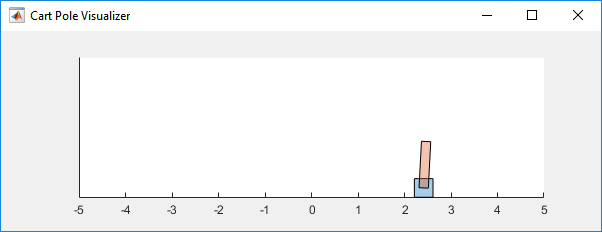
对于这种环境:
向上平衡杆位置为
0弧度,下悬位置为圆周率弧度。磁极开始垂直,初始角度介于–0.05和0.05弧度之间。
从代理到环境的力作用信号为-10到10 N。
从环境中观察到的是小车的位置和速度、极角和极角导数。
如果电杆与垂直方向的夹角超过12度,或者如果手推车从原始位置移动超过2.4 m,则事件终止。
杆保持直立的每一步都会获得+1的奖励。杆落下时会受到-5的惩罚。
有关此模型的详细信息,请参见加载预定义的控制系统环境.
创建环境接口
为系统创建预定义的环境界面。
env=rlPredefinedEnv(“CartPole离散型”)
env=CartPoleDiscreation属性:重力:9.8000质量Cart:1质量杆:0.1000长度:0.5000最大作用力:10 Ts:0.0200 Threshold弧度:0.2094 X阈值:2.4000不下降的奖励:1下降的惩罚:-5状态:[4x1加倍]
界面有一个离散的动作空间,在该空间中,代理可以将两个可能的力值中的一个应用于购物车,-10或10 N。
获取观察和行动规范信息。
obsInfo=getObservationInfo(环境)
obsInfo=rlNumericSpec,属性:LowerLimit:-Inf上限:Inf名称:“CartPole状态”说明:“x、dx、θ、dtheta”维度:[4 1]数据类型:“双”
actInfo=getActionInfo(环境)
actInfo=rlFiniteSetSpec,属性为:元素:[-10 10]名称:“CartPole操作”说明:[0x0字符串]维度:[1]数据类型:“双”
修复随机生成器种子以获得再现性。
rng(0)
创建DQN代理
DQN代理使用价值函数近似于给定观察和行动的长期回报。
DQN代理可以使用多输出Q值批评近似器,通常效率更高。多输出近似器将观察值作为输入,将状态动作值作为输出。每个输出元素表示从观察值指示的状态采取相应离散动作的预期累积长期报酬投入。
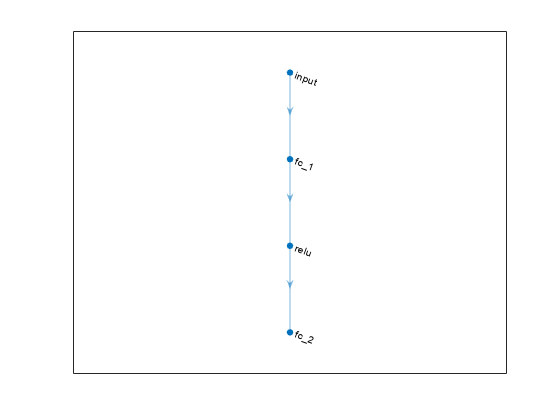
要创建批评家,首先创建一个具有一个输入(四维观察状态)和一个具有两个元素的输出向量(一个用于10N动作,另一个用于–10N动作)的深度神经网络。有关基于神经网络创建值函数表示的更多信息,请参阅创建策略和值函数表示.
dnn=[featureInputLayer(obsInfo.Dimension(1),“正常化”,“没有”,“姓名”,“国家”)完全连接层(24,“姓名”,“CriticStateFC1”)雷卢耶(“姓名”,“CriticRelu1”)完全连接层(24,“姓名”,“CriticStateFC2”)雷卢耶(“姓名”,“CriticCommonRelu”)完整连接层(长度(actInfo.元素),“姓名”,“输出”)];
查看网络配置。
图形绘图(图层图(dnn))
使用指定批评家表示的一些训练选项rlRepresentationOptions.
criticOpts=rlRepresentationOptions(“LearnRate”,0.001,“梯度阈值”,1);
使用指定的神经网络和选项创建批评家表示。有关更多信息,请参阅rlQValueRepresentation.
批评家=rlQValueRepresentation(dnn、obsInfo、actInfo、,“观察”,{“国家”},批判者);
要创建DQN代理,请首先使用指定DQN代理选项rlDQNAgentOptions.
agentOpts=rlDQNAgentOptions(...“UsedDoubledQn”错误的...“目标平滑因子”1....“TargetUpdateFrequency”4....“经验缓冲长度”,100000,...“折扣演员”,0.99,...“MiniBatchSize”,256);
然后,使用指定的critic表示和代理选项创建DQN代理。有关更多信息,请参阅rlDQNAgent.
代理=rlDQNAgent(评论家、代理);
列车员
要培训代理,请首先指定培训选项。对于本例,请使用以下选项:
运行一次最多包含1000集的培训课程,每集最多持续500个时间步。
在“事件管理器”对话框中显示培训进度(设置
阴谋选项)并禁用命令行显示(设置冗长的选择错误的).当代理收到超过480的移动平均累积奖励时停止训练。此时,代理可以在直立位置平衡车杆系统。
有关详细信息,请参阅RL培训选项.
培训选项=RL培训选项(...“最大集”,1000,...“MaxStepsPerEpisode”,500,...“冗长”错误的...“情节”,“培训进度”,...“停止培训标准”,“平均向上”,...“停止训练值”,480);
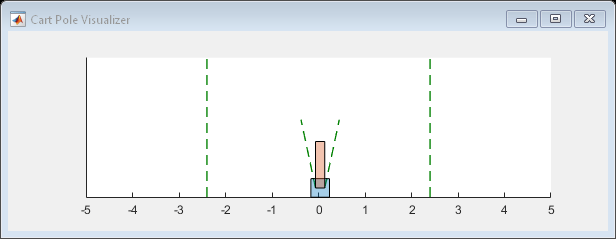
您可以使用可视化工具来可视化推车杆系统情节在训练或模拟过程中发挥作用。
地块(环境)

使用火车函数。培训此代理是一个计算密集型过程,需要几分钟才能完成。要在运行此示例时节省时间,请通过设置溺爱到错误的.要亲自培训特工,请设置溺爱到符合事实的.
doTraining=false;如果溺爱%培训代理人。trainingStats=列车(代理人、环境、列车员);其他的%加载示例的预训练代理。装载(“MATLABCartpoleDQNMulti.mat”,“代理人”)终止

模拟DQN代理
要验证经过培训的代理的性能,请在cart-pole环境中对其进行模拟。有关代理模拟的更多信息,请参阅模拟选项和模拟。即使模拟时间增加到500步,代理也可以平衡推车杆。
simOptions=rlSimulationOptions(“MaxSteps”,500);经验=sim(环境、代理、sim选项);
totalReward=总和(经验奖励)
总报酬=500
另见
相关话题
您还可以从以下列表中选择网站: