迁移学习是一种深度学习方法,其中针对一项任务训练的模型被用作执行类似任务的模型的起点。使用迁移学习更新和再培训网络通常比从头开始培训网络更快、更容易。该方法通常用于目标检测、图像识别和语音识别等应用。
迁移学习是一种流行的技术,因为:
- 它使您能够通过重用已经在大型数据集上训练过的流行模型,使用标记较少的数据来训练模型。
- 它可以减少训练时间和计算资源。在转移学习中,权重不是从头开始学习的,因为预训练的模型已经根据以前的学习来学习权重。
- 您可以利用深度学习研究社区开发的模型体系结构,包括像GoogLeNet和ResNet这样的流行体系结构。
迁移学习的预训练模型
迁移学习的中心是迁移学习预训练深度学习模型,由深度学习研究人员构建,使用数千或数百万样本训练图像进行训练。
有许多预先训练过的模型可供选择,每一种模型都有其优缺点可供考虑:
- 大小:模型所需的内存占用是多少?模型大小的重要性取决于您打算在何处以及如何部署它。它是在嵌入式硬件上运行还是在台式电脑上运行?当部署到低内存系统时,网络的大小特别重要。
- 准确性:模型在再培训前的表现如何?通常情况下,一个在ImageNet(一个包含100万张图片和1000种图片的常用数据集)上表现良好的模型,在新的类似任务上也可能表现良好。然而,ImageNet上的低准确率并不一定意味着该模型在所有任务上的表现都很差。
- 预测速度:模型预测新输入的速度有多快?虽然预测速度可能会根据其他深度学习(如硬件和批大小)而变化,但速度也会根据所选模型的架构和模型的大小而变化。
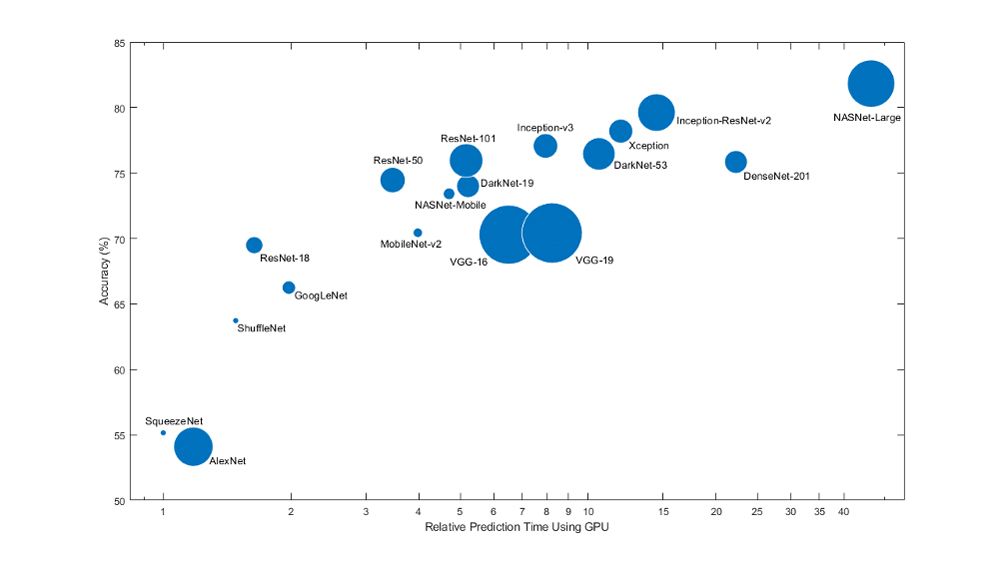
比较流行的预训练网络的模型大小、速度和准确性。.
可以使用MATLAB和深度学习工具箱进行访问来自最新研究的预训练网络用一行代码。工具箱还提供了为转移学习项目选择合适网络的指导。
哪种模式最适合你的迁移学习申请?
具有许多迁移学习模式可供选择,记住所涉及的权衡和具体项目的总体目标是很重要的。例如,准确率相对较低的网络可能非常适合用于新的深度学习任务。一种好的方法是尝试各种模型,以找到最适合您的应用程序的模型。
简单的入门模型。使用简单的模型,如AlexNet、GoogLeNet、VGG-16和VGG-19,您可以快速迭代并尝试不同的数据预处理步骤和训练选项。一旦您看到哪些设置工作正常,您可以尝试更精确的网络,看看这是否会改善您的结果。
轻量级且计算效率高的模型.当部署环境对模型大小施加限制时,SqueezeNet、MobileNet-v2和ShuffleNet是很好的选择。
您可以使用深层网络设计师快速评估项目的各种预训练模型,更好地理解不同模型体系结构之间的权衡。
迁移学习工作流
尽管迁移学习体系结构和应用程序多种多样,大多数转移学习工作流遵循一系列常见步骤.
- 选择一个预先训练的模型。开始时,选择一个相对简单的模型会有帮助。这个例子使用了GoogLeNet,这是一个流行的网络,有22层深度,已经被训练为分类1000个对象类别。

- 替换最后一层。要重新训练网络对一组新的图像和类进行分类,您需要替换GoogLeNet模型的最后一层。最后的全连接层被修改为包含与新类数量相同的节点数量,以及一个新的分类层,该分类层将根据softmax层计算的概率产生输出。
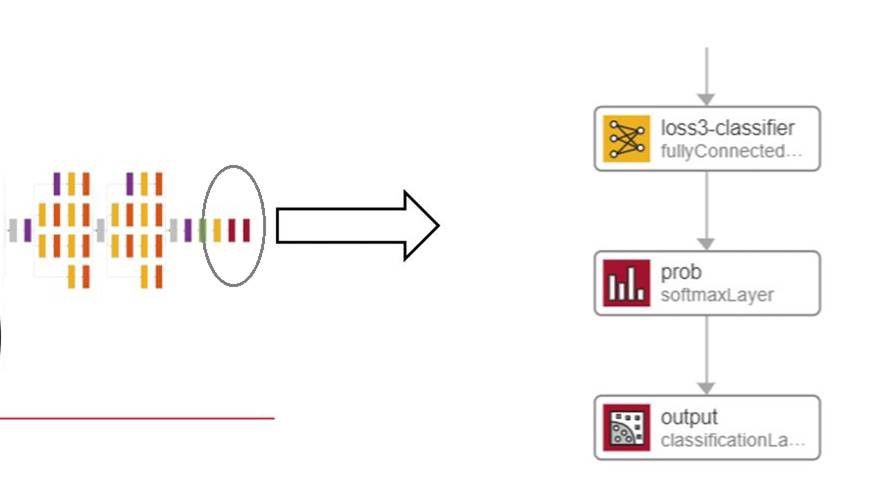
- 修改图层后,最终完全连接的图层将指定新网络将学习的类的数量,而分类层将决定从新输出类别可用。例如,GoogLeNet最初是针对1000个类别进行训练的,但通过替换最后的层,您可以对其进行重新训练,以便仅对您感兴趣的五个(或任何其他数量)类别的对象进行分类。
- 可以选择冻结重量。通过将网络中早期层的学习速率设置为零,可以冻结这些层的权重。在训练过程中,冻结层的参数不会更新,这可以显著加快网络训练速度。如果新数据集很小,则冻结权重也可以防止网络过度拟合新数据集。
- 重新培训模型。再培训将更新网络,以学习和识别与新图像和类别相关的特征。在大多数情况下,再培训比从头开始培训模型需要更少的数据。
- 预测和评估网络的准确性。重新训练模型后,可以对新图像进行分类,并评估网络的性能。
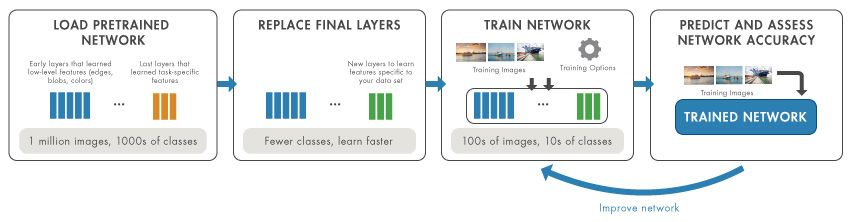
转移学习工作流:加载网络、替换层、训练网络和评估准确性。.
在这种情况下,迁移学习有可能在更短的时间内实现更高的模型精度。
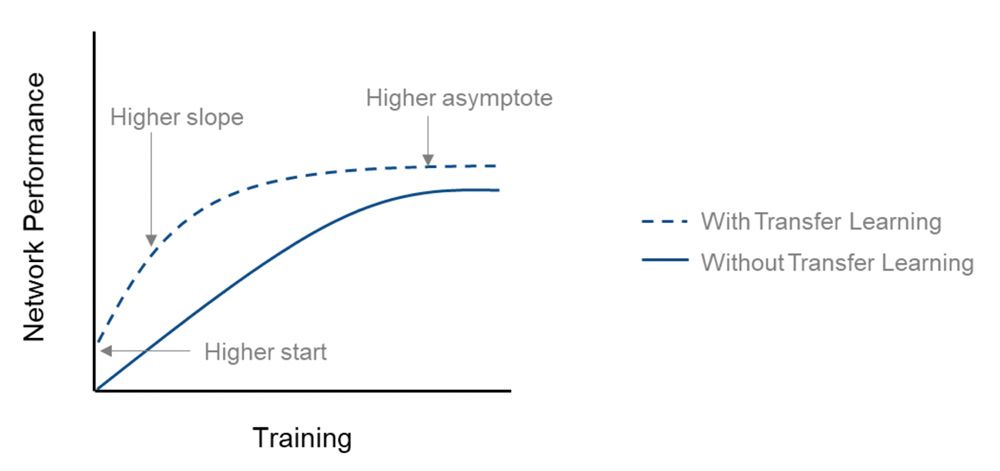
比较从头开始培训和转移学习的网络性能(准确性)。.
迁移学习的交互式方法
使用Deep Network Designer,您可以以交互方式完成整个转移学习工作流–包括导入预训练模型、修改最终层以及使用新数据重新训练网络–几乎不需要编码。


