使用并行计算和gpu的列车代理
如果您有Parallel Computing Toolbox™软件,您可以在多核处理器或gpu上运行并行模拟。如果你有MATLAB®并行服务器™软件,您可以在计算机集群或云资源上运行并行模拟。
您可以独立地使用哪些设备来模拟或训练代理,一旦代理被训练,您就可以生成代码来在CPU或GPU上部署最佳策略。对此有更详细的解释部署训练有素的强化学习政策.
使用多个进程
当您使用并行计算培训代理时,并行池客户端(启动培训的MATLAB进程)将其代理和环境的副本发送给每个并行工作人员。每个工作人员模拟环境中的代理,并将它们的模拟数据发送回客户机。客户端代理从工作者发送的数据中学习,并将更新后的策略参数发送回工作者。
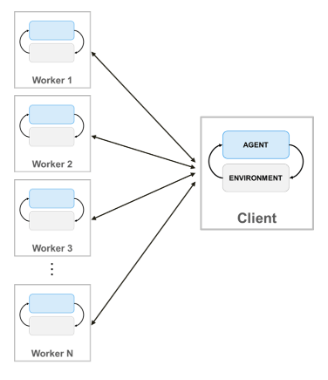
创建的并行池NWorkers,请使用以下语法。
池= parpool(n);
如果不使用。创建并行池parpool(并行计算工具箱),火车函数使用默认并行池首选项自动创建一个。有关指定这些偏好的更多信息,请参阅指定并行首选项(并行计算工具箱).注意,使用线程工作器的并行池,例如池= Parpool(“线程”),不支持。万博1manbetx
要使用多个流程培训代理,您必须将其传递给火车一个函数rlTrainingOptions对象中UseParallel被设置为真的.
有关配置培训以使用并行计算的更多信息,请参阅UseParallel和ParallelizationOptions选项rlTrainingOptions.
注意,不支持对包含多个代理的环境进行并行模拟和培训。万博1manbetx
有关在MATLAB中使用并行计算训练代理的示例,请参见用并行计算训练交流Agent平衡车杆系统.下面是一个在Simulink中使用并行计算训练代理的示例万博1manbetx®,请参阅基于并行计算的车道保持辅助DQN Agent训练和使用强化学习代理训练两足机器人行走.
特定于agent的并行训练考虑
对于DDPG和DQN代理等违规代理,请勿使用所有核心以进行并行培训。例如,如果您的CPU有六个核心,用四名工人列车。这样做为并行池客户端提供了更多资源,以基于从工人发送的经验计算渐变。限制工作人员的数量不是在工人上计算梯度时的政策代理(如AC和PG代理)。
基于梯度的并行化(AC和PG代理)
同时训练AC和PG特工DataToSendFromWorkers.财产的财产ParallelTraining对象(包含在训练选项对象中)必须设置为“梯度”.
这样就配置了培训,使得环境模拟和梯度计算都由工作人员完成。具体来说,工作人员根据环境模拟代理,根据经验计算梯度,并将梯度发送到客户机。客户端对梯度进行平均,更新网络参数,并将更新后的参数发送回工作人员,以便他们可以继续使用新参数模拟代理。
使用基于梯度的并行化,原则上可以实现速度的提高,在worker的数量上几乎是线性的。然而,此选项需要同步训练(即模式财产的财产rlTrainingOptions对象的火车功能必须设置为“同步”).这意味着工人必须暂停执行,直到所有工人都完成,因此,培训只在最慢的工人允许的速度下进行。
当AC代理程序并行培训时,如果存在警告NumStepToLookAhead属性和AC代理选项对象StepsUntilDataIsSent财产的财产ParallelizationOptions对象设置为不同的值。
基于经验的并行化(DQN、DDPG、PPO、TD3和SAC代理商)
同时训练DQN、DDPG、PPO、TD3和SACDataToSendFromWorkers.财产的财产ParallelizationOptions对象(包含在训练选项对象中)必须设置为“经验”.此选项不需要同步训练(即模式财产的财产rlTrainingOptions对象的火车Function可设置为“异步”).
这将配置培训,以便环境模拟由工作人员完成,学习由客户完成。具体来说,工作人员在环境中模拟agent,并将体验数据(观察、动作、奖励、下一次观察和终止信号)发送给客户端。然后,客户端根据经验计算梯度,更新网络参数,并将更新后的参数发送回工作人员,后者继续使用新参数模拟代理。
只有当模拟环境的计算代价比优化网络参数的代价高时,基于经验的并行化才能减少训练时间。否则,当环境模拟足够快时,工作者就会等待客户机学习并返回更新后的参数。
换句话说,基于经验的并行化可以提高样本效率(目的是一个代理在给定时间内可以处理的样本数量),只有当比例为时R在环境步骤复杂性和学习复杂性之间很大。如果环境模拟和学习都同样计算昂贵,则基于体验的并行化不太可能提高样本效率。但是,在这种情况下,对于违规代理商,您可以减少迷你批量尺寸R更大,从而提高样品效率。
要在并行训练DQN、DDPG、TD3或SAC代理时强制体验缓冲区中的连续性,请设置NumStepsToLookAhead属性或对应的代理选项对象1.当尝试并行训练时,不同的值会导致错误。
使用gpu
当使用深度神经网络函数近似器为演员或评论家表示时,您可以通过在本地GPU而不是CPU上执行表示操作(如梯度计算和预测)来加速训练。要做到这一点,当创建一个评论家或演员代表时,使用rlRepresentationOptions其中的对象UseDevice选项设置为“图形”而不是“cpu”.
选择= rlRepresentationOptions (“UseDevice”,“图形”);
的“图形”选项需要并行计算工具箱软件和CUDA®使英伟达®GPU。有关受支持的gpu的更多信息,请参阅万博1manbetxGPU支万博1manbetx持情况(并行计算工具箱).
您可以使用gpuDevice(并行计算工具箱)查询或选择要与MATLAB一起使用的本地GPU设备。
当演员或批评者表示中的深神经网络使用诸如输入图像上的多个卷积层或具有大批量尺寸时,使用GPU可能是有益的。
有关如何使用GPU训练代理的示例,请参见用图像观察训练DDPG Agent上摆和平衡摆.
同时使用多进程和gpu
您还可以使用多个进程和本地GPU(之前选择使用gpuDevice(并行计算工具箱))同时。具体来说,你可以用rlRepresentationOptions其中的对象UseDevice选项设置为“图形”.然后可以使用评论家和参与者创建代理,然后使用多个流程培训代理。这是通过创建rlTrainingOptions对象中UseParallel被设置为真的并将它传递给火车函数。
对于基于梯度的并行化(必须在同步模式下运行),环境模拟是由工作人员完成的,他们使用自己的本地GPU来计算梯度并执行预测步骤。然后将梯度发送回并行池客户端进程,该进程计算平均值、更新网络参数并将它们发送回工作人员,以便他们继续根据环境使用新参数模拟代理。
对于基于经验的并行化(可以在异步模式下运行),工作人员根据环境模拟代理,并将经验数据发送回并行池客户端。然后,客户端使用其本地GPU根据经验计算梯度,然后更新网络参数,并将更新后的参数发送回工作人员,工作人员将继续使用新参数模拟代理,对抗环境。
注意,当同时使用并行处理和GPU来训练PPO代理时,工作人员使用他们本地的GPU来计算优势,然后将处理后的经验轨迹(包括优势、目标和行动概率)发送回客户端。
另请参阅
火车|rlTrainingOptions|rlRepresentationOptions
相关话题
你也可以从以下列表中选择一个网站:
