learnerCoderConfigurer
描述
训练后机器学习模型,创建一个编码器配置模型通过使用learnerCoderConfigurer。使用对象的功能和属性配置指定代码生成选项,并生成C / c++代码预测和更新机器学习模型的功能。需要生成C / c++代码MATLAB®编码器™。
这个流程图显示了代码生成使用编码器配置工作流。使用learnerCoderConfigurer突出显示的步骤。
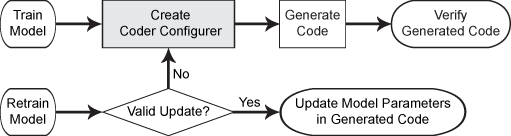
例子
使用编码器配置生成代码
火车一个机器学习模型,然后生成代码预测和更新功能模型的使用编码器配置。
加载carsmall数据集和训练支持向量机(SVM)回归模型。万博1manbetx
负载carsmallX =(功率、重量);Y = MPG;Mdl = fitrsvm (X, Y);
Mdl是一个RegressionSVM对象,它是一个线性支持向量机模型。预测系数的线性支持向量机模型提供足够的信息来预测新观察反应去除支持向量减少内存使用量在生成的代码中。万博1manbetx把支持向量通过线性支持万博1manbetx向量机模型discard万博1manbetxSupportVectors函数。
Mdl = discard万博1manbetxSupportVectors (Mdl);
创建一个编码器的配置RegressionSVM模型通过使用learnerCoderConfigurer。指定的预测数据X。的learnerCoderConfigurer函数使用的输入X配置的编码属性预测函数的输入。
X配置= learnerCoderConfigurer (Mdl)
配置属性= RegressionSVMCoderConfigurer:更新输入:β:[1 x1 LearnerCoderInput]: [1 x1 LearnerCoderInput]偏见:[1 x1 LearnerCoderInput]预测输入:X: [1 x1 LearnerCoderInput]代码生成参数:NumOutputs: 1 OutputFileName:“RegressionSVMModel”属性,方法
配置是一个RegressionSVMCoderConfigurer对象,该对象是一个编码器的配置RegressionSVM对象。
生成C / c++代码,您必须访问一个C / c++编译器配置正确。MATLAB编码器定位和使用支持,安装编译器。万博1manbetx您可以使用墨西哥人设置查看和更改默认编译器。更多细节,请参阅改变默认的编译器。
生成的代码预测和更新函数的支持向量机回归模型(Mdl用默认设置)。
generateCode(配置)
generateCode输出文件夹中创建这些文件:初始化。米”、“预测。米”、“更新。米”、“RegressionSVMModel。垫的代码生成成功。
的generateCode函数完成这些操作:
生成所需的MATLAB文件生成代码,包括两个入口点函数
predict.m和update.m为预测和更新的功能Mdl,分别。创建一个墨西哥人函数命名
RegressionSVMModel两个入口点函数。创建中的墨西哥人功能的代码
codegen \墨西哥人\ RegressionSVMModel文件夹中。墨西哥人功能复制到当前文件夹。
显示的内容predict.m,update.m,initialize.m文件使用类型函数。
类型predict.m
变长度输入宗量函数varargout =预测(X) % # codegen %自动生成通过MATLAB, 03 - mar - 2023 10:52:31 [varargout {1: nargout}] =初始化(“预测”,X,变长度输入宗量{:});结束
类型update.m
函数更新(变长度输入宗量)% # codegen %自动生成通过MATLAB, 03 - mar - 2023 10:52:31初始化(“更新”,变长度输入宗量{:});结束
类型initialize.m
函数[varargout] =初始化(指挥、变长度输入宗量)% # codegen %自动生成通过MATLAB, 03 - mar - 2023 10:52:31 coder.inline(“总是”)持久模型如果isempty(模型)模型= loadLearnerForCoder (“RegressionSVMModel.mat”);终端开关(命令)案例'更新' %更新结构体字段:β%比例%偏差模型=更新(模型、变长度输入宗量{:});例“预测”%预测输入:X X =变长度输入宗量{1};如果输入参数个数= = 2 (varargout {1: nargout}] =预测(模型中,X);其他PVPairs =细胞(1、nargin-2);i = 1: nargin-2 PVPairs{1,} =变长度输入宗量{i + 1};结束(varargout {1: nargout}] =预测(模型、X PVPairs {:});结束结束结束
更新参数的支持向量机分类模型生成的代码
使用部分数据集训练支持向量机模型,并创建一个编码器的配置模型。使用编码器配置的属性来指定编码支持向量机模型参数的属性。使用编码器配置的目标函数来生成C代码,预测新的预测数据标签。然后再培训模型使用和更新整个数据集参数生成的代码没有重新生成代码。
火车模型
加载电离层数据集。这个数据集有34个预测因子和351二进制响应雷达回报,要么坏(“b”)或好(‘g’)。
负载电离层
火车一个二进制SVM分类模型使用前50的观察和高斯核函数的自动内核规模。
Mdl = fitcsvm (X (1:50:), Y (1:50),…“KernelFunction”,“高斯”,“KernelScale”,“汽车”);
Mdl是一个ClassificationSVM对象。
创建编码器配置
创建一个编码器的配置ClassificationSVM模型通过使用learnerCoderConfigurer。指定的预测数据X。的learnerCoderConfigurer函数使用的输入X配置的编码属性预测函数的输入。同时,设置输出的数量2,这样生成的代码返回预测标签和分数。
配置= learnerCoderConfigurer (Mdl X (1:50,:)“NumOutputs”2);
配置是一个ClassificationSVMCoderConfigurer对象,该对象是一个编码器的配置ClassificationSVM对象。
指定编码的属性参数
指定编码支持向量机分类模型参数的属性,这样您就可以更新培训后生成的代码模型中的参数。本例中指定的编码属性预测数据,你想通过生成的代码和编码器SVM模型的支持向量的属性。万博1manbetx
首先,指定的编码属性X这样生成的代码接受任何数量的观察。修改SizeVector和VariableDimensions属性。的SizeVector属性指定的上界预测数据大小,和VariableDimensions属性指定每个维度的预测数据是否有一个变量大小或固定大小。
configurer.X。SizeVector= [Inf 34]; configurer.X.VariableDimensions = [true false];
第一个维度的大小是观测的数量。在这种情况下,代码指定大小的上限正和大小是可变的,这意味着X可以拥有任意数量的观察。这个规范是方便如果你不知道观察当生成代码的数量。
第二个维度是大小的预测变量的数量。这个值必须为一个固定的机器学习模型。X包含34个预测因子,所以的价值SizeVector属性的值必须是34和VariableDimensions属性必须假。
如果你重新训练支持向量机模型使用新数据或不同的设置,支持向量的个数可以有所不同。万博1manbetx因此,指定的编码属性万博1manbetxSupportVectors这样你就可以更新支持向量生成的代码。万博1manbetx
configurer.万博1manbetxSupportVectors。SizeVector = 34 (250);
αSizeVector属性已被修改,以满足配置约束。SizeVector属性SupportVector万博1manbetxLabels已被修改,以满足配置约束。
configurer.万博1manbetxSupportVectors。VariableDimensions= [true false];
αVariableDimensions属性已被修改,以满足配置约束。VariableDimensions属性SupportVector万博1manbetxLabels已被修改,以满足配置约束。
如果你修改的编码属性万博1manbetxSupportVectors,那么软件修改的编码属性α和万博1manbetxSupportVectorLabels为了满足配置约束。如果编码器属性的修改一个参数需要对其他相关参数,以满足后续更改配置约束,那么软件更改的编码属性相关的参数。
生成代码
生成C / c++代码,您必须访问一个C / c++编译器配置正确。MATLAB编码器定位和使用支持,安装编译器。万博1manbetx您可以使用墨西哥人设置查看和更改默认编译器。更多细节,请参阅改变默认的编译器。
使用generateCode生成的代码预测和更新函数的支持向量机分类模型(Mdl用默认设置)。
generateCode(配置)
generateCode输出文件夹中创建这些文件:初始化。米”、“预测。米”、“更新。米”、“ClassificationSVMModel。垫的代码生成成功。
generateCode生成所需的MATLAB文件生成代码,包括两个入口点函数predict.m和update.m为预测和更新的功能Mdl,分别。然后generateCode创建一个墨西哥人函数命名ClassificationSVMModel的两个入口点函数codegen \墨西哥人\ ClassificationSVMModel文件夹,将墨西哥人功能复制到当前文件夹。
验证生成的代码
一些预测数据来验证是否通过预测的函数Mdl和预测墨西哥人的函数返回相同的标签。在墨西哥人叫一个入口点函数有多个入口点函数,函数名指定为第一个输入参数。
(标签,分数)=预测(Mdl X);[label_mex, score_mex] = ClassificationSVMModel (“预测”,X);
比较标签和label_mex通过使用isequal。
label_mex isequal(标签)
ans =逻辑1
isequal返回逻辑1 (真正的如果所有的输入都是平等的。确认进行了比较预测的函数Mdl和预测墨西哥人的函数返回相同的标签。
score_mex相比之下,可能包括舍入差异分数。在这种情况下,比较score_mex和分数,允许一个小宽容。
找到(abs (score-score_mex) > 1 e-8)
ans = 0 x1空双列向量
比较证实,分数和score_mex宽容是相等的1 e-8。
重新培训模型和更新参数生成的代码
使用整个数据集训练模型。
retrainedMdl = fitcsvm (X, Y,…“KernelFunction”,“高斯”,“KernelScale”,“汽车”);
提取参数更新使用validatedUpdateInputs。这个函数修正模型参数的检测retrainedMdl并验证修改后的参数值是否满足编码器的属性参数。
params = validatedUpdateInputs(配置、retrainedMdl);
在生成的代码更新参数。
ClassificationSVMModel (“更新”params)
验证生成的代码
比较的输出预测的函数retrainedMdl和预测功能更新的墨西哥人的功能。
(标签,分数)=预测(retrainedMdl X);[label_mex, score_mex] = ClassificationSVMModel (“预测”,X);label_mex isequal(标签)
ans =逻辑1
找到(abs (score-score_mex) > 1 e-8)
ans = 0 x1空双列向量
比较证实,标签和labels_mex是相等的,分数在公差值相等。
输入参数
Mdl- - - - - -机器学习模型
完整的模型对象|紧凑的模型对象
机器学习模型,指定为一个完整的或紧凑的模型对象,按照这个表支持的模型。万博1manbetx
| 模型 | 全/紧凑的模型对象 | 培训功能 |
|---|---|---|
| 二叉决策树的多类分类 | ClassificationTree,CompactClassificationTree |
fitctree |
| 看到下面成了和二进制分类的支持向量机 | ClassificationSVM,CompactClassificationSVM |
fitcsvm |
| 线性模型的二进制分类 | ClassificationLinear |
fitclinear |
| 多类支持向量机模型和线性模型 | ClassificationECOC,CompactClassificationECOC |
fitcecoc |
| 二叉决策树的回归 | RegressionTree,CompactRegressionTree |
fitrtree |
| 万博1manbetx支持向量机(SVM)回归 | RegressionSVM,CompactRegressionSVM |
fitrsvm |
| 线性回归 | RegressionLinear |
fitrlinear |
的代码生成使用笔记和机器学习模型的局限性,看到模型对象的代码生成部分页面。
X- - - - - -预测数据
数字矩阵
预测数据预测的函数Mdl指定为一个n——- - - - - -p数字矩阵,n是观察和的数量吗p是预测变量的数量。而不是指定X作为一个p——- - - - - -n观察对应的列的矩阵,你必须设置“ObservationsIn”名称-值对参数“列”。该选项只有线性模型和ECOC模型与线性二元学习者。
的预测函数的机器学习模型预测标签分类和响应给定的预测数据的回归。在创建了编码器配置配置,你可以使用generateCode函数来生成C / c++代码预测的函数Mdl。生成的代码接受预测数据具有相同的大小和类型的数据X。您可以指定是否每个维度有一个变量创建后大小或固定大小配置。
例如,如果你想生成C / c++代码,与三个预测变量预测标签使用100年的观察,然后指定X作为0 (100 3)。的learnerCoderConfigurer函数使用的大小和数据类型X,而不是它的价值。因此,X可以预测数据或MATLAB表达式代表一组具有特定数据类型的值。输出配置商店的大小和数据类型X在X的属性配置。您可以修改的大小和数据类型X在创建配置。例如,观察的数量更改为200,数据类型单。
configurer.X。SizeVector= [200 3]; configurer.X.DataType =“单一”;
允许生成的C / c++代码接受预测数据与100观察,指定X作为0 (100 3)和改变VariableDimensions财产。
configurer.X。VariableDimensions = [1 0];
[1 0]表明,第一个维度X(观察)有一个变量的大小和第二维度X(数量的预测变量)具有固定的大小。100年指定数量的观察,在这个例子中,成为了最大允许的观察生成的C / c++代码。允许任意数量的观察,指定绑定正。configurer.X。SizeVector= [Inf 3];
数据类型:单|双
名称-值参数
指定可选的双参数作为Name1 = Value1,…,以=家,在那里的名字参数名称和吗价值相应的价值。名称-值参数必须出现在其他参数,但对的顺序无关紧要。
R2021a之前,用逗号来分隔每一个名称和值,并附上的名字在报价。
例子:配置= learnerCoderConfigurer (Mdl X,“NumOutputs”2“OutputFileName”,“myModel”)设置输出的数量预测2、指定文件名“myModel”为生成的C / c++代码。
NumOutputs- - - - - -的输出数预测
1(默认)|正整数
的输出参数预测机器学习模型的函数Mdl,指定为逗号分隔两人组成的“NumOutputs”和一个正整数n。
此表列出的输出预测不同模型的函数。预测在生成的C / c++代码返回第一个n输出的预测函数中给出的顺序输出列。
| 模型 | 预测的函数模型 |
输出 |
|---|---|---|
| 二叉决策树的多类分类 | 预测 |
标签(预测类标签),分数(后验概率),节点(节点编号为预测类),cnum(类的预测数量标签) |
| 看到下面成了和二进制分类的支持向量机 | 预测 |
标签(预测类标签),分数(分数或后验概率) |
| 线性模型的二进制分类 | 预测 |
标签(预测类标签),分数(分类评分) |
| 多类支持向量机模型和线性模型 | 预测 |
标签(预测类标签),NegLoss(否定平均二进制损失),PBScore(positive-class分数) |
| 二叉决策树的回归 | 预测 |
Yfit(预测反应),节点(节点编号为预测) |
| 支持向量机回归 | 预测 |
yfit(预测反应) |
| 线性回归 | 预测 |
YHat(预测反应) |
例如,如果您指定“NumOutputs”, 1一个支持向量机分类模型预测返回预测类标签生成的C / c++代码。
在创建了编码器配置配置,您可以修改数量的输出通过使用点符号。
配置。NumOutputs= 2;
的“NumOutputs”名称-值对参数等于“-nargout”编译器选项的codegen(MATLAB编码器)。这个选项指定的输出参数的入口点函数,代码生成。的目标函数generateCode编码器的配置生成两个入口点函数predict.m和update.m为预测和更新的功能Mdl——生成C / c++代码的两个入口点函数。指定的值“NumOutputs”对应的输出参数predict.m。
例子:“NumOutputs”, 2
数据类型:单|双
OutputFileName- - - - - -文件名生成的C / c++代码
Mdl对象名称+“模型”(默认)|特征向量|字符串标量
文件名生成的C / c++代码,指定为逗号分隔组成的“OutputFileName”和一个字符向量或字符串标量。
的目标函数generateCode编码器的配置生成C / c++代码使用这个文件名称。
文件名称不能包含空格,因为他们可能会导致在某些操作系统配置代码生成失败。此外,名称必须是一个有效的MATLAB函数名。
默认的文件名的对象名称Mdl紧随其后的是“模型”。例如,如果Mdl是一个CompactClassificationSVM或ClassificationSVM对象,然后默认名称“ClassificationSVMModel”。
在创建了编码器配置配置,您可以修改文件名使用点符号。
配置。OutputFileName =“myModel”;
例子:“OutputFileName”、“myModel”
数据类型:字符|字符串
详细的- - - - - -冗长的水平
真正的(逻辑1)(默认)|假(逻辑0)
冗长的层面上,指定为逗号分隔组成的“详细”,要么真正的(逻辑1)或假(逻辑0)冗长级别控制通知消息的显示在命令行上的编码器配置配置。
| 价值 | 描述 |
|---|---|
真正的(逻辑1) |
软件显示通知消息当你更改编码器的属性参数导致其他相关参数的变化。 |
假(逻辑0) |
软件不显示通知消息。 |
使更新机器学习模型参数在生成的代码中,您需要配置在生成代码的编码属性参数。参数的编码属性相互依赖,所以软件商店依赖配置约束。如果你修改一个参数的编码属性使用编码器配置,和修改需要对其他相关参数,以满足后续更改配置约束,那么软件更改的编码属性相关的参数。冗长的水平决定是否为这些后续更改软件显示通知消息。
在创建了编码器配置配置,您可以修改使用点符号的冗长的水平。
配置。详细的= false;
例子:“详细”,假的
数据类型:逻辑
ObservationsIn- - - - - -预测数据观察维度
“行”(默认)|“列”
预测数据观察维度,指定为逗号分隔组成的“ObservationsIn”,要么“行”或“列”。如果你设置“ObservationsIn”来“列”,那么预测数据X必须面向的观察对应列。
请注意
的“列”只能与线性二元线性模型和ECOC模型学习者。
例子:“ObservationsIn”、“列”
输出参数
配置——编码器配置
编码器配置对象
编码器配置的机器学习模型,作为一个编码器返回在此表中配置对象。
| 模型 | 编码器配置对象 |
|---|---|
| 二叉决策树的多类分类 | ClassificationTreeCoderConfigurer |
| 看到下面成了和二进制分类的支持向量机 | ClassificationSVMCoderConfigurer |
| 线性模型的二进制分类 | ClassificationLinearCoderConfigurer |
| 多类支持向量机模型和线性模型 | ClassificationECOCCoderConfigurer |
| 二叉决策树的回归 | RegressionTreeCoderConfigurer |
| 万博1manbetx支持向量机(SVM)回归 | RegressionSVMCoderConfigurer |
| 线性回归 | RegressionLinearCoderConfigurer |
使用编码器的对象函数和属性配置对象配置代码生成选项,并生成C / c++代码预测和更新机器学习模型的功能。
版本历史
介绍了R2018b
MATLAB命令
你点击一个链接对应MATLAB命令:
运行该命令通过输入MATLAB命令窗口。Web浏览器不支持MATLAB命令。万博1manbetx
你也可以从下面的列表中选择一个网站:
表现最好的网站怎么走吗
选择中国网站(中文或英文)最佳站点的性能。其他MathWorks国家网站不优化的访问你的位置。