通过张量积样条函数逼近
因为工具箱可以处理样条函数向量系数,很容易实现插值或逼近网格数据张量积样条函数,下图是为了表演。您还可以运行示例“二元张量积样条函数”。
可以肯定的是,大多数的张量积样条逼近网格数据可以获得直接与样条构造命令之一,spapi或csape这个工具箱,没有关心这个例子讨论的细节。相反,这个例子是为了说明张量积背后的理论建设,这将帮助的情况下不受施工命令在这个工具箱。
本节讨论这些方面的张量积样条问题:
选择网站和节
考虑,例如,最小二乘逼近给定的数据z(我,j)=f(x(我),y(j)),我= 1:Nx,j= 1:纽约。你把数据从一个广泛使用的函数因特网的测试方案表面拟合(r .因特网,“关键的一些方法比较分散数据的插值,”海军研究生院中欧。众议员nps - 53 - 79 - 003,1979年3月)。其域是单位正方形。你选择几个数据的网站x方向比y方向;同时,对于一个更好的定义,使用高数据密度边界附近。
x = ([(0:10) / 10。03 . 07,公布.97点);y = (((0:6) / 6,。03 . 07,公布.97点);[xx, yy] = ndgrid (x, y);z =因特网(xx和yy);
最小二乘逼近y的函数
把这些数据是来自向量值函数,即的功能y其价值在y(j)是向量z(:,j),所有j。没有特别的原因,选择这个函数近似向量值抛物线花键,三人均匀间隔的内部结。这意味着你选择样条的顺序和向量值的结序列样条
肯塔基州= 3;knotsy = augknt([0二十五分。5。1),肯塔基州);
sp = spap2 (knotsy,肯塔基州,y, z);
实际上,你发现同时离散型最小二乘逼近年代肯塔基州,knotsy每一个Nx数据集
特别是,语句
yy =约:.05:1.1;瓦尔斯= fnval (sp、yy);
提供一个数组瓦尔斯的条目瓦尔斯(i, j)可以作为一个近似的价值f(x(我),yy(j))的潜在功能f在网格点x(我),yy(j),因为瓦尔斯(:,j)是价值yy(j)的逼近样条曲线sp。
这是明显的在下图中,获得的命令:
网格(x, yy,瓦尔。”),视图(150年,50)
注意使用瓦尔斯。”,在网因为MATLAB命令,需要®策划一个数组时matrix-oriented视图。这可能是一个严重的问题在二元近似认为,因为它是司空见惯的z(我,j)作为函数值在点(x(我),y(j),而MATLAB认为z(我,j)作为函数值在点(x(j),y(我))。
一个家庭的假装一个表面光滑的曲线

注意,前两个和两个值在每个光滑曲线实际上是零,因为前两个和最后两个网站yy超出了基本区间样条sp。
还要注意山脊。他们确认你正在策划光滑曲线只在一个方向上。
近似系数x的函数
一个实际的表面,你现在必须更进一步。看看系数coefsy样条的sp:
coefsy = fnbrk (sp,“系数”);
花键的抽象,你能想到的sp的函数
与我th条目coefsy (ir)向量的系数coefsy (:, r)对应于x(我),为所有我。这表明近似系数向量coefsy (q,:)样条的顺序相同kx和适当的结序列相同knotsx。没有特别的原因,这一次使用立方样条函数与四个均匀间隔的内部结:
kx = 4;knotsx = augknt ([0: .2:1], kx);sp2 = spap2 (knotsx kx, x, coefsy。');
请注意,spap2(节,k, x,外汇)预计外汇(j:,)的基准x (j),即,expects each列的外汇是一个函数值。以适应数据coefsy (q,:)在x(问),为所有问、现在spap2与转置的coefsy。
二元近似
现在考虑系数矩阵的转置矩阵cxy生成的样条曲线:
系数= fnbrk (sp2,“系数”)。”;
它提供了二元样条逼近
的原始数据
绘制样条表面网格,如网格
十五= 0:.025:1;青年志愿= 0:.025:1;
你可以做以下几点:
样条逼近因特网的功能

这是很有意义的,因为spcol (knotsx kx,十五)的矩阵(我,问=值B) th条目问,kx(十五(我))十五(我)的问th b样条的订单kx结的序列knotsx。
因为矩阵spcol (knotsx kx,十五)和spcol (knotsy、肯塔基州、青年志愿)是带状,它可能是更有效的,尽管也许更消耗内存,大十五和青年志愿利用fnval,如下所示:
value2 =…fnval (spmak (knotsx fnval (spmak (knotsy系数),青年志愿)。“),十五)。”;
这是,事实上,当内部发生了什么fnval被称为直接与张量积样条,在吗
value2 = fnval (spmak ({knotsx, knotsy},系数),{十五,青年志愿});
这是计算相对误差,即。,the difference between the given data and the value of the approximation at those data sites as compared with the magnitude of the given data:
错误= z - spcol (knotsx kx, x) *系数* spcol (knotsy,肯塔基州,y)。”;disp (max (max (abs(错误)))/ max (max (abs (z))))
输出是0.0539,也许不那么令人印象深刻。然而,数组大小是系数8 6
disp(大小(系数)
适合一个数据数组的大小15日11。
disp(大小(z))
开关为
本文遵循的方法有偏见的,在以下的方式。首先把给定的数据z作为向量值函数的描述y,然后把矩阵形成的向量系数的近似曲线描述的向量值函数x。
当你把事情相反的顺序,即。,想想z作为向量值函数的描述x,然后把矩阵向量系数的近似描述的向量值函数曲线y吗?
也许令人惊讶的是,最后近似相同,舍入。这是数值实验。
最小二乘逼近x的函数
首先,合适的样条曲线数据,但这一次x作为独立变量,因此它是行的z现在成为了数据值。相应地,您必须提供z”。,而不是z,spap2,
spb = spap2 (knotsx kx, x, z。');
十五,valsb = fnval (spb)。';
提供了矩阵valsb的条目valsb (i, j)可以作为一个近似的价值f(十五(我),y(j))的潜在功能f网格点(十五(我),y(j))。这是显而易见的,当你的阴谋valsb使用网:
网格(十五,y, valsb。”),视图(150年,50)
另一个家庭的假装一个表面光滑的曲线
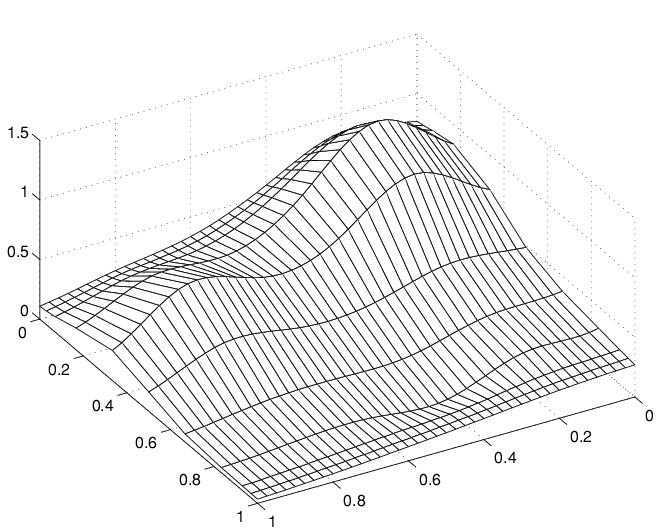
注意山脊。他们确认你再次绘制平滑曲线只在一个方向上。但这一次的曲线运行在另一个方向。
近似系数的函数y
现在是第二步,得到实际的表面。首先,提取系数:
“系数”coefsx = fnbrk (spb);
然后适合每个系数向量coefsx (r,:)样条的顺序相同肯塔基州和适当的结序列相同knotsy:
注意,再次,你需要转置的系数阵spb,因为spap2以最后一次输入参数的列数据值。
相应地,现在不需要转置系数数组coefsb产生的曲线:
coefsb = fnbrk (spb2“系数”);
二元近似
声称是coefsb等于前面的系数阵系数,舍入,这是测试:
disp (max (max (abs(系数- coefsb))))
输出是1.4433 e15汽油。
原因很简单:系数c样条的年代包含在sp = spap2(节,k, x, y)依赖线性在输入值y。这意味着,考虑到c和y1行矩阵,矩阵一个=一个节,k,x这
对于任何数据y。这句话甚至当y是一个矩阵的大小d——- - - - - -N在这种情况下,每个数据y(:,j)是一个点Rd相应地,生成的样条d向量值,因此其系数阵c的大小d——- - - - - -n,n =长度(节)- k。
特别是,语句
sp = spap2 (knotsy,肯塔基州,y, z);coefsy = fnbrk (sp,“系数”);
为我们提供的矩阵coefsy满足
随后的计算
sp2 = spap2 (knotsx kx, x, coefsy。');系数= fnbrk (sp2,“系数”)。”;
生成的系数阵系数,考虑到两个互换,满足
第二、选择、计算,首先计算
spb = spap2 (knotsx kx, x, z。');“系数”coefsx = fnbrk (spb);
因此coefsx= z '。knotsx, kx, x。随后的计算
spb2 = spap2 (knotsy,肯塔基州,y, coefsx。');“系数”coefsb = fnbrk (spb);
然后提供
因此,coefsb=系数。
比较和扩展
第二种方法比第一个更对称的转换发生在每次调用spap2和其他地方。这种方法可用于近似网格数据在任意数量的变量。
例如,如果在一个给定的数据三个维网格中包含一些三维数组v的大小(Nx、纽约、新西兰),v (i, j, k)包含值f(x(我),y(j),z(k),然后你会开始
纽约系数=重塑(v, Nx *新西兰);
假设nj =结j -kjj =x, y, z,你将进行如下:
sp = spap2 (knotsx kx, x,系数。');系数=重塑(fnbrk (sp,“系数”)、纽约、新西兰* nx);sp = spap2 (knotsy,肯塔基州,y,系数。');系数=重塑(fnbrk (sp,“系数”),新西兰nx *纽约);sp = spap2 (knotsz, kz, z,系数。');系数=重塑(fnbrk (sp,“系数”),nx,纽约*新西兰);
看到第17章动力或(C。粗野的,“高效的计算机操纵的张量产品,”s manbetx 845ACM反式。数学。软件5(1979),173 - 182;勘误表,525]为更多的细节。同样的引用也明确表示,这里没有什么特别的关于使用最小二乘近似。任何近似处理,包括样条插值,生成的近似系数,线性依赖于给定的数据,可以以同样的方式扩展到多元逼近过程网格数据。
这正是花键建设中使用的命令csapi,csape,spapi,spaps,spap2,当网格数据拟合。它也被运用于fnval,当一个张量积样条是一个网格计算。