TreeBagger
创建决策树袋
个人决策树倾向于过度拟合。引导聚集(袋装)决策树结合大量的决策树,从而降低过度拟合的效果,提高了泛化的结果。TreeBagger增长的数据的集合使用bootstrap样本中的决策树。也,TreeBagger选择预测器的随机子集在每个决定分割使用如随机森林算法[1]。
默认,TreeBagger袋分类树。包包回归树来代替,指定“方法”,“回归”。
对于回归问题,TreeBagger万博1manbetx支持均值和分位数回归(即分位数回归森林[5])。
句法
MDL = TreeBagger(NumTrees,TBL,ResponseVarName)
MDL = TreeBagger(NumTrees,TBL,式)
MDL = TreeBagger(NumTrees,TBL,Y)
B = TreeBagger(NumTrees,X,Y)
B = TreeBagger(NumTrees,X,Y,名称,值)
描述
MDL= TreeBagger(NumTrees,TBL,ResponseVarName)NumTrees袋装分类树在使用表格中的样本数据训练TBL。ResponseVarName是在响应变量的名称TBL。
MDL= TreeBagger(NumTrees,TBL,式)TBL。式是响应的说明模型和预测变量的在一个子集TBL用来拟合MDL。指定式使用威尔金森符号。欲了解更多信息,请参阅威尔金森表示法。
MDL= TreeBagger(NumTrees,TBL,ÿ)TBL和类别标签在矢量ÿ。
ÿ是响应数据的数组。要点ÿ对应于各行TBL。对于分类,ÿ是一套真正的类标签。标签可以是任何分组变量即,数字或逻辑向量,字符矩阵,字符串数组,字符向量的单元阵列,或分类矢量。TreeBagger标签转换为字符向量的单元阵列。对于回归,ÿ是一个数值向量。增长回归树,你必须指定名称 - 值对“方法”,“回归”。
乙= TreeBagger(NumTrees,X,ÿ)乙的NumTrees用于预测响应决策树ÿ作为预测的在训练数据的数字矩阵的函数,X。每一行中X代表观测,每一列代表一个预测器或特征。
B = TreeBagger(NumTrees,X,Y,名称,值)指定可选的参数名称 - 值对:
'InBagFraction' |
输入数据的分数与从用于生长每个新树中的输入数据的替换样品。默认值是1。 |
'成本' |
方阵 或者,
默认值是 如果 |
'SampleWithReplacement' |
'上'与更换或样品“关”无需更换采样。如果您品尝无需更换,需要设置'InBagFraction'到的值小于一。默认值是'上'。 |
'OOBPrediction' |
'上'存储的信息是什么观测袋每个树出来。这个信息可以通过使用oobPrediction来计算预测的类概率在合奏每个树。默认值是“关”。 |
'OOBPredictorImportance' |
'上'存储在整体功能的重要性了球袋估计。默认值是“关”。指定'上'还设置了'OOBPrediction'值'上'。如果预测重要性的分析是你的目标,那么也可以指定'PredictorSelection', '弯曲'要么“PredictorSelection”,“相互作用曲率”。有关详细信息,请参阅fitctree要么fitrtree。 |
'方法' |
或'分类'要么“回归”。回归需要一个数字ÿ。 |
'NumPredictorsToSample' |
变量数以随机每个决策拆分选择。默认的是用于分类变量的数量的平方根和三分之一的回归变量的数目的。有效值'所有'或一个正整数。这个参数设置为任何有效的值,但'所有'所调用Breiman的随机森林算法[1]。 |
'NumPrint' |
培训周期数(成年树)之后,TreeBagger显示示出训练进度诊断消息。默认为不诊断消息。 |
'MinLeafSize' |
最小数每树叶意见。默认值是1用于分类和5回归。 |
“选项” |
一种结构,增长决策树的合奏时支配计算指定的选项。其中一个选项要求在多个引导重复决策树的计算使用多个处理器,如果并行计算工具箱™是可用的。两个选项指定选择引导重复的随机数流使用。您可以通过调用来创建这个说法
|
“在此之前” |
先验概率为每个类。指定为之一:
如果您在设定值 如果 |
'PredictorNames' |
预测器变量名,指定为逗号分隔的一对组成的
|
'CategoricalPredictors' |
分类预测列表中,指定为逗号分隔的一对组成的
|
“块大小” |
块大小,指定为逗号分隔的一对组成的 注意此选项仅使用时应用 |
除了上述的可选参数,TreeBagger接受这些可选fitctree和fitrtree参数。
万博1manbetx支持的fitctree参数 |
万博1manbetx支持的fitrtree参数 |
|---|---|
AlgorithmForCategorical |
MaxNumSplits |
MaxNumCategories |
MergeLeaves |
MaxNumSplits |
PredictorSelection |
MergeLeaves |
修剪 |
PredictorSelection |
PruneCriterion |
修剪 |
QuadraticErrorTolerance |
PruneCriterion |
SplitCriterion |
SplitCriterion |
代孕 |
代孕 |
权重 |
“权重” |
例子
袋装分类树的火车合奏
加载费舍尔的虹膜数据集。
加载fisheriris
列车采用整个数据集袋装分类树的集合。指定50弱学习。商店这观测袋每个树出来。
RNG(1);%用于重现MDL = TreeBagger(50,MEAS,物种,'OOBPrediction','上',...'方法','分类')
MDL = TreeBagger合奏用50个袋装决策树:培训X:[150x4]培训Y:[150x1]方法:分类NumPredictors:4个NumPredictorsToSample:2 MinLeafSize:1个InBagFraction:1 SampleWithReplacement:1个ComputeOOBPrediction:1个ComputeOOBPredictorImportance:0接近:[]类名:“setosa'菌“弗吉尼亚”的属性,方法
MDL是TreeBagger合奏。
Mdl.Trees存储训练的分类树的一个50×1细胞载体(CompactClassificationTree模型对象)组成该合奏。
绘制第一个训练的分类树的图。
视图(Mdl.Trees {1},'模式','图形')

默认,TreeBagger长深树。
Mdl.OOBIndices商店外的包的索引作为逻辑值的矩阵。
绘制出球袋误差超过成年分类树的数量。
数字;oobErrorBaggedEnsemble = oobError(MDL);图(oobErrorBaggedEnsemble)xlabel“种植的树木数”;ylabel“乱袋分类错误”;

从球袋误差与种植树木的数量减少。
要标记出球袋观察,通过MDL至oobPredict。
袋装回归树的火车合奏
加载carsmall数据集。考虑到预测给予其发动机排量汽车的燃油经济性的典范。
加载carsmall
列车采用整个数据集袋装回归树的集合。指定100个弱学习。
RNG(1);%用于重现MDL = TreeBagger(100,位移,MPG,'方法',“回归”);
MDL是TreeBagger合奏。
使用回归树的训练的包,你可以估算条件均值回复或执行分位数回归预测有条件的分位数。
对于样本的位移最小值和最大值之间10个相等间隔的发动机的位移,预测条件均值反应和条件的四分位数。
predX = linspace(分钟(位移),最大值(位移),10)';mpgMean =预测(MDL,predX);mpgQuartiles = quantilePredict(MDL,predX,“位数”[0.25,0.5,0.75]);
画出观察,估计平均响应和四分位数的数字相同。
数字;图(位移,MPG,'O');保持上情节(predX,mpgMean);情节(predX,mpgQuartiles);ylabel(“燃油经济性”);xlabel('发动机排量');传说('数据',“平均响应”,“第一个四分位数”,“中位数”,“第三四分位数”);

无偏预测估计的重要性
加载carsmall数据集。考虑到预测给予其加速度,汽缸,发动机排量,马力,制造商,车型年份和重量数的汽车的平均燃油经济性的典范。考虑气瓶,MFG和Model_Year作为分类变量。
加载carsmall气缸=分类(缸);MFG =分类(cellstr(MFG));Model_Year =分类(Model_Year);X =表(加速度,缸,排气量,马力,厂家批号,...Model_Year,重量,MPG);RNG('默认');%用于重现
显示在分类变量表示类别的数量。
numCylinders = numel(类别(缸))
numCylinders = 3
numMfg = numel(类别(MFG))
numMfg = 28
numModelYear = numel(类别(Model_Year))
numModelYear = 3
因为有3个类别只在气瓶和Model_Year,标准CART,预测分裂算法倾向于分裂了这两个变量的连续预测。
列车使用整个数据集,200个回归树的随机森林。种植树木不偏不倚,指定拆分预测曲率测试的使用。因为有数据缺失值,指定替代拆分的使用。存放了球袋的信息预测的重要性估计。
MDL = TreeBagger(200,X,'MPG','方法',“回归”,“代孕”,'上',...'PredictorSelection',“曲率”,'OOBPredictorImportance','上');
TreeBagger卖场预测因素属性重要性的估计OOBPermutedPredictorDeltaError。比较用柱状图的估计。
小鬼= Mdl.OOBPermutedPredictorDeltaError;数字;栏(IMP);标题(“曲率测试”);ylabel(“预测的重要性估计”);xlabel(“预测器”);H = GCA;h.XTickLabel = Mdl.PredictorNames;h.XTickLabelRotation = 45;h.TickLabelInterpreter ='没有';

在这种情况下,Model_Year是最重要的预测指标,其次是重量。
比较恶魔以预测的重要性估计从使用标准的车长树随机森林计算。
MdlCART = TreeBagger(200,X,'MPG','方法',“回归”,“代孕”,'上',...'OOBPredictorImportance','上');impCART = MdlCART.OOBPermutedPredictorDeltaError;数字;巴(impCART);标题(“标准车”);ylabel(“预测的重要性估计”);xlabel(“预测器”);H = GCA;h.XTickLabel = Mdl.PredictorNames;h.XTickLabelRotation = 45;h.TickLabelInterpreter ='没有';
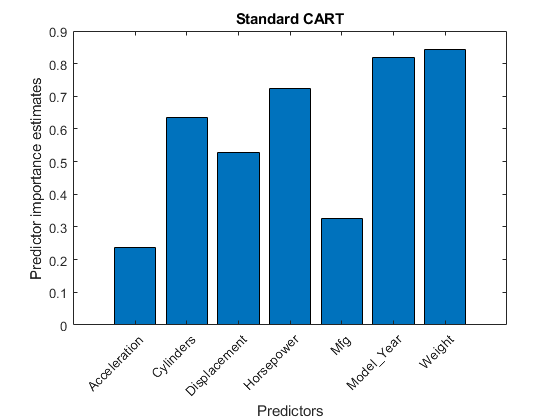
在这种情况下,重量,连续预测,是最重要的。接下来的两个最重要的预测是Model_Year紧随其后的是马力,这是一个连续的预测值。
袋装分类树的列车乐团对高层阵列
训练袋装分类树用于观测的合奏在一个高大的阵列,并且找到每个树的模型中的用于加权的观察误分类概率。样本数据集airlinesmall.csv是包含航空公司的航班数据的表格文件中的大型数据集。
当您在高大的阵列进行计算,MATLAB®使用使用并行池(默认情况下,如果您有并行计算工具箱™)或本地MATLAB会话。如果你想使用时,你有并行计算工具箱本地MATLAB会话运行示例,您可以通过使用改变全球执行环境mapreducer功能。
创建数据存储引用包含数据集的文件夹的位置。选择变量的一个子集一起工作,和治疗'NA'值丢失的数据,以便数据存储它们替换为NaN值。创建一个包含数据存储中的数据一个高大的表。
DS =数据存储区('airlinesmall.csv');ds.SelectedVariableNames = {'月','DAYOFMONTH',“星期几”,...'DepTime','ArrDelay','距离','DepDelay'};ds.TreatAsMissing ='NA';TT =高(DS)%高大的表
开始使用“本地”轮廓平行池(parpool)......连接到并行池(工号:4)。TT = MX7高大表月DAYOFMONTH DAYOFWEEK DepTime ArrDelay距离DepDelay _____ __________ _________ _______ ________ ________ ________ 10 21 3 642 8 308 12 10 26 1 1021 8 296 1 10 23 5 2055 21 480 20 10 23 5 1332 13 296 12 10 22 4629 4 373 -1 10 28 3 1446 59 308 63 10 8 4 928 3 447 10 -2 10 6 859 11 954 -1::::::::::::::
确定通过定义一个逻辑变量,一个迟到的飞行是真的迟到了10分钟以上的航班。此变量包含类的标签。这个变量的预览包括前几行。
Y = tt.DepDelay> 10%类标签
Y =的Mx1高逻辑阵列1 0 1 1 0 1 0 0:
创建用于预测数据的高大阵列。
X = {TT:,1:端-1}%预测数据
X = MX6高大双矩阵10 21 3 642 8 308 10 26 1 1021 8 296 10 23 5 2055 21 480 10 23 5 1332 13 296 10 22 4 629 4 373 10 28 3 1446 59 308 10 8 4 928 3 447 10 106 859 11 954::::::::::::
通过在1类任意地分配双权重应用到观测创建用于观察权重一个高大的阵列。
W = Y + 1;%权重
删除行中X,ÿ和w ^包含丢失的数据。
R = rmmissing([X Y W]);%数据去掉缺少的项X = R(:,1:端-2);Y = R(:,端-1);W = R(:,端);
列车使用整个数据集的20个袋装决策树合奏。指定的权重向量和均匀的先验概率。对于重复性,使用设定的随机数生成器的种子RNG和tallrng。该结果可能会因工人的数量和用于高阵列执行环境而变化。有关详细信息,请参阅控制自己的代码运行(MATLAB)。
RNG('默认')tallrng('默认')TMDL = TreeBagger(20,X,Y,“权重”,W,“在此之前”,'制服')
评估使用并行池“本地”高表达: - 的1遍1:在5.6秒评价完成在7.3秒完成评估使用并行池“本地”高表达: - 的1遍1:在4.2秒评价完成在完成9.5秒评价使用并行池“本地”高表达: - 1通过1:已完成在9.8秒评价9.9秒完成
TMDL = CompactTreeBagger合奏用20个袋装决策树:方法:分类NumPredictors:6类名: '0' '1' 的属性,方法
TMDL是CompactTreeBagger20个袋装决策树合奏。
计算模型中每个树的误判概率。属性包含在载体中的重量w ^通过使用每个观测“权重”名称 - 值对的参数。
TERR =错误(TMDL,X,Y,“权重”,W)
评估使用并行池“本地”高表达: - 的1遍1:在9.6秒评价完成在10秒完成
TERR =20×10.1428 0.1214 0.1112 0.1077 0.1034 0.1023 0.1000 0.0991 0.0974 0.0982⋮
查找决策树的整体平均误判概率。
avg_terr =平均值(TERR)
avg_terr = 0.1019
提示
避免大的估计出的袋误差通过设置一个更平衡的误分类代价矩阵或更少歪斜先验概率矢量方差。
该
树财产乙存储的单元阵列B.NumTreesCompactClassificationTree要么CompactRegressionTree模型对象。对于树的文本或图形显示Ť在单元阵列中,输入视图(B.Trees {Ť})标准CART倾向于选择包含在含有几个不同的值,例如,分类变量那些许多不同的值,例如,连续的变量,分裂的预测[4]。考虑指定的曲率或相互作用试验如果任何以下的为真:
如果存在具有比其他预测相对较少不同的值,例如,如果预测的数据集是异质的预测因子。
如果预测重要性的分析是你的目标。
TreeBagger卖场预测因素的重要性估计OOBPermutedPredictorDeltaError财产MDL。
有关预测值选择的更多信息,请参阅
PredictorSelection对于分类树或PredictorSelection对于回归树。
算法
另类功能
统计和机器学习工具箱™提供了套袋和随机森林三个对象:
TreeBagger由...制作TreeBagger分类和回归
有关之间差异的详细信息TreeBagger和袋装合奏(ClassificationBaggedEnsemble和RegressionBaggedEnsemble),见TreeBagger和袋装合奏的比较。
参考
[1] Breiman,L.随机森林。机器学习45,第5-32,2001年。
[2] Breiman,L.,J。弗里德曼,R. Olshen,和C.石。分类和回归树。佛罗里达州Boca Raton:CRC出版社,1984年。
[3]蕙,W.Y.“回归树不带偏见的变量选择和互动检测。”国家统计报卷。12,2002年,第361-386。
[4]蕙,W.Y.和Y.S.施。“拆分选择方法对于分类树”。国家统计报卷。7,1997年,第815-840。
[5] Meinshausen,N“位数回归森林”。杂志的机器学习研究的卷。7,2006年,第983-999。
扩展功能
介绍了在R2009a
您还可以选择从下面的列表中的网站:
