使用深度学习分类视频
这个例子展示了如何结合预先训练的图像分类模型和LSTM网络来创建一个视频分类网络。
创建视频分类深度学习网络:
使用预先训练的卷积神经网络(如GoogLeNet)将视频转换为特征向量序列,从每一帧中提取特征。
在序列上训练LSTM网络来预测视频标签。
组装一个网络,通过合并来自两个网络的层直接对视频进行分类。
下图说明了网络架构。
要向网络输入图像序列,使用序列输入层。
使用卷积层提取特征,即对视频的每一帧单独进行卷积操作,先使用序列折叠层,再使用卷积层。
为了恢复序列结构并将输出重塑为矢量序列,需要使用序列展开层和平坦层。
要对得到的向量序列进行分类,首先包括LSTM层,然后是输出层。

负载预训练卷积网络
将视频帧转换为特征向量,使用预先训练的网络的激活。
加载一个预先训练的GoogLeNet模型使用googlenet函数。该功能需要深度学习工具箱™模型GoogLeNet网络万博1manbetx支持包。如果没有安装此支万博1manbetx持包,则该函数将提供下载链接。
netCNN = googlenet;
加载数据
下载HMBD51数据集从HMDB:一个大型的人体运动数据库并将RAR文件解压缩到一个名为“hmdb51_org”.该数据集包含约2gb的视频数据,超过51类7000个片段,例如“喝”,“运行”,“shake_hands”.
提取RAR文件后,使用支持函数万博1manbetxhmdb51Files获取视频的文件名和标签。
dataFolder =“hmdb51_org”;(文件、标签)= hmdb51Files (dataFolder);
阅读第一个视频使用readVideoHelper函数,在本例的最后定义,并查看视频的大小。这个视频是H——- - - - - -W——- - - - - -C——- - - - - -年代数组,H,W,C,年代分别为视频的高度、宽度、频道数和帧数。
idx = 1;文件名=文件(idx);视频= readVideo(文件名);大小(视频)
ans =1×4240 320 3 409
查看对应的标签。
标签(idx)
ans =分类brush_hair
若要查看视频,请使用implay函数(需要图像处理工具箱™)。该函数期望的数据范围是[0,1],因此必须先将数据除以255。或者,您可以循环遍历单个帧并使用imshow函数。
numFrames =大小(视频、4);数字为i = 1:numFrames frame = video(:,:,:,i);imshow(帧/ 255);drawnow结束
将帧转换为特征向量
利用卷积网络作为特征提取器,在输入视频帧时获取激活。将视频转换为特征向量序列,其中特征向量为的输出激活函数的最后一个池层的GoogLeNet网络(“pool5-7x7_s1”).
这个图表说明了通过网络的数据流。

要读取视频数据并调整其大小以匹配GoogLeNet网络的输入大小,请使用readVideo和centerCrop辅助函数,在本例的最后定义。这个步骤可能需要很长时间来运行。将视频转换为序列后,将序列保存在mat -文件中tempdir文件夹中。如果MAT文件已经存在,则从MAT文件加载序列而不重新转换它们。
inputSize = netCNN.Layers (1) .InputSize (1:2);layerName =“pool5-7x7_s1”;tempFile = fullfile (tempdir,“hmdb51_org.mat”);如果存在(tempFile“文件”)负载(tempFile“序列”)其他的numFiles =元素个数(文件);序列=细胞(numFiles, 1);为i = 1:numFiles fprintf("读取文件%d…\n", i, numFiles) video = readVideo(files(i));视频= centerCrop(视频、inputSize);序列{我1}=激活(layerName netCNN、视频,“OutputAs”,“列”);结束保存(tempFile,“序列”,“-v7.3”);结束
查看前几个序列的大小。每个序列都是D——- - - - - -年代数组,D是特征的数量(池化层的输出大小)和年代为视频的帧数。
序列(1:10)
ans =10×1单元阵列{1024×409单}{1024×395单}{1024×323单}{1024×246单}{1024×159单}{1024×137单}{1024×359单}{1024×191单}{1024×439单}{1024×528单}
准备训练数据
通过将数据划分为训练和验证分区并删除任何长序列,为训练准备数据。
创建培训和验证分区
分区的数据。将90%的数据分配给训练分区,10%分配给验证分区。
numObservations =元素个数(序列);idx = randperm (numObservations);N = floor(0.9 * numobations);idxTrain = idx (1: N);sequencesTrain =序列(idxTrain);labelsTrain =标签(idxTrain);idxValidation = idx (N + 1:结束);sequencesValidation =序列(idxValidation);labelsValidation =标签(idxValidation);
删除长序列
网络中较典型序列长得多的序列会在训练过程中引入大量的填充。填充过多会对分类精度产生负面影响。
获取训练数据的序列长度,并将其可视化为训练数据的直方图。
numObservationsTrain =元素个数(sequencesTrain);numObservationsTrain sequenceLengths = 0 (1);为i = 1:numObservationsTrain sequence = sequencesTrain{i};sequenceLengths (i) =(序列,2)大小;结束图直方图(sequenceLengths)标题(“序列长度”)包含(“序列长度”) ylabel (“频率”)
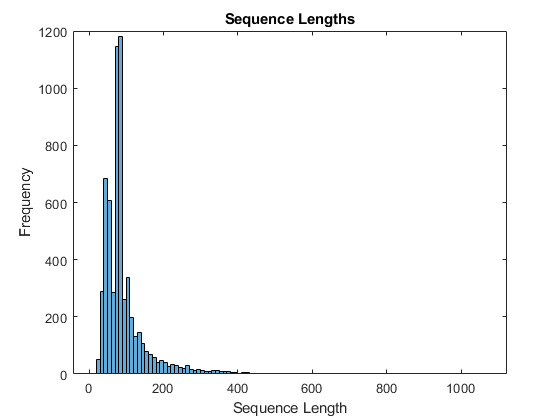
只有少数序列有超过400个时间步。为了提高分类精度,去除时间步长超过400步的训练序列及其相应的标签。
最大长度= 400;idx = sequenceLengths > maxLength;sequencesTrain (idx) = [];labelsTrain (idx) = [];
创建LSTM网络
接下来,创建一个LSTM网络,可以对代表视频的特征向量序列进行分类。
定义LSTM网络架构。指定以下网络层。
序列输入层,其输入大小与特征向量的特征维数相对应
一个包含2000个隐藏单元的BiLSTM层,然后是一个dropout层。方法只输出每个序列的一个标签
“OutputMode”选项BiLSTM层“最后一次”一种输出大小与类数对应的全连接层,一种软最大层和一种分类层。
numFeatures =大小(sequencesTrain {1}, 1);numClasses =元素个数(类别(labelsTrain));[sequenceInputLayer(numFeatures,“名字”,“序列”) bilstmLayer (2000,“OutputMode”,“最后一次”,“名字”,“bilstm”) dropoutLayer (0.5,“名字”,“下降”) fullyConnectedLayer (numClasses“名字”,“俱乐部”) softmaxLayer (“名字”,“softmax”) classificationLayer (“名字”,“分类”));
指定培训选项
属性指定培训选项trainingOptions函数。
设置小批量16,初始学习率为0.0001,梯度阈值为2(防止梯度爆炸)。
每个纪元都洗牌数据。
每个epoch验证一次网络。
在绘图中显示训练进度并抑制冗长的输出。
miniBatchSize = 16;numObservations =元素个数(sequencesTrain);numIterationsPerEpoch = floor(nummobations / miniBatchSize);选择= trainingOptions (“亚当”,...“MiniBatchSize”miniBatchSize,...“InitialLearnRate”1的军医,...“GradientThreshold”2,...“洗牌”,“every-epoch”,...“ValidationData”{sequencesValidation, labelsValidation},...“ValidationFrequency”numIterationsPerEpoch,...“阴谋”,“训练进步”,...“详细”、假);
火车LSTM网络
训练网络使用trainNetwork函数。这可能需要很长时间运行。
[netLSTM,信息]= trainNetwork (sequencesTrain、labelsTrain层,选择);
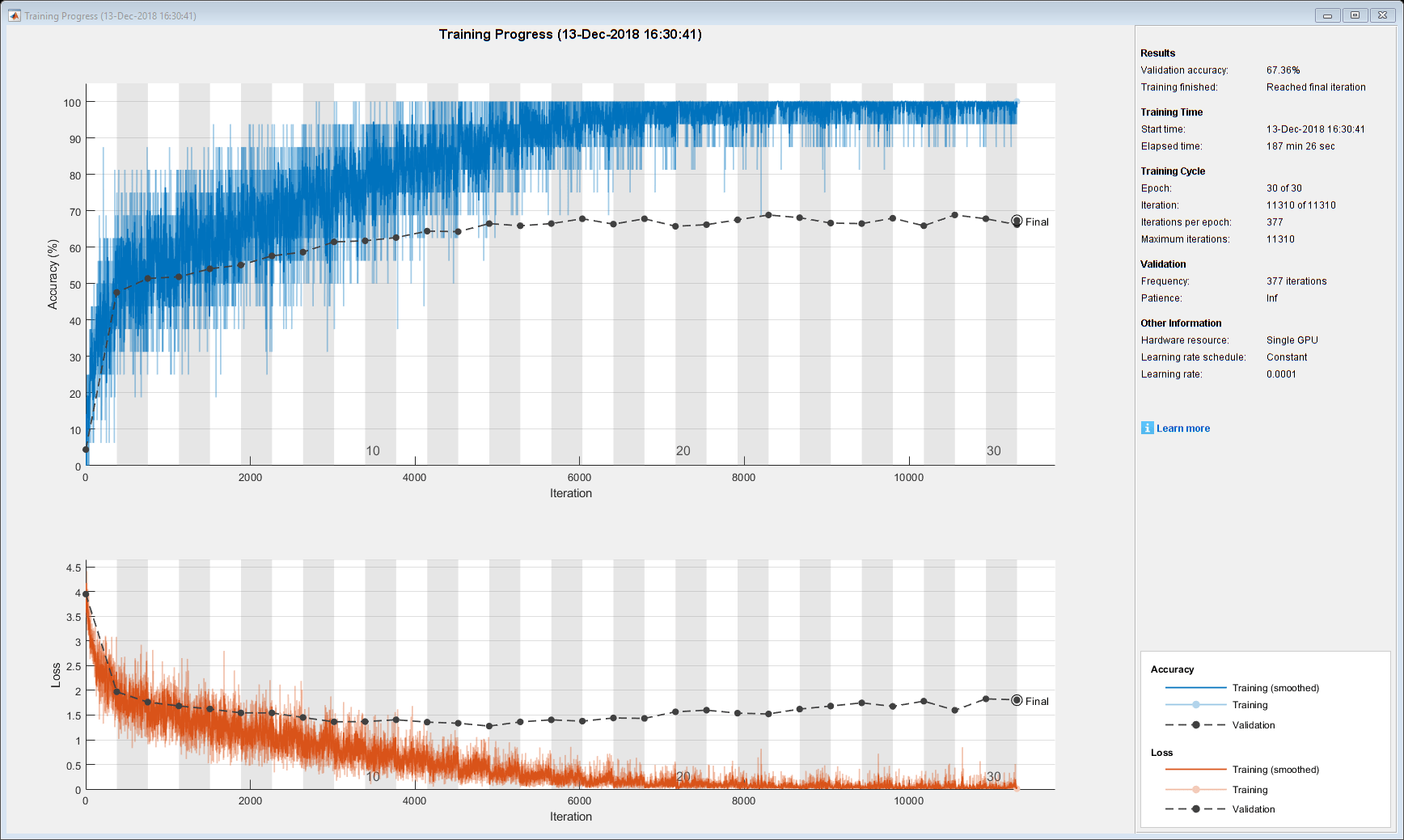
计算网络在验证集上的分类精度。使用与培训选项相同的小批量。
YPred =分类(netLSTM sequencesValidation,“MiniBatchSize”, miniBatchSize);YValidation = labelsValidation;精度=平均值(YPred == YValidation)
精度= 0.6647
组装视频分类网络
要创建一个直接对视频进行分类的网络,可以使用两个创建的网络的层来组装一个网络。利用卷积网络的层将视频转换为向量序列,利用LSTM网络的层对向量序列进行分类。
下图说明了网络架构。
要向网络输入图像序列,使用序列输入层。
使用卷积层提取特征,即对视频的每一帧单独进行卷积操作,先使用序列折叠层,再使用卷积层。
为了恢复序列结构并将输出重塑为矢量序列,需要使用序列展开层和平坦层。
要对得到的向量序列进行分类,首先包括LSTM层,然后是输出层。

添加回旋的层
首先,创建一个GoogLeNet网络的层图。
cnnLayers = layerGraph (netCNN);
删除输入层(“数据”)和用于激活的池化层之后的层(“pool5-drop_7x7_s1”,“loss3-classifier”,“概率”,“输出”).
layerNames = [“数据”“pool5-drop_7x7_s1”“loss3-classifier”“概率”“输出”];cnnLayers = removeLayers (cnnLayers layerNames);
添加序列输入层
创建一个序列输入层,接受包含与GoogLeNet网络输入大小相同的图像序列。要使用与GoogLeNet网络相同的平均图像对图像进行归一化,请设置“归一化”选项的顺序输入层“zerocenter”和“的意思是”选项为GoogLeNet输入层的平均图像。
inputSize = netCNN.Layers (1) .InputSize (1:2);averageImage = netCNN.Layers (1) .Mean;inputLayer = sequenceInputLayer([inputSize 3],...“归一化”,“zerocenter”,...“的意思是”averageImage,...“名字”,“输入”);
将序列输入层添加到层图中。为了将卷积层独立应用于序列图像,在序列输入层和卷积层之间加入序列折叠层,去除图像序列的序列结构。将序列折叠层的输出连接到第一卷积层的输入(“conv1-7x7_s2”).
[inputLayer sequenceFoldingLayer(“名字”,“折”));lgraph = addLayers (cnnLayers层);lgraph = connectLayers (lgraph,“折/”,“conv1-7x7_s2”);
添加LSTM层
通过去除LSTM网络的序列输入层,将LSTM层添加到层图中。为了恢复被序列折叠层删除的序列结构,在卷积层之后再加一个序列展开层。LSTM层期望向量序列。为了将序列展开层的输出重塑为矢量序列,在序列展开层之后再添加一个flatten层。
从LSTM网络中取出各层,去掉序列输入层。
lstmLayers = netLSTM.Layers;lstmLayers (1) = [];
将序列展开层、平坦层和LSTM层添加到层图中。连接最后一个卷积层(“pool5-7x7_s1”)输入序列展开层(“展开/”).
= [sequenceUnfoldingLayer(“名字”,“展开”) flattenLayer (“名字”,“平”) lstmLayers);lgraph = addLayers (lgraph层);lgraph = connectLayers (lgraph,“pool5-7x7_s1”,“展开/”);
若要使展开层恢复序列结构,请连接“miniBatchSize”序列折叠层的输出到序列展开层的相应输入。
lgraph = connectLayers (lgraph,“折/ miniBatchSize”,“展开/ miniBatchSize”);
组装网络
检查网络是否有效使用analyzeNetwork函数。
analyzeNetwork (lgraph)
将网络组装起来,以便可以使用assembleNetwork函数。
净= assembleNetwork (lgraph)
net = DAGNetwork with properties: Layers: [148×1 net.cnn.layer. layer]连接:[175×2 table]
使用新数据进行分类
阅读并中间裁剪视频“pushup.mp4”使用与之前相同的步骤。
文件名=“pushup.mp4”;视频= readVideo(文件名);
若要查看视频,请使用implay函数(需要图像处理工具箱)。该函数期望的数据范围是[0,1],因此必须先将数据除以255。或者,您可以循环遍历单个帧并使用imshow函数。
numFrames =大小(视频、4);数字为i = 1:numFrames frame = video(:,:,:,i);imshow(帧/ 255);drawnow结束

使用组合网络对视频进行分类。的分类函数需要一个包含输入视频的单元格数组,因此必须输入一个包含视频的1 × 1单元格数组。
视频= centerCrop(视频、inputSize);{视频}YPred =分类(净)
YPred =分类俯卧撑
辅助函数
的readVideo函数读取视频文件名并返回一个H——- - - - - -W——- - - - - -C -由- - - - - -年代数组,H,W,C,年代分别为视频的高度、宽度、频道数和帧数。
函数视频= readVideo(filename) vr = VideoReader(filename);H = vr.Height;W = vr.Width;C = 3;%预分配视频阵列numFrames =地板(虚拟现实。Duration * vr.FrameRate); video = zeros(H,W,C,numFrames);%阅读框架我= 0;而hasFrame(vr) i = i + 1;视频(::,:,我)= readFrame (vr);结束删除未分配的帧如果Size (video,4) > I video(:,:,:, I +1:end) = [];结束结束
的centerCrop函数可以裁剪视频的最长边并调整其大小inputSize.
函数sz = size(video); / /视频大小如果深圳(1)<深圳(2)%视频是横向的Idx = floor((sz(2) - sz(1))/2);视频(:1:(idx-1 ),:,:) = [];视频(:,(深圳(1)+ 1):结束 ,:,:) = [];elseif深圳(2)<深圳(1)%视频是纵向的Idx = floor((sz(1) - sz(2))/2);(1: (idx-1视频 ),:,:,:) = [];视频((深圳(2)+ 1):结束 ,:,:,:) = [];结束videoResized = imresize(视频、inputSize (1:2));结束
另请参阅
trainNetwork|trainingOptions|lstmLayer|sequenceInputLayer|sequenceFoldingLayer|sequenceUnfoldingLayer|flattenLayer
相关的话题
你也可以从以下列表中选择一个网站:
