{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
能源生产商,网格运营商和交易者必须根据电网上未来负荷的估计来做出决策。结果,准确的能量负荷预测是必需品和业务优势。
今天可用的大量数据使创建高度精确的预测模型成为可能。挑战在于开发数据分析工作流,将原始数据转化为可操作的见解。一个典型的工作流程包括四个步骤,每个步骤都有自己的挑战:
- 从不同源导入数据,例如Web Archives,数据库和电子表格
- 通过去除异常值、噪声和合并数据集来清理数据
- 使用机器学习技术基于汇总数据开发准确的预测模型
- 将模型部署为生产环境中的应用程序
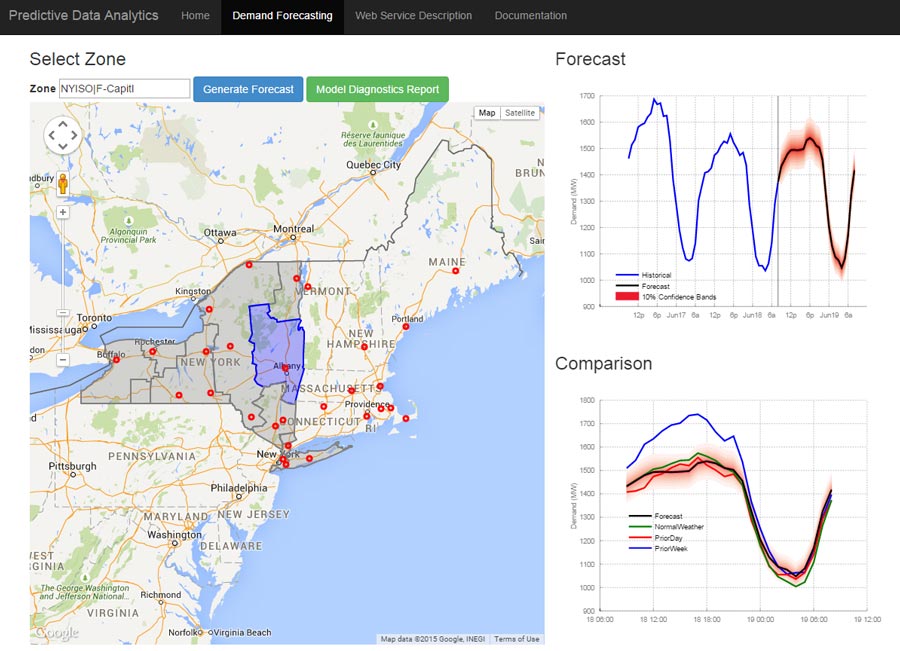
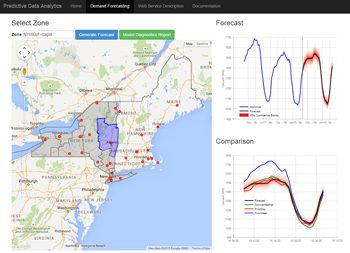
在这篇文章中,我们将使用MATLAB®完成负荷预测应用程序的整个数据分析工作流程。使用这个应用程序,实用程序分析师可以选择任何地区在纽约州的一块过去能源负载和预测未来负荷(图1)。他们可以使用结果来了解天气能源负荷的影响,并确定多大的权力来生成或购买。考虑到仅纽约州每年就消耗数十亿美元的电力,其结果对发电公司来说可能是重大的。
导入和探索数据
本案例研究使用两个数据集:来自纽约独立系统运营商(NYISO)网站,以及天气数据 - 具体而言,温度和露点 - 来自国家气候数据中心。
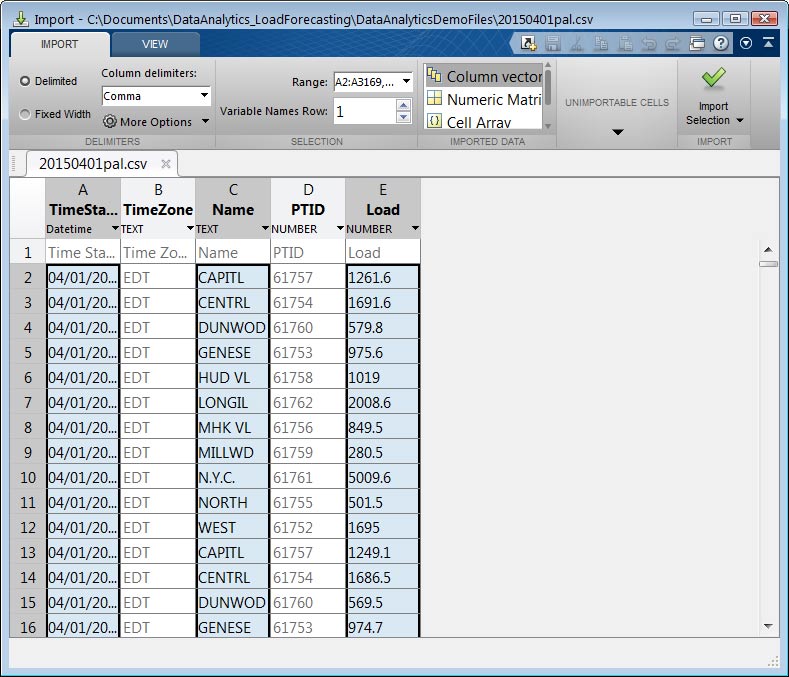
NYISO以ZIP文件的形式发布每月的能源数据,其中包含一个逗号分隔的值(CSV)文件。处理分布在多个文件中的数据的典型方法是下载一个示例文件,研究它以确定要分析的数据值,然后为整个数据集导入这些值。
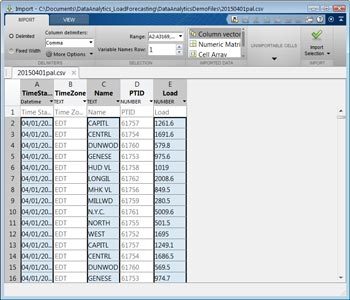
MATLAB中的导入工具让我们在CSV文件中选择列,并将所选数据导入各种MATLAB数据结构,包括向量,矩阵,单元格阵列和表。能量负载CSV包含该区域的时间戳,区域名称和负载。使用导入工具,我们选择CSV文件列和目标格式。我们可以直接导入样本文件中的数据或生成一个MATLAB函数,导入符合示例文件格式的所有文件(图2)。后来我们可以编写一个脚本,它调用此函数以编程方式从我们的源导入所有数据。
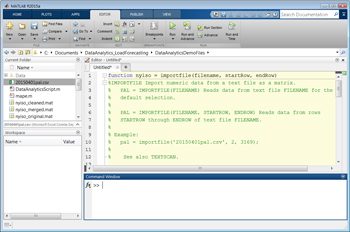
导入数据后,我们会生成初步曲线,以识别趋势,重新格式化时间和日期标记,并执行转换 - 例如,通过在数据表中交换行和列来执行转换。
清洁和汇总数据
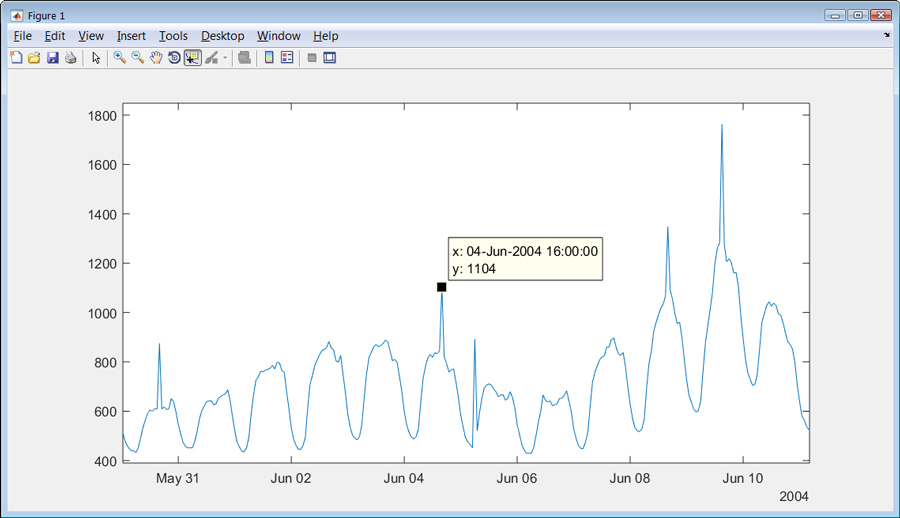
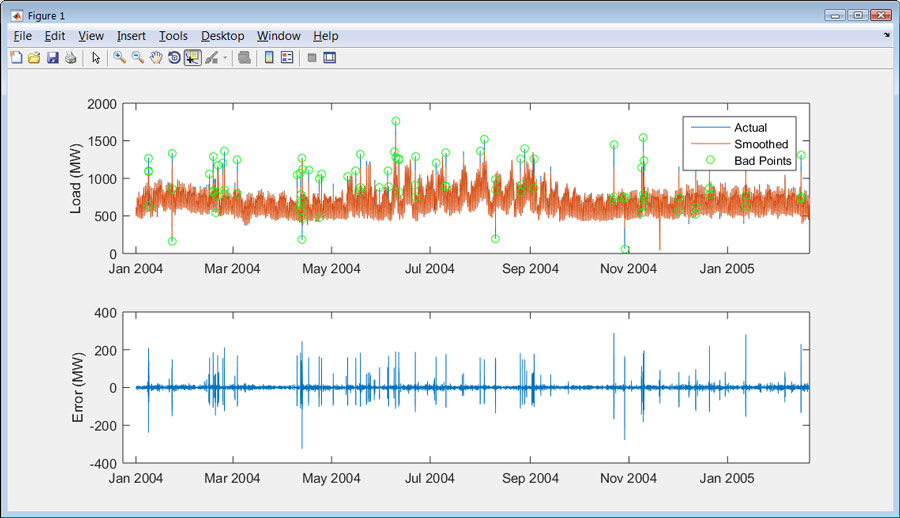
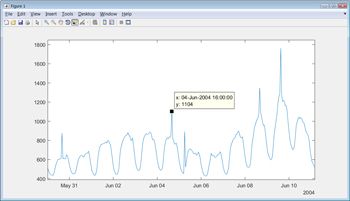
大多数真实世界的数据包含丢失的或错误的值,在探索这些数据之前,必须识别并处理这些值。重新格式化和策划NYISO数据之后,我们发现在负载峰值超出正常需求的周期性起伏(图3)。我们必须决定是否这些峰值异常和可以忽略的数据模型,或者他们是否显示模型应该考虑的一个现象。我们现在选择只研究正常的周期性行为;如果我们认为我们的模型需要解释这种行为,那么我们可以稍后处理这些峰值。
有几种方法可以自动识别钉子。例如,我们可以通过计算平滑和原始曲线之间的差异来施加平滑样条曲线并针对尖峰(图4)。
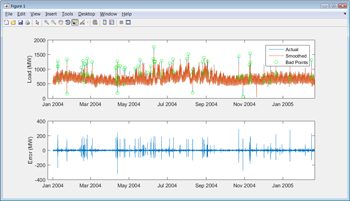
在去除数据中的异常点之后,我们必须决定如何处理由于去除异常点而引入的缺失数据点。我们可以忽略它们;这样做的好处是减少数据集的大小。或者,我们可以通过插值或使用来自另一个样本的可比数据来替换MATLAB中缺失值的近似值,注意不要对数据产生偏差。为了估计负载,我们将忽略缺失的值。我们仍然有足够的“好”数据来创建精确的模型。
使用类似技术清洁温度和露点数据后,我们聚合了两个数据集。两个数据集都存储在MATLAB表数据类型中。通过调用,我们在Matlab中应用一个表加入外延功能。结果是单个表,让我们轻松访问每次邮票的负载,温度和露点。
构建预测模型
MATLAB提供了许多用于建模数据的技术。如果我们知道不同的参数如何影响能量负载,我们可能会使用统计或曲线拟合工具来利用线性或非线性回归来模拟数据。如果有许多变量,底层系统特别复杂,或者控制方程未知,我们可以使用机器学习技术,例如决策树或神经网络。
由于负荷预测涉及到需要考虑许多变量的复杂系统,我们将选择机器学习——具体来说,监督学习。在监督学习中,基于历史输入数据(温度)和输出数据(能量负载)开发了一种模型。在培训模型后,它用于预测未来的行为。对于能量负荷预测,我们可以使用神经网络和神经网络工具箱™来完成这些步骤。工作流程如下:
-
使用Matlab中的神经拟合应用程序:
- 指定我们认为与预测负荷相关的变量,包括小时数、星期数、温度和露点
- 选择滞后指标,例如前24小时的负载
- 指定目标,或我们想要预测的变量 - 在这种情况下,能量负载
-
选择要用于训练模型的数据集,以及我们为测试保留的数据集。
对于这个例子,我们只选择一个模型。对于大多数真实单词应用程序,您将尝试几种不同的机器学习模型,并在培训和测试数据上评估其性能。统计和机器学习工具箱™提供了各种机器学习方法,所有这些方法都使用类似的呼叫语法,使得易于尝试不同的方法。该工具箱还包括分类学习者应用程序,用于互动培训监督学习模型。
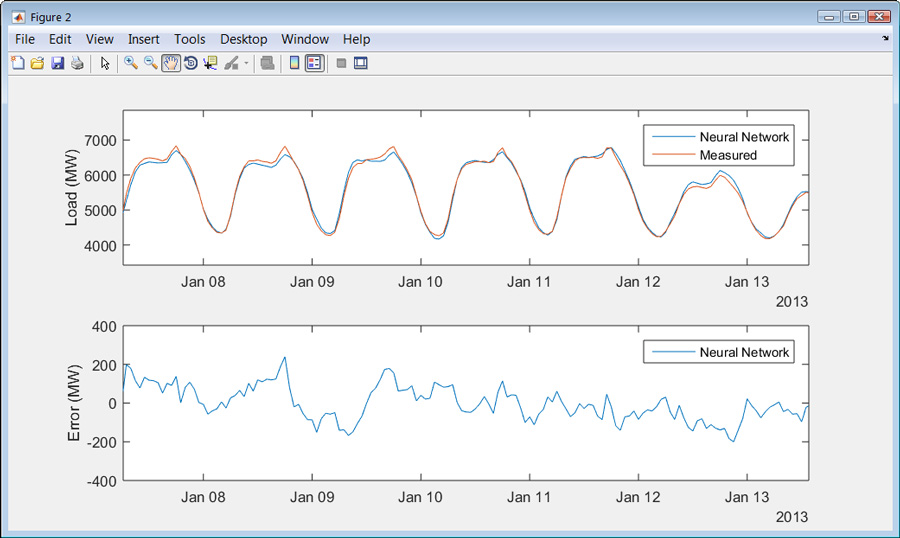
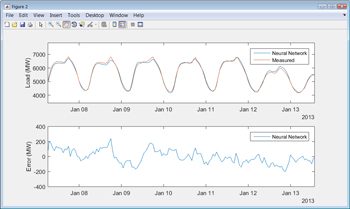
当训练完成后,我们可以使用测试数据来查看模型在新数据上的执行情况(图5)。
自动执行设置,培训和测试神经网络的步骤,我们使用神经拟合应用程序来生成我们可以从脚本中调用的MATLAB代码。
为了测试经过训练的模型,我们将它与我们保留的数据进行运行,并将其预测与实际测量数据进行比较。结果表明,该神经网络模型对试验数据的平均绝对百分比误差(MAPE)小于2%。
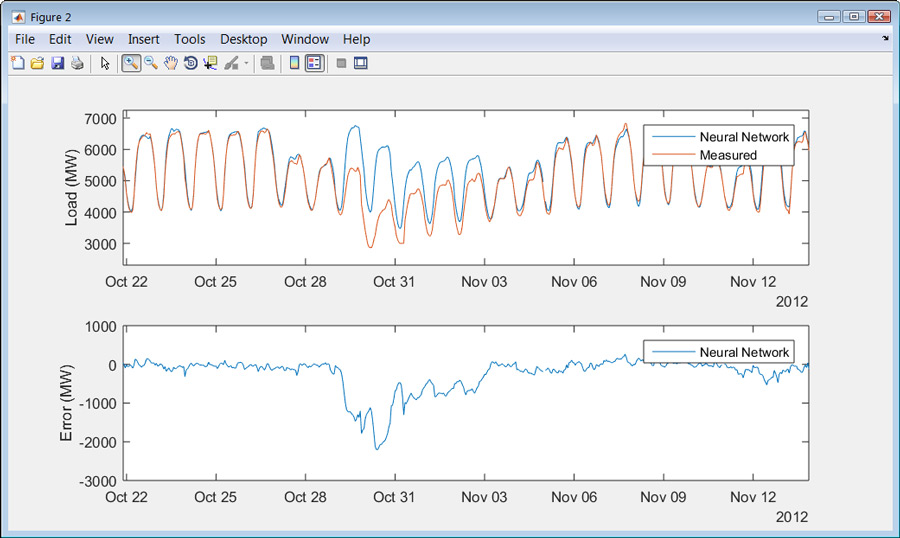
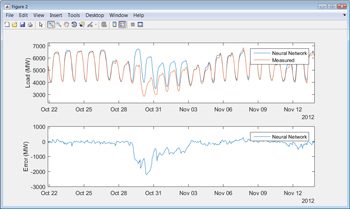
当我们首次对测试数据集进行模型时,我们会注意到几个实例,其中模型的预测从实际负载显着发散。例如,假期,我们看到偏离预测行为。我们还注意到,该模型对2012年10月29日的负荷预测,在纽约市偏离了数千兆瓦(图6)。一个快速的互联网搜索显示,在此日期,飓风桑迪扰乱了整个地区的网格。调整模型来处理假期的模型是有道理的,这是常规的,因此可预测的出现,但是桑迪这样的风暴是一次性事件,因此难以解释。
开发、测试和精炼预测模型的过程通常需要多次迭代。通过使用Parallel Computing Toolbox™在多个处理器核心上同时运行多个步骤,可以减少培训和测试时间。对于非常大的数据集,您可以通过在许多计算机上使用MATLAB并行服务器™运行这些步骤来进行扩展。
将模型部署为应用程序
一旦模型符合我们的准确性要求,最终步骤将其移动到生产系统中。我们有几个选择。使用Matlab Compiler™,我们可以生成独立的应用程序或电子表格加载项。使用Matlab Compiler SDK™,我们可以生成.NET和Java®组件。使用MATLAB生产服务器™,我们可以将应用程序直接部署到能够同时为大量用户提供服务的生产环境。
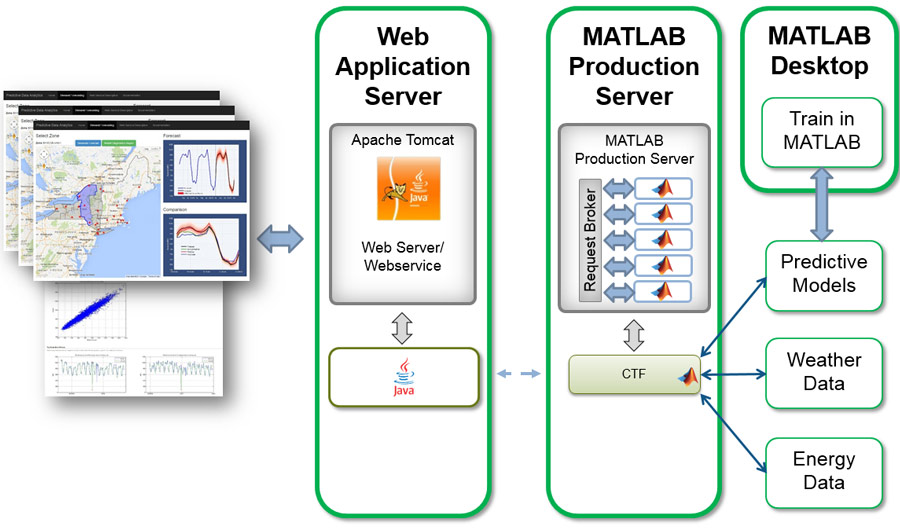
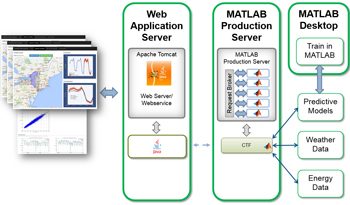
对于我们的负载预测工具,我们通过RESTful API使Matlab中的数据分析进行了可访问的数据分析,其返回可包含在应用程序或报告中的数值预测和图表。使用生产服务器编译器应用程序,我们指定要部署的MATLAB函数。该应用程序会自动执行依赖关系分析并将必要的文件打包到单个可部署组件中。使用MATLAB生产服务器我们将组件作为处理引擎部署,使网络上的任何软件或设备可用,包括Web应用程序,其他服务器和移动设备(图7)。
下一步
在此开发的能量负荷预测模型提供了高度准确的预测,可以通过Web前端由决策者使用。由于该模型已被验证超过几个月的测试数据,因此我们对其在实际负荷的2%内提供24小时预测的能力有信心。
该模型可以扩展以合并其他数据来源,例如假日日历和恶劣天气警报。由于在MATLAB代码中捕获整个数据分析工作流程,因此可以使用现有数据轻松地合并其他数据源,并且型号再培训。一旦新模型部署到MATLAB生产服务器,负载预测应用程序背后的算法就会自动更新 - 最终用户甚至不需要刷新网页。