基于深度学习的化工过程故障检测
这个例子展示了如何使用模拟数据来训练神经网络来检测化学过程中的故障。该网络对模拟过程中的故障检测具有较高的准确性。典型的工作流程如下:
预处理的数据
设计层次结构
培训网络
执行验证
测试网络
下载数据集
本例使用MathWorks®从Tennessee Eastman Process (TEP)模拟数据转换的matlab格式文件[1].这些文件可以在MathWorks支持文件站点上获得。万博1manbetx看到免责声明.
数据集由四部分组成-无故障培训、无故障测试、故障培训和故障测试。分别下载每个文件。
url =“//www.tianjin-qmedu.com/万博1manbetxsupportfiles/predmaint/chemical-process-fault-detection-data/faultytesting.mat”;websave (“faultytesting.mat”url);url =“//www.tianjin-qmedu.com/万博1manbetxsupportfiles/predmaint/chemical-process-fault-detection-data/faultytraining.mat”;websave (“faultytraining.mat”url);url ='//www.tianjin-qmedu.com/万博1manbetxsupportfiles/predmaint/chemical-process-fault-detection-data/faultfreetesting.mat';websave (“faultfreetesting.mat”url);url =“//www.tianjin-qmedu.com/万博1manbetxsupportfiles/predmaint/chemical-process-fault-detection-data/faultfreetraining.mat”;websave (“faultfreetraining.mat”url);
将下载的文件加载到MATLAB®工作空间。
负载(“faultfreetesting.mat”); 装载(“faultfreetraining.mat”); 装载(“faultytesting.mat”); 装载(“faultytraining.mat”);
每个组件包含来自模拟的数据,为两个参数的每一个排列运行:
故障编号—对于故障数据集,用1到20的整数表示不同的模拟故障。对于无故障的数据集,值为0。
模拟运行—对于所有数据集,从1到500的整数值,其中每个值代表模拟的唯一随机生成器状态。
每次模拟的长度取决于数据集。所有模拟每三分钟取样一次。
训练数据集包含来自25小时模拟的500个时间样本。
测试数据集包含来自48小时模拟的960个时间样本。
每个数据帧的列中有以下变量:
第1栏(
故障数)表示故障类型,取值范围为0 ~ 20。故障号0表示无故障,故障号1 ~ 20表示TEP中不同的故障类型。第2栏(
simulationRun)表示运行TEP模拟以获得完整数据的次数。在训练和测试数据集中,对于所有故障号,运行的次数从1到500不等。每一个simulationRun值表示模拟的不同随机生成器状态。列3 (
样品)表示每次模拟记录TEP变量的次数。对于训练数据集,这个数字从1到500不等,对于测试数据集,这个数字从1到960不等。TEP变量(列4至55)每3分钟采样一次,分别持续25小时和48小时,用于训练和测试数据集。列4-44 (
xmeas_1通过xmeas_41)包含TEP的测量变量。45 - 55(列
xmv_1通过xmv_11)包含TEP的操纵变量。
检查两个文件的子部分。
头(faultfreetraining, 4)
ans=表4×55faultNumber simulationRun sample xmeas_1 xmeas_2 xmeas_3 xmeas_4 xmeas_5 xmeas_6 xmeas_7 xmeas_8 xmeas_9 xmeas_10 xmeas_11 xmeas_12 xmeas_13 xmeas_14 xmeas_15 xmeas_16 xmeas_17 xmeas_18 xmeas_20 xmeas_21 xmeas_23 xmeas_24 xmeas_25 xmeas_26 xmeas_28 xmeas_29 xmeas_30 xmeas_31 xmeas_32 xmeas_33 xmeas_34 xmeas_35 xmeas_36xmeas_37 xmeas_38 xmeas_39 xmeas_40 xmeas_41 xmv_1 xmv_2 xmv_3 xmv_4 xmv_5 xmv_6 xmv_7 xmv_8 xmv_9 xmv_10 xmv_11 ___________ _____________ ______ _______ _______ _______ _______ _______ _______ _______ _______ _______ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ______ ______ ______ ______ ______ ______ ______ ______ ______ ______ ______ 0 1 1 3674 4529 9.232 26.889 42.402 0.25038 2704.3 74.863 120.41 0.33818 80.044 51.435 2632.9 25.029 50.5283101.1 22.819 65.732 229.61 341.22 94.64 77.047 32.188 8.8933 26.383 6.882 18.776 1.6567 32.958 13.823 23.978 1.2565 18.579 2.2633 4.8436 2.2986 0.017866 0.8357 0.098577 53.724 43.828 62.881 53.744 24.657 62.544 22.137 39.935 42.323 47.757 47.51 41.258 18.447 0 1 2705 75 0.25109 3659.4 4556.6 9.4264 26.721 42.576 120.41 0.3362 80.078 50.1543102 2633.8 24.419 48.772 23.333 65.716 230.54 341.3 94.595 77.434 32.188 8.8933 26.383 6.882 18.776 1.6567 32.958 13.823 23.978 1.2565 18.579 2.2633 4.8436 2.2986 0.017866 0.8357 0.098577 53.724 43.828 63.132 53.414 24.588 59.259 22.084 40.176 38.554 43.692 47.427 41.359 17.194 0 1 3 0.25038 3660.3 4477.8 9.4426 26.875 42.07 2706.2 74.771 120.420.33563 80.22 50.302 2635.5 25.244 50.071 3103.5 21.924 65.732 230.08 341.38 94.605 77.466 31.767 8.7694 26.095 6.8259 18.961 1.6292 32.985 13.742 23.897 1.3001 18.765 2.2602 4.8543 2.39 0.017866 0.8357 0.098577 53.724 43.828 63.117 54.357 24.666 61.275 22.38 40.244 38.99 46.699 47.468 41.199 20.53 0.24977 3661.3 4512.1 9.4776 26.758 42.063 0 1 42707.2 75.224 120.39 0.33553 80.305 49.99 2635.6 23.268 50.435 3102.8 22.948 65.781 227.91 341.71 94.473 77.443 31.767 8.7694 26.095 6.8259 13.742 23.897 1.3001 18.765 2.2602 4.8543 2.39 0.017866 0.8357 0.098577 53.724 43.828 63.1 53.946 24.725 59.856 22.277 40.257 38.072 47.541 47.658 41.643 18.089
头部(故障训练,4)
ans=表4×55数字模拟运行样本样本量量量模拟运行样本量模拟量模拟量模拟量模拟量模拟量模拟量模拟量样本量研究1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-2-1-1-1-1-1-2-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-2-2-2-2-2-2-2-2-2-2-2-2-2-2-2-2-2-2-2-2-2-2-2-2-2-2-2-2-2-2-2-U 31圣诞节32圣诞节33圣诞节34圣诞节35圣诞节36在37个圣诞节前,有37个圣诞节的圣诞圣诞活动和38个圣诞节的圣诞活动和40个圣诞节的圣诞活动和40个圣诞节的圣诞圣诞活动和1个1个1个2个2个圣诞节的2个圣诞4个圣诞5个圣诞5个圣诞8个圣诞节的圣诞活动和37个8个圣诞节的圣诞圣诞圣诞活动和8个圣诞圣诞圣诞圣诞圣诞圣诞圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞10个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞8个圣诞UUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUU________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ________ ______ ______ ______ ______ ______ ______ ______ ______ ______ ______ ______ 1 1 1 0.25038 3674 4529 9.232 26.889 42.402 2704.3 74.863 120.41 0.33818 80.044 51.435 2632.9 25.029 50.528 3101.1 22.819 65.732 229.61 341.22 94.64 77.047 32.188 8.8933 26.383 6.882 18.776 1.6567 32.958 13.823 23.978 1.2565 18.579 2.2633 4.8436 2.2986 0.017866 0.8357 0.098577 53.724 43.828 62.881 53.744 24.657 62.544 22.137 39.935 42.323 47.757 47.51 41.258 18.447 1 1 2 0.25109 3659.4 4556.6 9.4264 26.721 42.576 2705 75 120.41 0.3362 80.078 50.154 2633.8 24.419 48.772 3102 23.333 65.716 230.54 341.3 94.595 77.434 32.188 8.8933 26.383 6.882 18.776 1.6567 32.958 13.823 23.978 1.2565 18.579 2.2633 4.8436 2.2986 0.017866 0.8357 0.098577 53.724 43.828 63.132 53.414 24.588 59.259 22.084 40.176 38.554 43.692 47.427 41.359 17.194 1 1 3 0.25038 3660.3 4477.8 9.4426 26.875 42.07 2706.2 74.771 120.42 0.33563 80.22 50.302 2635.5 25.244 50.071 3103.5 21.924 65.732 230.08 341.38 94.605 77.466 31.767 8.7694 26.095 6.8259 18.961 1.6292 32.985 13.742 23.897 1.3001 18.765 2.2602 4.8543 2.39 0.017866 0.8357 0.098577 53.724 43.828 63.117 54.357 24.666 61.275 22.38 40.244 38.99 46.699 47.468 41.199 20.53 1 1 4 0.24977 3661.3 4512.1 9.4776 26.758 42.063 2707.2 75.224 120.39 0.33553 80.305 49.99 2635.6 23.268 50.435 3102.8 22.948 65.781 227.91 341.71 94.473 77.443 31.767 8.7694 26.095 6.8259 18.961 1.6292 32.985 13.742 23.897 1.3001 18.765 2.2602 4.8543 2.39 0.017866 0.8357 0.098577 53.724 43.828 63.1 53.946 24.725 59.856 22.277 40.257 38.072 47.541 47.658 41.643 18.089
干净的数据
删除训练和测试数据集中故障编号为3、9和15的数据项。这些故障编号不可识别,相关的模拟结果错误。
faultytesting (faultytesting。faultNumber == 3,:) = [];faultytesting (faultytesting。faultNumber == 9,:) = [];faultytesting (faultytesting。faultNumber == 15,:) = [];faultytraining (faultytraining。faultNumber == 3,:) = [];faultytraining (faultytraining。faultNumber == 9,:) = [];faultytraining (faultytraining。faultNumber == 15,:) = [];
把数据
通过保留20%的培训数据进行验证,将培训数据分为培训数据和验证数据。通过使用验证数据集,可以在优化模型超参数时评估训练数据集上的模型拟合。数据拆分通常用于防止网络过拟合和欠拟合。
获取故障和无故障训练数据集中的总行数。
H1 =身高(faultfreetraining);H2 =身高(faultytraining);
模拟运行是针对特定故障类型重复TEP过程的次数。从训练数据集以及测试数据集获取最大模拟运行。
msTrain=max(faultfreetraining.simulationRun);msTest=max(FaultyTest.simulationRun);
计算验证数据的最大模拟运行次数。
rTrain = 0.80;msVal = cstr (msTrain*(1 - rTrain)); / /输出msTrain = msTrain * rTrain;
获取最大样本数或时间步长(即,TEP模拟期间记录数据的最大次数)。
sampleTrain = max (faultfreetraining.sample);sampleTest = max (faultfreetesting.sample);
获取无故障和故障训练数据集中的分割点(行号),以从训练数据集中创建验证数据集。
rowLim1 =装天花板(rTrain * H1);rowLim2 =装天花板(rTrain * H2);trainingData = [faultfreetraining {1: rowLim1,:};faultytraining {1: rowLim2,:}];validationData = [faultfreetraining{rowLim1 + 1:end,:};faultytraining {rowLim2 + 1:,:}];testingData = [faultfreetesting {:,:};faultytesting {,,}):;
网络设计与预处理
最终的数据集(由训练、验证和测试数据组成)包含52个信号,500个统一时间步长。因此,信号或序列需要根据其正确的故障编号进行分类,这就成为了序列分类的问题。
正如前面在数据集一节中所描述的,数据包含52个变量,它们的值在模拟中经过一定的时间被记录。这个样品变量表示在一次模拟运行中记录这52个变量的次数。的最大值样品变量在训练数据集中为500,在测试数据集中为960。因此,对于每个模拟,都有一组长度为500或960的52个信号。每一组信号属于TEP的特定模拟运行,并指向0 - 20范围内的特定故障类型。
培训和测试数据集均包含每种故障类型的500个模拟。保留20%(来自培训)用于验证,这使得培训数据集每种故障类型有400个模拟,验证数据集每种故障类型有100个模拟。使用辅助功能helperPreprocess创建信号集,其中每个信号集是表示单个TEP模拟的单元阵列单个元素中的双矩阵。因此,最终的训练、验证和测试数据集的大小如下:
大小
Xtrain:(模拟总数)X(故障类型总数)= 400 × 18 = 7200大小
XVal:(模拟总数)X(故障类型总数)= 100 × 18 = 1800大小
Xtest:(模拟总数)X(故障类型总数)=500 X 18=9000
在数据集中,前500个模拟为0故障类型(无故障)和后续故障模拟的顺序是已知的。这种知识支持为训练、验证和测试数据集创建真正的响应。
Xtrain = helperPreprocess (trainingData sampleTrain);Ytrain =分类([0 (msTrain 1); repmat([1、2、4:8,14,十六20],1,msTrain) ');XVal = helperPreprocess (validationData sampleTrain);YVal =分类([0 (msVal 1); repmat([1、2、4:8,14,十六20],1,msVal) ');Xtest = helperPreprocess (testingData sampleTest);欧美=分类([0 (msTest 1); repmat([1、2、4:8,14,十六20],1,msTest) ');
规范化的数据集
规范化是一种将数据集中的数值按公共比例缩放而不扭曲值范围差异的技术.这项技术可以确保具有较大值的变量不会在训练中支配其他变量。它还可以将较高范围内的数值转换为较小范围(通常为-1到1),而不会丢失训练所需的任何重要信息。
使用来自训练数据集中所有模拟的数据计算52个信号的平均值和标准偏差。
t平均值=平均值(训练数据(:,4:end));tSigma=std(培训数据(:,4:end));
使用helper函数helperNormalize根据训练数据的平均值和标准偏差,对三个数据集中的每个单元格进行归一化处理。
Xtrain=helperNormalize(Xtrain、tMean、tSigma);XVal=helperNormalize(XVal、tMean、tSigma);Xtest=helperNormalize(Xtest、tMean、tSigma);
可视化数据
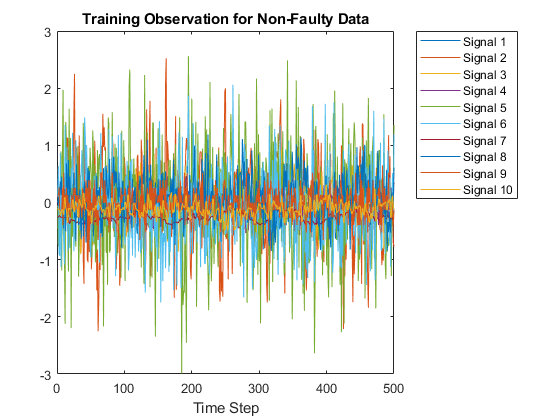
这个Xtrain数据集包含400个无故障模拟,然后是6800个故障模拟。可视化无故障和故障数据。首先,创建无故障数据的绘图。在本例中,仅在Xtrain用于创建易于阅读的图形的数据集。
图;splot = 10;情节(Xtrain {1} (1:10:) ');包含(“时间步”);标题(“非故障数据的培训观察”);传奇(“信号”+字符串(1:splot),“位置”,“northeastoutside”);
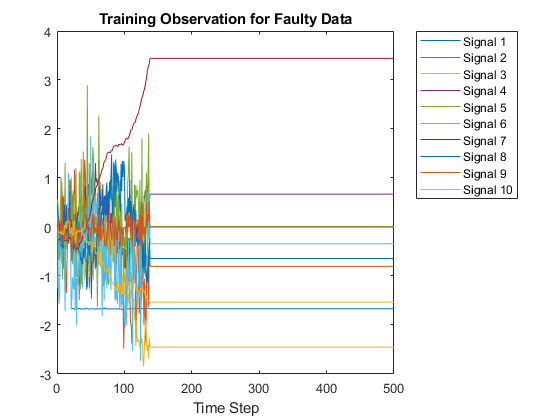
现在,通过在400之后绘制任意单元阵列元素来比较无故障图和故障图。
图;情节(Xtrain {1000} (1:10:) ');包含(“时间步”);标题(“故障数据的培训观察”);传奇(“信号”+字符串(1:splot),“位置”,“northeastoutside”);
层架构和培训选项
LSTM层是序列分类的一个很好的选择,因为LSTM层往往只记住输入序列的重要方面。
指定输入层
sequenceInputLayer与输入信号(52)的数量大小相同。指定3个LSTM隐藏层,包含52、40和25个单位。本规范的灵感来自于[2].有关使用LSTM网络进行序列分类的更多信息,请参见基于深度学习的序列分类.
在LSTM层之间添加3个dropout层,以防止过拟合。dropout层以给定的概率将下一层的输入元素随机设置为零,这样网络就不会对该层中的一小组神经元变得敏感
最后,对于分类,包括与输出类数量(18)相同大小的完全连接层。在完全连接层之后,包括分配小数概率(预测可能性)的softmax层多类问题中的每个类和分类层,以根据softmax层的输出输出最终故障类型。
numSignals = 52个;numHiddenUnits2 = 52个;numHiddenUnits3 = 40;numHiddenUnits4 = 25;numClasses = 18;层= [...sequenceInputLayer(numSignals)lstmLayer(numHiddenUnits2,“OutputMode”,“序列”)dropoutLayer(0.2)第一层(numhiddenuts3,“OutputMode”,“序列”) dropoutLayer (0.2) lstmLayer (numHiddenUnits4“OutputMode”,“最后一次”) dropoutLayer(0.2) fulllyconnectedlayer (numClasses) softmaxLayer classificationLayer];
设置所需的培训选项列车网络使用。
保持名称-值对的默认值“ExecutionEnvironment”作为“汽车”.使用此设置,软件将自动选择执行环境。默认情况下,列车网络如果GPU可用,则使用GPU,否则使用CPU。GPU上的培训需要并行计算工具箱™和支持的GPU设备。万博1manbetx有关支持的设备的信息,请参见万博1manbetxGPU版万博1manbetx本支持(并行计算工具箱).因为这个例子使用了大量的数据,使用GPU大大加快了训练时间。
设置名称-值参数对“洗牌”到“every-epoch”避免在每个时代都丢弃相同的数据。
有关深度学习的培训选项的更多信息,请参见trainingOptions.
maxEpochs = 30;miniBatchSize = 50;选择= trainingOptions (“亚当”,...“ExecutionEnvironment”,“汽车”,...“梯度阈值”1....“MaxEpochs”maxEpochs,...“MiniBatchSize”miniBatchSize,...“洗牌”,“every-epoch”,...“冗长”,0,...“阴谋”,“培训进度”,...“ValidationData”, {XVal, YVal});
列车网络
使用列车网络.
net=列车网络(Xtrain、Ytrain、图层、选项);
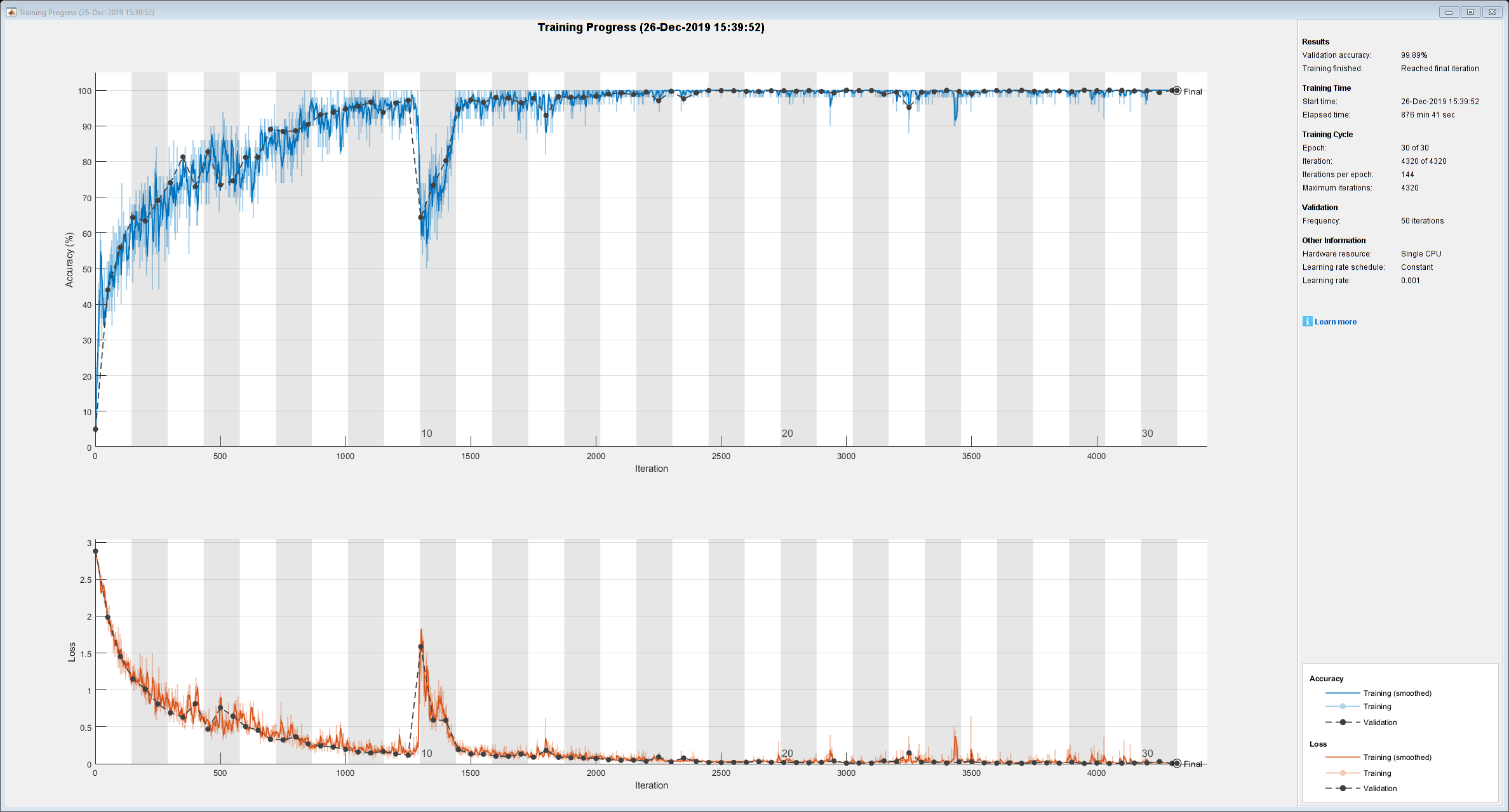
培训进度图显示了网络精度的曲线图。在图的右侧,查看有关培训时间和设置的信息。
测试网络
在测试集上运行训练过的网络,预测信号中的故障类型。
Ypred=分类(净、Xtest、,...“MiniBatchSize”miniBatchSize,...“ExecutionEnvironment”,“汽车”);
计算的准确性。准确度是测试数据中与分类相匹配的真实标签的数量分类除以测试数据中的图像数。
acc = sum(Ypred == Ytest)./numel(Ypred)
acc = 0.9992
高精度表明,神经网络能够以最小的误差成功地识别未知信号的故障类型。因此,精度越高,网络越好。
使用测试信号的真实类别标签绘制混淆矩阵,以确定网络对每个故障的识别程度。
confusionchart(欧美,Ypred);
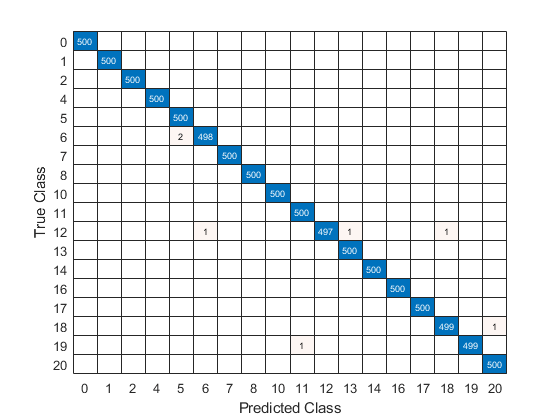
使用混淆矩阵,您可以评估分类网络的有效性。混淆矩阵在主对角线中有数值,在其他地方有零。本例中经过训练的网络是有效的,可以正确分类99%以上的信号。
参考文献
[1] 里思,C.A.,B.D.阿姆塞尔,R.Tran.,和B.Maia。“用于异常检测评估的附加田纳西-伊斯曼过程模拟数据”,《哈佛数据宇宙》,2017年第1版。https://doi.org/10.7910/DVN/6C3JR1.
Heo, S., J. H. Lee。基于人工神经网络的故障检测与分类。韩国科学技术高等研究院化学与生物分子工程系。
辅助函数
helperPreprocess
辅助函数helperPreprocess使用最大样本数对数据进行预处理。样本号表示信号长度,它在整个数据集中是一致的。for循环用信号长度滤波器遍历数据集,形成52个信号的集合。每个集合是单元格数组的一个元素。每个单元阵列代表一个单独的模拟。
函数H = size(mydata);处理= {};为ind=1:limit:hx=mydata(ind:ind+(limit-1)),4:end);processed=[processed;x'];结束结束
helperNormalize
辅助函数helperNormalize使用数据、平均值和标准偏差对数据进行归一化。
函数数据=helperNormalize(数据,m,s)为ind=1:size(data)data{ind}=(data{ind}-m)。/s;结束结束
另请参阅
第一层|列车网络|trainingOptions|sequenceInputLayer
相关的话题
你也可以从以下列表中选择一个网站:
