深度学习与MATLAB在多个gpu
神经网络本质上是并行算法。您可以使用Parallel Computing Toolbox™在多核cpu、gpu和具有多个cpu和gpu的计算机集群之间分配培训,从而利用这种并行性。
如果您可以访问具有多个gpu的机器,您可以简单地指定培训选项“multi-gpu”使用trainingOptions函数。当使用多个gpu进行训练时,每个图像批处理分布在多个gpu之间。有关使用多个gpu进行培训的更多信息,请参见使用多个gpu进行培训.
如果您想使用更多资源,可以将深度学习培训扩展到集群或云。要了解更多关于并行选项的信息,请参见并行和在云中扩展深度学习.举个例子,请看使用自动并行支持在云中训练网络万博1manbetx.
选择用于培训的特定图形处理器
如果有多个图形处理器,可以在开始培训前选择设备,使用指定的图形处理器进行单GPU培训。使用gpuDeviceTable(并行计算工具箱)函数来检查GPU并确定要使用的GPU的索引。然后,使用其索引选择该GPU:
gpuDevice(索引)
trainNetwork使用培训选项“ExecutionEnvironment”、“gpu的.
如果您想使用机器上所有可用的gpu,只需指定培训选项“ExecutionEnvironment”、“multi-gpu”.
如果你想使用多个gpu来训练一个模型,而你又不想使用所有的gpu,你可以提前打开并行池并手动选择gpu。您可能希望这样做,以避免在性能较差的显示GPU上进行训练。要选择特定的gpu,请使用以下代码gpuIndices是你想使用的图形处理器的索引:
parpool(当地的元素个数(gpuIndices));spmd gpuDevice (gpuIndices (labindex));结束
trainNetwork与“multi-gpu”
ExecutionEnvironment(或“平行”对于相同的结果),训练函数使用这个池,而不打开一个新的池。
另一种选择是选择使用“WorkerLoad”选项trainingOptions.例如:
parpool(“当地”,5);opts = trainingOptions('sgdm', 'WorkerLoad',[1 1 1 0 1],…)
在这种情况下,第4个worker是池的一部分,但空闲,这不是对并行资源的理想使用。它是更有效的指定图形处理器gpuDevice.
如果你想用一个GPU训练多个模型,为每个模型启动一个MATLAB会话,并选择一个使用的设备gpuDevice.
或者,使用一个parfor循环:
parfor i = 1: gpuDeviceCount(“可用”)trainNetwork(…);结束
使用自动并行支持在云中训练网络万博1manbetx
这个例子展示了如何使用MATLAB自动支持并行训练卷积神经网络。万博1manbetx深度学习训练通常需要数小时或数天。通过使用并行计算,您可以在本地或云中的集群中使用多个图形处理单元(gpu)加快培训速度。如果您可以访问具有多个gpu的机器,那么您可以在数据的本地副本上完成这个示例。如果你想使用更多的资源,那么你可以将深度学习培训扩展到云。要了解更多关于并行训练的选项,请参见并行和在云中扩展深度学习.这个例子指导您通过使用MATLAB自动并行支持在云中的集群中训练深度学习网络的步骤。万博1manbetx
需求
在运行示例之前,需要配置集群并将数据上传到云。在MATLAB中,您可以直接从MATLAB桌面在云中创建集群。在首页选项卡,平行菜单中,选择创建和管理集群.在集群配置文件管理器中,单击创建云计算集群.或者,您可以使用MathWorks Cloud Center来创建和访问计算集群。有关更多信息,请参见云中心入门.之后,将数据上传到Amazon S3桶,并直接从MATLAB访问它。本示例使用已经存储在Amazon S3中的CIFAR-10数据集的副本。说明,请参阅上传深度学习数据到云.
设置并行池
在集群中启动一个并行池,并将工作人员的数量设置为集群中的gpu数量。如果指定的worker多于gpu,那么剩余的worker将处于空闲状态。本例假设您使用的集群被设置为默认集群配置文件。检查MATLAB上的默认集群配置文件首页选项卡,在平行>选择默认集群.
numberOfWorkers = 8;parpool (numberOfWorkers);
使用myclusterincloud配置文件启动并行池(parpool)…连接到8个工人。
从云加载数据集
使用。从云加载训练和测试数据集imageDatastore.在本例中,使用存储在Amazon S3中的CIFAR-10数据集的副本。要确保工作人员能够访问云中的数据存储,请确保正确设置AWS凭据的环境变量。看到上传深度学习数据到云.
imdsTrain = imageDatastore (s3: / / cifar10cloud / cifar10 /火车',...“IncludeSubfolders”,真的,...“LabelSource”,“foldernames”);imdsTest = imageDatastore (s3: / / cifar10cloud / cifar10 /测试”,...“IncludeSubfolders”,真的,...“LabelSource”,“foldernames”);
通过创建一个增强的图像数据来训练网络augmentedImageDatastore对象。使用随机平移和水平反射。数据增强有助于防止网络过度拟合和记忆训练图像的确切细节。
imageSize = [32 32 3];pixelRange = [-4 4];imageAugmenter = imageDataAugmenter (...“RandXReflection”,真的,...“RandXTranslation”pixelRange,...“RandYTranslation”, pixelRange);imdsTrain augmentedImdsTrain = augmentedImageDatastore(图象尺寸,...“DataAugmentation”imageAugmenter,...“OutputSizeMode”,“randcrop”);
定义网络架构和培训选项
为CIFAR-10数据集定义一个网络架构。为了简化代码,可以使用卷积块对输入进行卷积。池化层向下采样空间维度。
blockDepth = 4;% blockDepth控制卷积块的深度netWidth = 32;% netWidth控制卷积块中过滤器的数量[imageInputLayer(imageSize)卷积块(netWidth,blockDepth) maxPooling2dLayer(2,“步”2) convolutionalBlock (2 * netWidth blockDepth) maxPooling2dLayer (2“步”,2) convolutionalBlock(4*netWidth,blockDepth) averageepooling2dlayer (8) fulllyconnectedlayer (10) softmaxLayer classificationLayer;
定义培训选项。通过将执行环境设置为,使用当前集群并行训练网络平行.当您使用多个gpu时,您将增加可用的计算资源。根据GPU的数量扩大迷你批处理的大小,以保持每个GPU上的工作负载不变。根据小批量的大小缩放学习率。使用学习率计划,随着训练的进行降低学习率。在训练过程中打开训练进度图,获取视觉反馈。
miniBatchSize = 256 * numberOfWorkers;initialLearnRate = 1e-1 * miniBatchSize/256;选择= trainingOptions (“个”,...“ExecutionEnvironment”,“平行”,...开启自动并行支持。万博1manbetx“InitialLearnRate”initialLearnRate,...%设置初始学习率。“MiniBatchSize”miniBatchSize,...%设置MiniBatchSize。“详细”假的,...%不发送命令行输出。“阴谋”,“训练进步”,...打开训练进度图。“L2Regularization”1平台以及...“MaxEpochs”, 50岁,...“洗牌”,“every-epoch”,...“ValidationData”imdsTest,...“ValidationFrequency”、地板(元素个数(imdsTrain.Files) / miniBatchSize),...“LearnRateSchedule”,“分段”,...“LearnRateDropFactor”, 0.1,...“LearnRateDropPeriod”, 45岁);
训练网络和分类使用
训练集群中的网络。在训练期间,情节显示了进展。
净= trainNetwork (augmentedImdsTrain、层、期权)
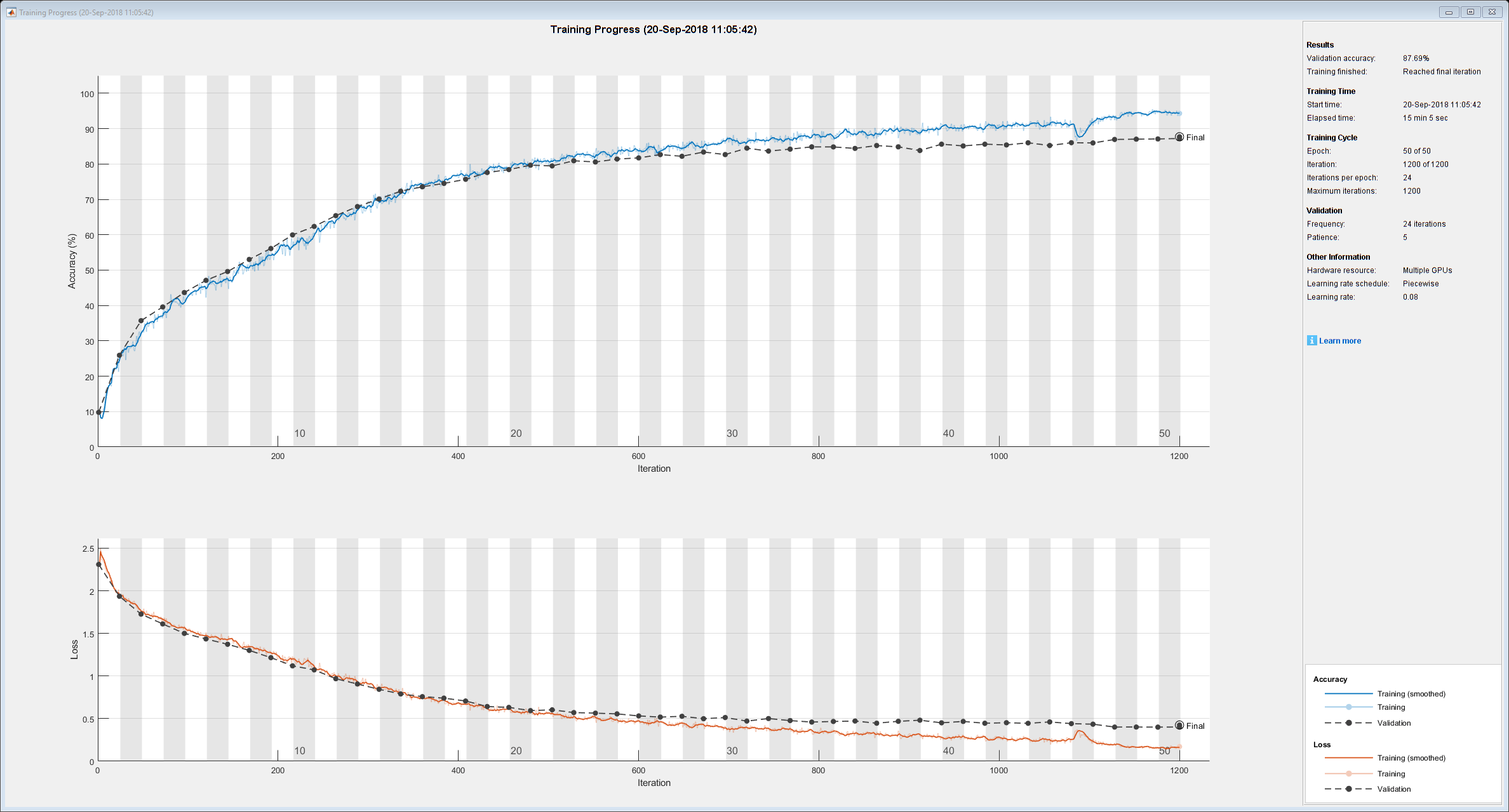
net = SeriesNetwork with properties: Layers: [43×1 net.cnn.layer. layer]
通过使用经过训练的网络对本地机器上的测试图像进行分类,确定网络的准确性。然后比较预测的标签和实际的标签。
YPredicted =分类(净,imdsTest);精度= sum(YPredicted == imdsTest.Labels)/numel(imdsTest.Labels)
定义辅助函数
定义一个函数在网络架构中创建一个卷积块。
函数layers =[卷积2dlayer (3,numFilters, numConvLayers)] layer =[卷积2dlayer (3,numFilters,“填充”,“相同”) batchNormalizationLayer reluLayer];层= repmat(层numConvLayers 1);结束
另请参阅
imageDatastore|trainingOptions|trainNetwork|gpuDevice(并行计算工具箱)|spmd(并行计算工具箱)
相关的话题
你也可以从以下列表中选择一个网站:
