用2型FIS预测混沌时间序列
这个例子展示了使用调优的2型模糊推理系统(FIS)进行混沌时间序列预测。本示例使用粒子群优化优化FIS,这需要Global optimization Toolbox™软件。
时间序列数据
本例使用以下形式的麦基-格拉斯(MG)非线性时滞微分方程来模拟时间序列数据。
使用以下配置模拟1200个样本的时间序列。
样品时间<年代pan class="inlineequation"> 证券交易委员会
初始条件<年代pan class="inlineequation">
为<年代pan class="inlineequation"> .
Ts = 1;numSamples = 1200;Tau = 20;x = 0 (1,numSamples+tau+1);X (tau+1) = 1.2;<年代pan style="color:#0000FF">为t = 1 +τ:numSamples + x (t-tau) /τx_dot = 0.2 * (1 + (x (t-tau)) ^ 10) -0.1 * x (t);X (t+1) = X (t) + ts*x_dot;<年代pan style="color:#0000FF">结束
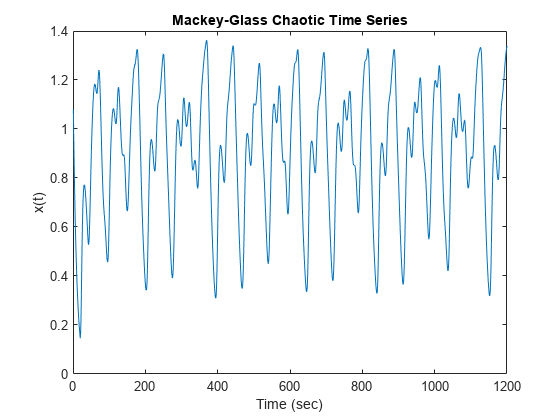
绘制模拟MG时间序列数据。
图(1)plot(x(tau+2:end))<年代pan style="color:#A020F0">“麦基-格拉斯混沌时间序列”)包含(<年代pan style="color:#A020F0">的时间(秒)) ylabel (<年代pan style="color:#A020F0">“x (t)”)
生成培训和验证数据
时间序列预测使用到某一时刻的已知时间序列值<年代pan class="emphasis">t预测未来的值<年代pan class="inlineequation"> .这类预测的标准方法是创建映射<年代pan class="emphasis">D采样数据点,每Δ单位采样一次(<年代pan class="inlineequation"> )变为预测的未来值<年代pan class="inlineequation"> .对于本例,设置<年代pan class="inlineequation"> 而且<年代pan class="inlineequation"> .因此,对于每个<年代pan class="emphasis">t,输入输出训练数据集为<年代pan class="inlineequation"> 而且<年代pan class="inlineequation"> ,分别。换句话说,使用四个连续的已知时间序列值来预测下一个值。
从样本创建1000个输入/输出数据集<年代pan class="inlineequation"> 来<年代pan class="inlineequation">
D = 4;inputData = 0 (1000,D);outputData = 0 (1000,1);<年代pan style="color:#0000FF">为t = 100+ d:1:1100+D-2<年代pan style="color:#0000FF">为inputData(t-100-D+2,i) = x(t-D+i);<年代pan style="color:#0000FF">结束outputData(t-100- d +2,:) = x(t+1);<年代pan style="color:#0000FF">结束
使用前500个数据集作为训练数据(trnX而且trnY)和第二500组作为验证数据(vldX而且vldY).
trnX = inputData(1:500,:);trnY = outputData(1:500,:);vldX = inputData(501:end,:);vdy = outputData(501:end,:);
构建金融中间人
本例使用2型Sugeno FIS。由于Sugeno FIS比Mamdani FIS具有更少的可调参数,Sugeno系统通常在优化过程中收敛得更快。
Fisin = sugfistype2;
添加三个输入,每个输入都有三个默认的三角成员函数(mf)。最初,通过设置每个下MF等于其对应的上MF,消除每个输入MF的不确定性足迹(FOU)。为此,将每个低MF的刻度和滞后值设置为1而且0,分别。通过消除所有输入成员函数的FOU,可以将2型FIS配置为与1型FIS类似的行为。
numInputs = D;numInputMFs = 3;Range = [min(x) max(x)];<年代pan style="color:#0000FF">为i = 1:numInputs(输入值)<年代pan style="color:#A020F0">“NumMFs”, numInputMFs);<年代pan style="color:#0000FF">为j = 1:numInputMFs finin . inputs (i). membershipfunctions (j)。LowerScale = 1;fisin.Inputs (i) .MembershipFunctions (j)。LowerLag = 0;<年代pan style="color:#0000FF">结束结束
对于预测,向FIS添加一个输出。输出包含默认的常量成员函数。要为输入输出映射提供最大分辨率,请将输出MF的数量设置为输入MF组合的数量。
numOutputMFs = numInputMFs^numInputs;fisin = addOutput(fisin,range,<年代pan style="color:#A020F0">“NumMFs”, numOutputMFs);
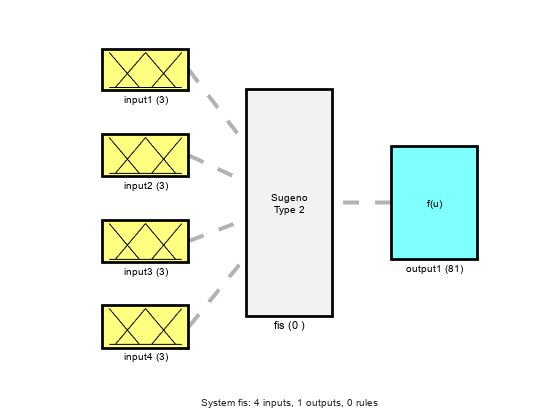
查看FIS的结构。最初,FIS没有任何规则。系统的规则是在优化过程中发现的。
plotfis (fisin)
使用训练数据调整FIS
要调优FIS,可以使用以下三个步骤。
学习规则库,同时保持输入和输出MF参数不变。
在保持规则和下MF参数不变的情况下,调优输出MF参数和输入上MF参数。
调优输入的下MF参数,同时保持规则、输出MF和上MF参数不变。
第一步由于规则参数较少,计算量较少,在训练过程中快速收敛到模糊规则库。在第二步之后,系统是经过训练的1型FIS。第三步生成调优的2型FIS。
学习规则
方法来指定调优选项tunefisOptions对象。
options = tunefisOptions;
由于FIS不包含任何预调模糊规则,使用全局优化方法(遗传算法或粒子群)来学习规则。与局部优化方法(模式搜索和模拟退火)相比,全局优化方法在大参数调谐范围内表现更好。对于本例,使用粒子群优化(“particleswarm”).
选项。方法=<年代pan style="color:#A020F0">“particleswarm”;
要学习新规则,就要设置OptimizationType来“学习”.
选项。OptimizationType =<年代pan style="color:#A020F0">“学习”;
将规则的最大数量限制为输入MF组合的数量。调优规则的数量可以小于此限制,因为调优过程会删除重复的规则。
选项。NumMaxRules = numInputMFs^numInputs;
如果您有并行计算工具箱™软件,您可以通过设置来提高调优过程的速度UseParallel来真正的.如果没有“并行计算工具箱”软件,请设置UseParallel来假.
选项。UseParallel = false;
将最大迭代次数设置为10.增加迭代次数可以减少训练误差。然而,迭代次数越多,调优过程的持续时间就越长,可能会对训练数据的规则参数进行调优。
options.MethodOptions.MaxIterations = 10;
由于粒子群优化使用随机搜索,为了获得可重复的结果,初始化随机数生成器为其默认配置。
rng (<年代pan style="color:#A020F0">“默认”)
方法调优FIStunefis这个功能需要几分钟。对于本例,通过设置启用调优runtunefis来真正的.加载预训练的结果而不运行tunefis,您可以设置runtunefis来假.
Runtunefis = false;
使用指定的训练数据和选项调优FIS。
如果runtunefis fisout1 = tunefis(fisin,[],trnX,trnY,options);<年代pan style="color:#0000FF">其他的Tunedfis = load(<年代pan style="color:#A020F0">“tunedfischaotictimeseriestype2.mat”);Fisout1 = tunedfiss . Fisout1;<年代pan style="color:#0000FF">结束
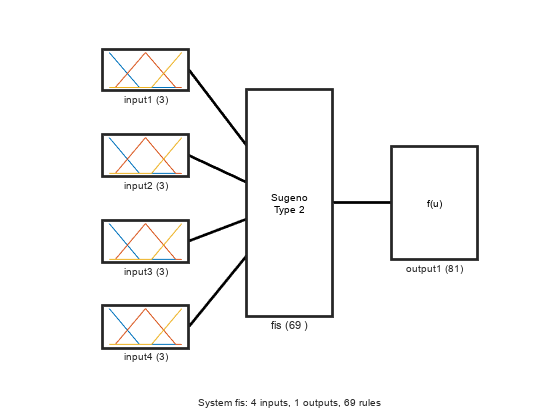
查看经过训练的FIS的结构,其中包含新的学习规则。
plotfis (fisout1)
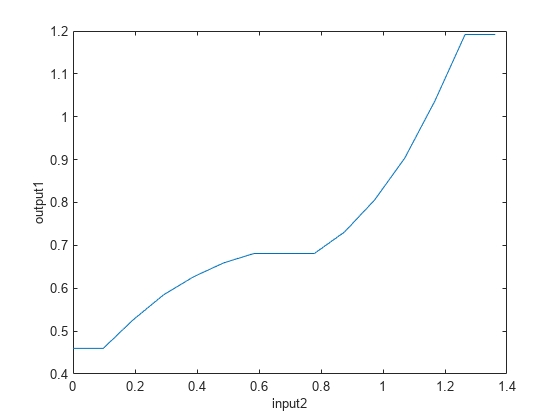
检查经过学习的规则库调优的各个输入输出关系。例如,下图显示了第二个输入和输出之间的关系。
gensurf (fisout1 gensurfOptions (<年代pan style="color:#A020F0">“InputIndex”2))
使用输入验证数据评估调优的FIS。将实际生成的输出与预期的验证输出绘制在一起,并计算均方根误差(RMSE)。
plotActualAndExpectedResultsWithRMSE (fisout1 vldX vldY)

调优上隶属函数参数
调优上层隶属函数参数。type-2 Sugeno FIS只支持万博1manbetx清晰的输出函数。因此,这一步调整输入上mf和清晰输出函数。
获取输入输出参数设置getTunableSettings.由于FIS使用三角形输入mf,您可以使用非对称滞后值调优输入mf。
[in,out] = gettunclesettings (fisout1,<年代pan style="color:#A020F0">“AsymmetricLag”,真正的);
禁用低MF参数调优。
为I = 1:长度(in)<年代pan style="color:#0000FF">为j = 1:length(in(i). membershipfunctions) in(i). membershipfunctions (j). lower scale。自由=假;(我).MembershipFunctions .LowerLag (j)。自由=假;<年代pan style="color:#0000FF">结束结束
若要优化现有的可调MF参数,同时保持规则库不变,请设置OptimizationType来“优化”.
选项。OptimizationType =<年代pan style="color:#A020F0">“优化”;
使用指定的调优数据和选项调优FIS。加载预训练的结果而不运行tunefis,您可以设置runtunefis来假.
rng (<年代pan style="color:#A020F0">“默认”)<年代pan style="color:#0000FF">如果runtunefis fisout2 = tunefis(fisout1,[in;out],trnX,trnY,options);<年代pan style="color:#0000FF">其他的Tunedfis = load(<年代pan style="color:#A020F0">“tunedfischaotictimeseriestype2.mat”);Fisout2 = tunedfiss . Fisout2;<年代pan style="color:#0000FF">结束
查看经过训练的FIS的结构,它现在包含调优的上MF参数。
plotfis (fisout2)
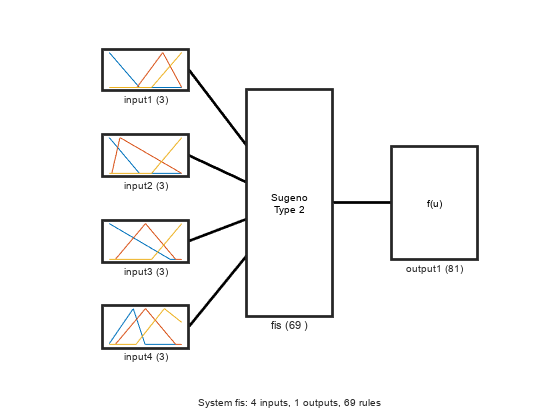
使用验证数据评估调优的FIS,计算RMSE,并将实际生成的输出与预期的验证输出绘制图。
plotActualAndExpectedResultsWithRMSE (fisout2 vldX vldY)
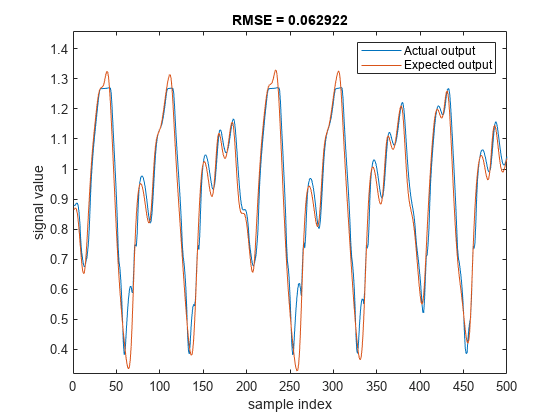
调优上MF参数可以提高FIS的性能。这个结果等价于调优1型FIS。
调低隶属函数参数
只调优输入的低MF参数。为此,设置较低的刻度和滞后值可调,并禁用调高MF参数。
为I = 1:长度(in)<年代pan style="color:#0000FF">为j = 1:length(in(i). membershipfunctions) in(i). membershipfunctions (j). upperparameters。自由=假;(我).MembershipFunctions .LowerScale (j)。自由=真;(我).MembershipFunctions .LowerLag (j)。自由=真;<年代pan style="color:#0000FF">结束结束
使用指定的调优数据和选项调优FIS。加载预训练的结果而不运行tunefis,您可以设置runtunefis来假.
rng (<年代pan style="color:#A020F0">“默认”)<年代pan style="color:#0000FF">如果runtunefis fisout3 = tunefis(fisout2,in,trnX,trnY,options);<年代pan style="color:#0000FF">其他的Tunedfis = load(<年代pan style="color:#A020F0">“tunedfischaotictimeseriestype2.mat”);Fisout3 = tunedfiss . Fisout3;<年代pan style="color:#0000FF">结束
经过训练的FIS的视图结构,现在包含调优的低MF参数。
plotfis (fisout3)
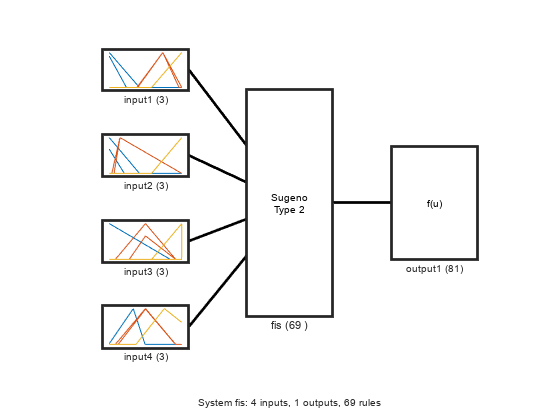
使用验证数据评估调优的FIS,计算RMSE,并将实际生成的输出与预期的验证输出绘制图。
plotActualAndExpectedResultsWithRMSE (fisout3 vldX vldY)
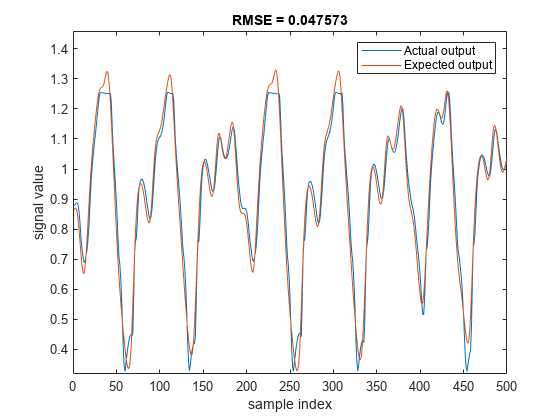
调优上下MF值可以提高FIS的性能。当训练的FIS同时包含调优的上、下参数值时,RMSE得到改善。
结论
与type-1 mf相比,Type-2 mf提供了额外的可调参数。因此,在训练数据充足的情况下,调优的2型FIS比调优的1型FIS更能拟合训练数据。
总之,通过修改下列FIS属性或调优选项,您可以产生不同的调优结果:
输入数量
mf数量
mf的类型
优化方法
调优迭代次数
本地函数
函数[rmse,actY] = calculateRMSE(fis,x,y)<年代pan style="color:#228B22">指定FIS评估选项evalOptions = evalfisOptions(<年代pan style="color:#A020F0">“EmptyOutputFuzzySetMessage”,<年代pan style="color:#A020F0">“没有”,<年代pan style="color:#0000FF">...“NoRuleFiredMessage”,<年代pan style="color:#A020F0">“没有”,<年代pan style="color:#A020F0">“OutOfRangeInputValueMessage”,<年代pan style="color:#A020F0">“没有”);<年代pan style="color:#228B22">%评估FISactY = evalfis(fis,x,evalOptions);<年代pan style="color:#228B22">%计算RMSEdel = actY - y;Rmse =√(mean(del.^2));<年代pan style="color:#0000FF">结束函数plotActualAndExpectedResultsWithRMSE(fis,vldX,vldY) [rmse,actY] = calculateRMSE(fis,vldX,vldY);图图([actY vldY])轴([0 length(vldY) min(vldY)-0.01 max(vldY)+0.13]) xlabel(<年代pan style="color:#A020F0">“样本指数”) ylabel (<年代pan style="color:#A020F0">的信号值)标题(<年代pan style="color:#A020F0">' rmse = 'num2str (rmse)])传说([<年代pan style="color:#A020F0">“实际产出”“预期的输出”),<年代pan style="color:#A020F0">“位置”,<年代pan style="color:#A020F0">“东北”)<年代pan style="color:#0000FF">结束
另请参阅
tunefis|<年代pan itemscope itemtype="//www.tianjin-qmedu.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">sugfistype2
相关的话题
您也可以从以下列表中选择网站: