广义线性模型GYdF4y2Ba
什么是广义线性模型?GYdF4y2Ba
线性回归模型描述一个响应和一个或多个预测项之间的线性关系。然而,很多时候存在非线性关系。GYdF4y2Ba非线性回归GYdF4y2Ba描述一般的非线性模型。一类特殊的非线性模型,称为GYdF4y2Ba广义线性模型GYdF4y2Ba,使用线性方法。GYdF4y2Ba
回想一下,线性模型具有以下特点:GYdF4y2Ba
在预测值的每组值上,响应具有平均值的正态分布GYdF4y2BaμGYdF4y2Ba.GYdF4y2Ba
一个系数向量GYdF4y2BaBGYdF4y2Ba定义一个线性组合GYdF4y2BaXGYdF4y2BaBGYdF4y2Ba的预测因素GYdF4y2BaXGYdF4y2Ba.GYdF4y2Ba
模型是GYdF4y2BaμGYdF4y2Ba=GYdF4y2BaXGYdF4y2BaBGYdF4y2Ba.GYdF4y2Ba
在广义线性模型中,将这些特征推广如下:GYdF4y2Ba
在预测器的每一组值上,响应具有可预测的分布GYdF4y2Ba正常的GYdF4y2Ba,GYdF4y2Ba二项GYdF4y2Ba,GYdF4y2Ba泊松GYdF4y2Ba,GYdF4y2BaγGYdF4y2Ba,或GYdF4y2Ba逆高斯GYdF4y2Ba,参数包括平均值GYdF4y2BaμGYdF4y2Ba.GYdF4y2Ba
一个系数向量GYdF4y2BaBGYdF4y2Ba定义一个线性组合GYdF4y2BaXGYdF4y2BaBGYdF4y2Ba的预测因素GYdF4y2BaXGYdF4y2Ba.GYdF4y2Ba
A.GYdF4y2Ba链接功能GYdF4y2BaFGYdF4y2Ba将模型定义为GYdF4y2BaFGYdF4y2Ba(GYdF4y2BaμGYdF4y2Ba) =GYdF4y2BaXGYdF4y2BaBGYdF4y2Ba.GYdF4y2Ba
准备数据GYdF4y2Ba
要开始拟合回归,请将数据放入拟合函数期望的形式。所有回归技术都从数组中的输入数据开始GYdF4y2BaXGYdF4y2Ba和响应数据在一个单独的向量中GYdF4y2BaYGYdF4y2Ba,或表或数据集数组中的输入数据GYdF4y2Ba资源描述GYdF4y2Ba和响应数据作为列GYdF4y2Ba资源描述GYdF4y2Ba. 每行The input data represents one observation. Each column represents one predictor (variable).
对于表或数据集数组GYdF4y2Ba资源描述GYdF4y2Ba,表示响应变量GYdF4y2Ba“ResponseVar”GYdF4y2Ba名称-值对:GYdF4y2Ba
mdl = fitglm(资源描述,GYdF4y2Ba“ResponseVar”GYdF4y2Ba,GYdF4y2Ba“血压”GYdF4y2Ba);GYdF4y2Ba
默认情况下,响应变量是最后一列。GYdF4y2Ba
你可以用数字GYdF4y2Ba分类GYdF4y2Ba预测因子。绝对预测器是从一组固定的可能性中取值。GYdF4y2Ba
对于数字数组GYdF4y2Ba
XGYdF4y2Ba,使用GYdF4y2Ba“绝对的”GYdF4y2Ba名称-值对。例如,指示预测因子GYdF4y2Ba2.GYdF4y2Ba和GYdF4y2Ba3.GYdF4y2Ba其中6个是绝对的:GYdF4y2Bamdl=fitglm(X,y,GYdF4y2Ba“绝对的”GYdF4y2Ba,[2,3]);GYdF4y2Ba%或等价GYdF4y2Bamdl=fitglm(X,y,GYdF4y2Ba“绝对的”GYdF4y2Ba,逻辑([0 1 1 0 0]));GYdF4y2Ba
对于表或数据集数组GYdF4y2Ba
资源描述GYdF4y2Ba,拟合函数假设这些数据类型是分类的:GYdF4y2Ba逻辑向量GYdF4y2Ba
分类向量GYdF4y2Ba
字符数组GYdF4y2Ba
字符串数组GYdF4y2Ba
如果要指示数值预测器是分类的,请使用GYdF4y2Ba
“绝对的”GYdF4y2Ba名称-值对。GYdF4y2Ba
将缺少的数字数据表示为GYdF4y2Ba楠GYdF4y2Ba.若要表示其他数据类型的缺失数据,请参见GYdF4y2Ba失踪组值GYdF4y2Ba.GYdF4y2Ba
对于一个GYdF4y2Ba
“二”GYdF4y2Ba数据矩阵模型GYdF4y2BaXGYdF4y2Ba,响应GYdF4y2BaYGYdF4y2Ba可以是:GYdF4y2Ba二进制列向量-每个条目代表成功(GYdF4y2Ba
1.GYdF4y2Ba)还是失败(GYdF4y2Ba0GYdF4y2Ba).GYdF4y2Ba两列整数矩阵-第一列是每次观察的成功次数,第二列是该观察的试验次数。GYdF4y2Ba
对于一个GYdF4y2Ba
“二”GYdF4y2Ba使用表或数据集进行建模GYdF4y2Ba资源描述GYdF4y2Ba:GYdF4y2Ba使用GYdF4y2Ba
ResponseVarGYdF4y2Ba用于指定列的名称-值对GYdF4y2Ba资源描述GYdF4y2Ba这就给出了每次观察的成功次数。GYdF4y2Ba使用GYdF4y2Ba
二值化GYdF4y2Ba用于指定列的名称-值对GYdF4y2Ba资源描述GYdF4y2Ba这给出了每次观察的试验次数。GYdF4y2Ba
输入和响应数据的数据集数组GYdF4y2Ba
例如,从Excel创建数据集数组GYdF4y2Ba®GYdF4y2Ba电子表格:GYdF4y2Ba
ds =数据集(GYdF4y2Ba“XLSFile”GYdF4y2Ba,GYdF4y2Ba“hospital.xls”GYdF4y2Ba,GYdF4y2Ba…GYdF4y2Ba“ReadObsNames”GYdF4y2Ba,真正的);GYdF4y2Ba
要从工作区变量创建数据集数组,请执行以下操作:GYdF4y2Ba
负载GYdF4y2BacarsmallGYdF4y2Bads =数据集(MPG、重量);ds。年=序数(Model_Year);GYdF4y2Ba
输入和响应数据表GYdF4y2Ba
要从工作区变量创建表,请执行以下操作:GYdF4y2Ba
负载GYdF4y2BacarsmallGYdF4y2Ba台=表(MPG、重量);资源描述。年=序数(Model_Year);GYdF4y2Ba
数字矩阵的输入数据,数字向量的响应GYdF4y2Ba
例如,要从工作区变量创建数字数组:GYdF4y2Ba
负载GYdF4y2BacarsmallGYdF4y2BaX=[重量马力气缸型号_年];y=MPG;GYdF4y2Ba
要从Excel电子表格创建数字数组,请执行以下操作:GYdF4y2Ba
[X, Xnames] = xlsread(GYdF4y2Ba“hospital.xls”GYdF4y2Ba);y = X (:, 4);GYdF4y2Ba反应y为收缩压GYdF4y2BaX(:,4)=[];GYdF4y2Ba从X矩阵中去掉yGYdF4y2Ba
请注意非数字项,例如GYdF4y2Ba性别GYdF4y2Ba,不出现在GYdF4y2BaXGYdF4y2Ba.GYdF4y2Ba
选择广义线性模型和连接函数GYdF4y2Ba
通常,你的数据表明了广义线性模型的分布类型。GYdF4y2Ba
| 响应数据类型GYdF4y2Ba | 建议的模型分布类型GYdF4y2Ba |
|---|---|
| 任何实数GYdF4y2Ba | “正常”GYdF4y2Ba |
| 任何正数GYdF4y2Ba | “伽马”GYdF4y2Ba或GYdF4y2Ba逆高斯分布的GYdF4y2Ba |
| 任何非负整数GYdF4y2Ba | “泊松”GYdF4y2Ba |
从0到GYdF4y2BaNGYdF4y2Ba,在那里GYdF4y2BaNGYdF4y2Ba是一个固定的正值吗GYdF4y2Ba |
“二”GYdF4y2Ba |
属性设置模型分布类型GYdF4y2Ba分配GYdF4y2Ba名称-值对。在选择模型类型之后,选择一个链接函数来映射平均值GYdF4y2BaµGYdF4y2Ba和线性预测器GYdF4y2BaXbGYdF4y2Ba.GYdF4y2Ba
| 价值GYdF4y2Ba | 描述GYdF4y2Ba |
|---|---|
“comploglog”GYdF4y2Ba |
日志(日志((1 -GYdF4y2BaµGYdF4y2Ba))) =GYdF4y2BaXbGYdF4y2Ba |
|
µGYdF4y2Ba=GYdF4y2BaXbGYdF4y2Ba |
|
日志(GYdF4y2BaµGYdF4y2Ba) =GYdF4y2BaXbGYdF4y2Ba |
|
日志(GYdF4y2BaµGYdF4y2Ba/ (1 -GYdF4y2BaµGYdF4y2Ba)) =GYdF4y2BaXbGYdF4y2Ba |
|
日志(–日志(GYdF4y2BaµGYdF4y2Ba)) =GYdF4y2BaXbGYdF4y2Ba |
“probit”GYdF4y2Ba |
ΦGYdF4y2Ba1GYdF4y2Ba(GYdF4y2BaµGYdF4y2Ba) =GYdF4y2BaXbGYdF4y2Ba,其中Φ是正态(高斯)累积分布函数GYdF4y2Ba |
“互惠的”GYdF4y2Ba,默认为发行版GYdF4y2Ba“伽马”GYdF4y2Ba |
µGYdF4y2Ba1GYdF4y2Ba=GYdF4y2BaXbGYdF4y2Ba |
|
µGYdF4y2BaPGYdF4y2Ba=GYdF4y2BaXbGYdF4y2Ba |
窗体的单元格数组GYdF4y2Ba |
用户指定的链接函数(参见GYdF4y2Ba自定义链接功能GYdF4y2Ba)GYdF4y2Ba |
非默认链接函数主要用于二项模型。这些非默认的链接函数是GYdF4y2Ba“comploglog”GYdF4y2Ba,GYdF4y2Ba“重对数”GYdF4y2Ba,GYdF4y2Ba“probit”GYdF4y2Ba.GYdF4y2Ba
自定义链接功能GYdF4y2Ba
link函数定义了这种关系GYdF4y2BaFGYdF4y2Ba(GYdF4y2BaµGYdF4y2Ba) =GYdF4y2BaXbGYdF4y2Ba在平均响应之间GYdF4y2BaµGYdF4y2Ba线性组合GYdF4y2BaXbGYdF4y2Ba=GYdF4y2BaXGYdF4y2Ba*GYdF4y2BaBGYdF4y2Ba的预测因素。您可以选择一个内置的链接函数,也可以通过指定链接函数来定义自己的链接函数GYdF4y2Ba佛罗里达州GYdF4y2Ba,它的导数GYdF4y2BaFDGYdF4y2Ba,及其逆GYdF4y2BaFIGYdF4y2Ba:GYdF4y2Ba
链接功能GYdF4y2Ba
佛罗里达州GYdF4y2Ba计算GYdF4y2BaFGYdF4y2Ba(GYdF4y2BaµGYdF4y2Ba).GYdF4y2Ba链接函数的导数GYdF4y2Ba
FDGYdF4y2Ba计算GYdF4y2BadfGYdF4y2Ba(GYdF4y2BaµGYdF4y2Ba)/GYdF4y2BadµGYdF4y2Ba.GYdF4y2Ba反函数GYdF4y2Ba
FIGYdF4y2Ba计算GYdF4y2BaGGYdF4y2Ba(GYdF4y2BaXbGYdF4y2Ba) =GYdF4y2BaµGYdF4y2Ba.GYdF4y2Ba
你可以用两种等价的方式来指定一个自定义链接函数。每种方法都包含接受表示值的单个数组的函数句柄GYdF4y2BaµGYdF4y2Ba或GYdF4y2BaXbGYdF4y2Ba,并返回相同大小的数组。函数句柄要么在单元格数组中,要么在结构中:GYdF4y2Ba
窗体的单元格数组GYdF4y2Ba
{FL FD FI}GYdF4y2Ba,包含三个函数句柄,使用GYdF4y2Ba@GYdF4y2Ba,定义链接(GYdF4y2Ba佛罗里达州GYdF4y2Ba),链接的导数(GYdF4y2BaFDGYdF4y2Ba),以及反向链接(GYdF4y2BaFIGYdF4y2Ba).GYdF4y2Ba结构GYdF4y2Ba
sGYdF4y2Ba@GYdF4y2Ba:GYdF4y2BasGYdF4y2BalinkGYdF4y2BasGYdF4y2Ba.DerivativeGYdF4y2BasGYdF4y2Ba.InverseGYdF4y2Ba
例如,使用GYdF4y2Ba“probit”GYdF4y2Ba链接功能:GYdF4y2Ba
X = [2100 2300 2500 2700 2900GYdF4y2Ba…GYdF4y2Ba3100 3300 3500 3700 3900 4100 4300]';N = [48 42 31 34 31 21 23 23 21 16 17 21]';Y = [1 2 0 3 8 8 14 17 19 15 17 21];(x,[y n],GYdF4y2Ba…GYdF4y2Ba“线性”GYdF4y2Ba,GYdF4y2Ba“分配”GYdF4y2Ba,GYdF4y2Ba“二”GYdF4y2Ba,GYdF4y2Ba“链接”GYdF4y2Ba,GYdF4y2Ba“probit”GYdF4y2Ba)GYdF4y2Ba
g =广义线性回归模型:probit(y) ~ 1 + x1分布=二项式估计系数:估计SE tStat pValue(截距)-7.3628 0.66815 -11.02 3.0701e-28 x1 0.0023039 0.00021352 10.79 3.8274e-27 12个观测值,10个误差自由度GYdF4y2Ba
的自定义链接函数可以执行相同的匹配操作GYdF4y2Ba“probit”GYdF4y2Ba链接功能:GYdF4y2Ba
s = {@norminv, @ (x) 1. / normpdf (norminv (x)), @normcdf};(x,[y n],GYdF4y2Ba…GYdF4y2Ba“线性”GYdF4y2Ba,GYdF4y2Ba“分配”GYdF4y2Ba,GYdF4y2Ba“二”GYdF4y2Ba,GYdF4y2Ba“链接”GYdF4y2Ba,年代)GYdF4y2Ba
g=广义线性回归模型:link(y)~1+x1分布=二项式估计系数:估计SE tStat pValue(Intercept)-7.3628 0.66815-11.02 3.0701e-28 x1 0.0023039 0.00021352 10.79 3.8274e-27 12个观测值,10个误差自由度离散:1 Chi^2-统计与常数模型:241,p-值=2.25e-54GYdF4y2Ba
这两种型号是一样的。GYdF4y2Ba
同样地,你可以写GYdF4y2BasGYdF4y2Ba作为一个结构而不是函数句柄的单元格数组:GYdF4y2Ba
s、 Link=@norminv;s、 导数=@(x)1./normpdf(norminv(x));s、 逆=@normcdf;g=fitglm(x,[yn],GYdF4y2Ba…GYdF4y2Ba“线性”GYdF4y2Ba,GYdF4y2Ba“分配”GYdF4y2Ba,GYdF4y2Ba“二”GYdF4y2Ba,GYdF4y2Ba“链接”GYdF4y2Ba,年代)GYdF4y2Ba
g=广义线性回归模型:link(y)~1+x1分布=二项式估计系数:估计SE tStat pValue(Intercept)-7.3628 0.66815-11.02 3.0701e-28 x1 0.0023039 0.00021352 10.79 3.8274e-27 12个观测值,10个误差自由度离散:1 Chi^2-统计与常数模型:241,p-值=2.25e-54GYdF4y2Ba
选择拟合方法和模型GYdF4y2Ba
有两种方法可以创建一个合适的模型。GYdF4y2Ba
使用GYdF4y2Ba
fitglmGYdF4y2Ba当你对你的广义线性模型有一个很好的想法,或者当你以后想要调整你的模型来包含或排除某些项。GYdF4y2Ba使用GYdF4y2Ba
stepwiseglmGYdF4y2Ba当您想要使用逐步回归拟合模型时。GYdF4y2BastepwiseglmGYdF4y2Ba从一个模型(比如一个常数)开始,每次增加或减少一个项,每次以一种贪婪的方式选择最优项,直到无法进一步改进为止。使用逐步拟合找到一个好的模型,一个只有相关条款的模型。GYdF4y2Ba结果取决于起始模型。通常,从常数模型开始会产生一个小模型。从更多项开始会产生一个更复杂的模型,但均方误差较小。GYdF4y2Ba
在这两种情况下,为拟合函数提供一个模型(它是初始模型)GYdF4y2BastepwiseglmGYdF4y2Ba).GYdF4y2Ba
使用以下方法之一指定模型。GYdF4y2Ba
短暂的型号名称GYdF4y2Ba
| 的名字GYdF4y2Ba | 模型类型GYdF4y2Ba |
|---|---|
“不变”GYdF4y2Ba |
模型只包含一个常数(截距)项。GYdF4y2Ba |
“线性”GYdF4y2Ba |
模型包含每个预测值的截距和线性项。GYdF4y2Ba |
“互动”GYdF4y2Ba |
模型包含截距、线性项和不同预测因子对的所有乘积(没有平方项)。s manbetx 845GYdF4y2Ba |
“纯二次型”GYdF4y2Ba |
模型包含截距、线性项和平方项。GYdF4y2Ba |
“二次”GYdF4y2Ba |
模型包含截距、线性项、交互和平方项。GYdF4y2Ba |
“聚GYdF4y2Ba |
模型是一个多项式,所有项都达到次GYdF4y2Ba我GYdF4y2Ba第一个预测因子是程度GYdF4y2BaJGYdF4y2Ba在第二个预测中,等等。使用数字GYdF4y2Ba0GYdF4y2Ba通过GYdF4y2Ba9GYdF4y2Ba. 例如GYdF4y2Ba‘poly2111’GYdF4y2Ba有一个常数加上所有线性项和乘积项,还包含带有预测器1平方的项。GYdF4y2Ba |
计算矩阵GYdF4y2Ba
术语矩阵GYdF4y2BaTGYdF4y2Ba是一个GYdF4y2BaTGYdF4y2Ba————(GYdF4y2BaPGYdF4y2Ba+ 1)指定模型中的项的矩阵,其中GYdF4y2BaTGYdF4y2Ba是术语的数目,GYdF4y2BaPGYdF4y2Ba是预测变量的数量,+1表示响应变量。价值GYdF4y2BaT(i,j)GYdF4y2Ba是变量的指数GYdF4y2BaJGYdF4y2Ba在术语GYdF4y2Ba我GYdF4y2Ba.GYdF4y2Ba
例如,假设一个输入包含三个预测变量GYdF4y2Bax1GYdF4y2Ba,GYdF4y2Bax2GYdF4y2Ba,GYdF4y2Bax3GYdF4y2Ba和响应变量GYdF4y2BaYGYdF4y2Ba按顺序GYdF4y2Bax1GYdF4y2Ba,GYdF4y2Bax2GYdF4y2Ba,GYdF4y2Bax3GYdF4y2Ba,GYdF4y2BaYGYdF4y2Ba. 每行GYdF4y2BaTGYdF4y2Ba表示一个术语:GYdF4y2Ba
[0 0 0]GYdF4y2Ba-常数项或截距GYdF4y2Ba[0 1 0 0]GYdF4y2Ba—GYdF4y2Bax2GYdF4y2Ba; 相当地,GYdF4y2BaX1 ^0 * x2^1 * x3^0GYdF4y2Ba[1 0 1 0]GYdF4y2Ba—GYdF4y2Bax1 * x3GYdF4y2Ba[2 0 0]GYdF4y2Ba—GYdF4y2Bax1^2GYdF4y2Ba[0 1 2 0]GYdF4y2Ba—GYdF4y2Bax2 * (x3 ^ 2)GYdF4y2Ba
这个GYdF4y2Ba0GYdF4y2Ba在每一项的末尾表示响应变量。通常,项矩阵中的零列向量表示响应变量的位置。如果在矩阵和列向量中有预测器和响应变量,则必须包括GYdF4y2Ba0GYdF4y2Ba获取每行最后一列中的响应变量。GYdF4y2Ba
公式GYdF4y2Ba
模型规范的公式是这种形式的字符向量或字符串标量GYdF4y2Ba
'GYdF4y2Ba,GYdF4y2BaYGYdF4y2Ba~GYdF4y2Ba条款GYdF4y2Ba'GYdF4y2Ba
YGYdF4y2Ba是响应名称。GYdF4y2Ba条款GYdF4y2Ba包含GYdF4y2Ba变量名GYdF4y2Ba
+GYdF4y2Ba包含下一个变量GYdF4y2Ba-GYdF4y2Ba排除下一个变量的步骤GYdF4y2Ba:GYdF4y2Ba定义一种互动,一种术语的产物GYdF4y2Ba*GYdF4y2Ba定义交互和所有低阶项的步骤GYdF4y2Ba^GYdF4y2Ba将预测器提升到一个指数,就像GYdF4y2Ba*GYdF4y2Ba重复,所以GYdF4y2Ba^GYdF4y2Ba也包括低阶术语GYdF4y2Ba()GYdF4y2Ba对术语进行分组GYdF4y2Ba
提示GYdF4y2Ba
默认情况下,公式包含常数(截距)项。要从模型中排除一个常数项,请包含GYdF4y2Ba-1GYdF4y2Ba的公式。GYdF4y2Ba
例子:GYdF4y2Ba
'y ~ x1 + x2 + x3'GYdF4y2Ba是一个具有截距的三变量线性模型。GYdF4y2Ba'y ~ x1 + x2 + x3 - 1'GYdF4y2Ba是一个无截距的三变量线性模型。GYdF4y2Ba'y~x1+x2+x3+x2^2'GYdF4y2Ba是带有截距和a的三变量模型吗GYdF4y2Bax2 ^ 2GYdF4y2Ba术语。GYdF4y2Ba‘y~x1+x2^2+x3’GYdF4y2Ba和前面的例子一样,因为GYdF4y2Bax2 ^ 2GYdF4y2Ba包括GYdF4y2Bax2GYdF4y2Ba术语。GYdF4y2Ba'y ~ x1 + x2 + x3 + x1:x2'GYdF4y2Ba包括一个GYdF4y2Bax1 * x2GYdF4y2Ba术语。GYdF4y2Ba'y ~ x1*x2 + x3'GYdF4y2Ba和前面的例子一样,因为GYdF4y2BaX1 *x2 = X1 + x2 + X1:x2GYdF4y2Ba.GYdF4y2Ba‘y~x1*x2*x3-x1:x2:x3’GYdF4y2Ba所有的相互作用GYdF4y2Bax1GYdF4y2Ba,GYdF4y2Bax2GYdF4y2Ba,GYdF4y2Bax3GYdF4y2Ba,除了三方互动。GYdF4y2Bay ~ x1*(x2 + x3 + x4)'GYdF4y2Ba所有的线性项,加上乘积s manbetx 845GYdF4y2Bax1GYdF4y2Ba和其他变量。GYdF4y2Ba
数据拟合模型GYdF4y2Ba
使用。创建一个合适的模型GYdF4y2BafitglmGYdF4y2Ba或GYdF4y2BastepwiseglmGYdF4y2Ba.在它们之间进行选择,如中所示GYdF4y2Ba选择拟合方法和模型GYdF4y2Ba. 对于非正态分布的广义线性模型,给出GYdF4y2Ba分配GYdF4y2Ba名称-值对如中所示GYdF4y2Ba选择广义线性模型和连接函数GYdF4y2Ba. 例如GYdF4y2Ba
mdl=fitglm(X,y,GYdF4y2Ba“线性”GYdF4y2Ba,GYdF4y2Ba“分布”GYdF4y2Ba,GYdF4y2Ba“泊松”GYdF4y2Ba)GYdF4y2Ba%或GYdF4y2Bamdl=fitglm(X,y,GYdF4y2Ba“二次”GYdF4y2Ba,GYdF4y2Ba…GYdF4y2Ba“分布”GYdF4y2Ba,GYdF4y2Ba“二”GYdF4y2Ba)GYdF4y2Ba
检查质量并调整模型GYdF4y2Ba
拟合模型后,检验结果。GYdF4y2Ba
模型显示GYdF4y2Ba
当您输入线性回归模型的名称或输入GYdF4y2Badisp (mdl)GYdF4y2Ba.这个显示器提供了一些基本信息,以检查拟合的模型是否充分地代表了数据。GYdF4y2Ba
例如,将泊松模型拟合到由五分之二不影响响应且无截距项的预测值构成的数据:GYdF4y2Ba
rng (GYdF4y2Ba“默认”GYdF4y2Ba)GYdF4y2Ba%为了再现性GYdF4y2BaX = randn (100 5);mu = exp(X(:,[1 4 5])*[.4;.2; 3]);y = poissrnd(μ);mdl=fitglm(X,y,GYdF4y2Ba…GYdF4y2Ba“线性”GYdF4y2Ba,GYdF4y2Ba“分布”GYdF4y2Ba,GYdF4y2Ba“泊松”GYdF4y2Ba)GYdF4y2Ba
mdl =广义线性回归模型:log(y) ~ 1 + x1 + x2 + x3 + x4 + x5Estimate SE tStat pValue (Intercept) 0.039829 0.10793 0.36901 0.71212 x1 0.38551 0.076116 5.0647 4.0895e-07 x2 -0.034905 0.086685 -0.40266 0.6872 x3 -0.17826 0.093552 -1.9054 0.056722 x4 0.21929 0.09357 2.3436 0.019097 x5 0.28918 0.1094 2.6432 0.0082126 100个观测值,94个误差自由度p-value = 1.55e-08GYdF4y2Ba
请注意:GYdF4y2Ba
显示屏包含中每个系数的估计值GYdF4y2Ba
估计GYdF4y2Ba列。这些值与真实值相当接近GYdF4y2Ba[0;.4;0;0;.2;.3]GYdF4y2Ba,可能除了的系数GYdF4y2Bax3GYdF4y2Ba离得不太近GYdF4y2Ba0GYdF4y2Ba.GYdF4y2Ba系数估计有一个标准误差列。GYdF4y2Ba
报告GYdF4y2Ba
pValueGYdF4y2Ba(由GYdF4y2BaTGYdF4y2Ba在正态误差假设下的统计)的预测因子1、4和5是小的。这是用于创建响应数据的三个预测器GYdF4y2BaYGYdF4y2Ba.GYdF4y2Ba这个GYdF4y2Ba
pValueGYdF4y2Ba对于GYdF4y2Ba(拦截)GYdF4y2Ba,GYdF4y2Bax2GYdF4y2Ba和GYdF4y2Bax3GYdF4y2Ba大于0.01。这三个预测因子不用于创建响应数据GYdF4y2BaYGYdF4y2Ba.这个GYdF4y2BapValueGYdF4y2Ba对于GYdF4y2Bax3GYdF4y2Ba刚刚结束GYdF4y2Ba.05GYdF4y2Ba,因此可能被认为是重要的。GYdF4y2Ba显示包含卡方统计数据。GYdF4y2Ba
诊断的情节GYdF4y2Ba
诊断图有助于确定离群值,并在模型或拟合中看到其他问题。为了说明这些图,考虑Logistic链函数的二项回归。GYdF4y2Ba
这个GYdF4y2Ba物流模型GYdF4y2Ba用于比例数据。它定义比例之间的关系GYdF4y2BaPGYdF4y2Ba和重量GYdF4y2BaWGYdF4y2Ba由:GYdF4y2Ba
日志(GYdF4y2BaPGYdF4y2Ba/ (1 -GYdF4y2BaPGYdF4y2Ba)] =GYdF4y2BaBGYdF4y2Ba1.GYdF4y2Ba+GYdF4y2BaBGYdF4y2Ba2.GYdF4y2BaWGYdF4y2Ba
这个例子符合二项模型的数据。这些数据是由GYdF4y2Ba卡比格垫GYdF4y2Ba,其中包含各种重量的大型汽车的测量数据。每一个重量GYdF4y2BaWGYdF4y2Ba有相应数量的汽车GYdF4y2Ba总计GYdF4y2Ba以及相应数量的低里程汽车GYdF4y2Ba贫穷的GYdF4y2Ba.GYdF4y2Ba
假设的值是合理的GYdF4y2Ba贫穷的GYdF4y2Ba遵循GYdF4y2Ba二项GYdF4y2Ba分布,试验次数由GYdF4y2Ba总计GYdF4y2Ba成功的百分比取决于GYdF4y2BaWGYdF4y2Ba.这种分布可以通过使用带有链接函数对数的广义线性模型(GYdF4y2BaµGYdF4y2Ba/ (1 -GYdF4y2BaµGYdF4y2Ba)) =GYdF4y2BaXGYdF4y2BaBGYdF4y2Ba。此链接函数被调用GYdF4y2Ba“罗吉特”GYdF4y2Ba.GYdF4y2Ba
w=[2100 2300 2500 2700 2900 3100GYdF4y2Ba…GYdF4y2Ba3300 3500 3700 3900 4100 4300]';Total = [48 42 31 34 31 21 23 23 21 16 17 21]';Poor = [1 2 0 3 8 8 14 17 19 15 17 21]';MDL = fitglm(w,[差的总数],GYdF4y2Ba…GYdF4y2Ba“线性”GYdF4y2Ba,GYdF4y2Ba“分布”GYdF4y2Ba,GYdF4y2Ba“二”GYdF4y2Ba,GYdF4y2Ba“链接”GYdF4y2Ba,GYdF4y2Ba“罗吉特”GYdF4y2Ba)GYdF4y2Ba
mdl =广义线性回归模型:logit(y) ~ 1 + x1分布=二项式估计系数:估计值SE tStat pValue (Intercept) -13.38 1.394 -9.5986 8.1019e-22 x1 0.0041812 0.00044258 9.4474 3.4739e-21 12个观测值,10个误差自由度散布:1 Chi^2-statistic vs. constant模型:242,p-value = 1.3e-54GYdF4y2Ba
查看模型与数据的拟合程度。GYdF4y2Ba
plotSlice (mdl)GYdF4y2Ba

合身度看起来相当不错,置信区间相当大。GYdF4y2Ba
要查看更多细节,请创建一个杠杆图。GYdF4y2Ba
plotDiagnostics (mdl)GYdF4y2Ba

这是由预测变量排序的点的典型回归。对于预测值相对极端的点(在任意方向),拟合中每个点的杠杆作用都更高具有平均预测值的点为低。在具有多个预测值和不按预测值排序的点的示例中,此图可以帮助您确定哪些观测值具有较高的杠杆作用,因为它们是由预测值测量的异常值。GYdF4y2Ba
残差-训练数据的模型质量GYdF4y2Ba
有几个残差图可以帮助您发现模型或数据中的错误、异常值或相关性。最简单的残差图是默认的直方图,它显示残差的范围及其频率,以及概率图,它显示残差的分布如何与具有匹配方差的正态分布相比较。GYdF4y2Ba
这个例子显示了拟合泊松模型的残差图。数据构造有5个预测器中的2个不影响响应,也没有截取项:GYdF4y2Ba
rng (GYdF4y2Ba“默认”GYdF4y2Ba)GYdF4y2Ba%为了再现性GYdF4y2BaX=randn(100,5);mu=exp(X(:,[14,5])*[2;1;.5]);y=poissrnd(mu);mdl=fitglm(X,y,GYdF4y2Ba…GYdF4y2Ba“线性”GYdF4y2Ba,GYdF4y2Ba“分布”GYdF4y2Ba,GYdF4y2Ba“泊松”GYdF4y2Ba);GYdF4y2Ba
检查残差:GYdF4y2Ba
绘图残差(mdl)GYdF4y2Ba
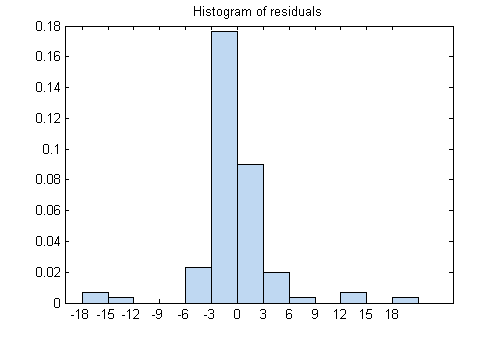
大多数残差聚在0附近,有几个在±18附近。看看另一个残差图。GYdF4y2Ba
绘图仪残差(mdl,GYdF4y2Ba“安装”GYdF4y2Ba)GYdF4y2Ba
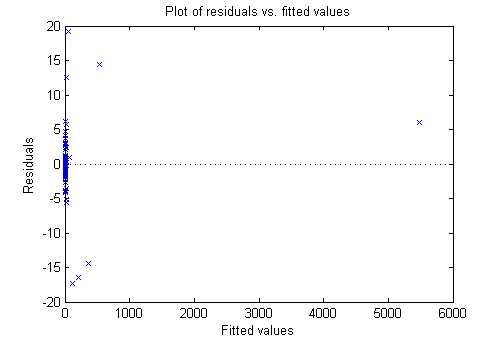
较大的残差似乎与拟合值的大小没有多大关系。GYdF4y2Ba
也许概率图能提供更多信息。GYdF4y2Ba
绘图仪残差(mdl,GYdF4y2Ba“概率”GYdF4y2Ba)GYdF4y2Ba
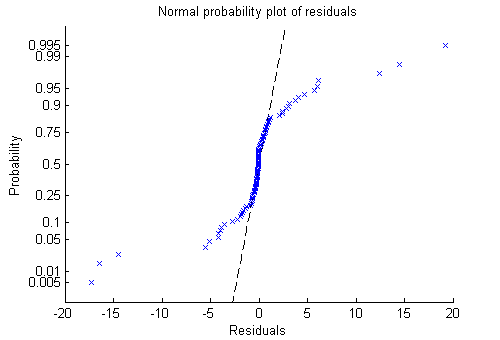
现在很清楚了。残差不服从正态分布。相反,它们有更厚的尾巴,就像潜在的泊松分布一样。GYdF4y2Ba
绘制图以了解预测效果以及如何修改模型GYdF4y2Ba
这个例子展示了如何理解每个预测因子对回归模型的影响,以及如何修改模型以删除不必要的项。GYdF4y2Ba
用人工数据建立一个预测模型。中的数据不使用第二列和第三列GYdF4y2Ba
XGYdF4y2Ba.所以你期望这个模型不会显示出对这些预测的依赖。GYdF4y2Barng (GYdF4y2Ba“默认”GYdF4y2Ba)GYdF4y2Ba%为了再现性GYdF4y2BaX=randn(100,5);mu=exp(X(:,[14,5])*[2;1;.5]);y=poissrnd(mu);mdl=fitglm(X,y,GYdF4y2Ba…GYdF4y2Ba“线性”GYdF4y2Ba,GYdF4y2Ba“分布”GYdF4y2Ba,GYdF4y2Ba“泊松”GYdF4y2Ba);GYdF4y2Ba
检查响应的切片图。这将分别显示每个预测器的效果。GYdF4y2Ba
plotSlice (mdl)GYdF4y2Ba

第一个预测器的规模压倒了整个情节。使用GYdF4y2Ba预测GYdF4y2Ba菜单GYdF4y2Ba


现在很清楚,预测因子2和3几乎没有影响。GYdF4y2Ba
您可以拖动单个预测值,这些值由蓝色虚线垂直线表示。您还可以选择由红色虚线曲线表示的同时置信限和非同时置信限。拖动预测值线可以确认预测值2和3几乎没有影响。GYdF4y2Ba
使用以下任一方法删除不必要的预测值:GYdF4y2Ba
removeTermsGYdF4y2Ba或GYdF4y2Ba一步GYdF4y2Ba. 使用GYdF4y2Ba一步GYdF4y2Ba可以更安全,以防有意外的重要性,一个术语变得明显后,删除另一个术语。然而,有时GYdF4y2BaremoveTermsGYdF4y2Ba当GYdF4y2Ba一步GYdF4y2Ba不继续。在这种情况下,两者给出了相同的结果。GYdF4y2Bamdl1 = removeTerms (mdl,GYdF4y2Ba“x2 + x3”GYdF4y2Ba)GYdF4y2Bamdl1 =广义线性回归模型:日志(y) ~ 1 + x1 + x4 + x5 =泊松分布估计系数:估计SE tStat pValue x1(拦截)0.17604 0.062215 2.8295 0.004662 0.98521 0.026393 37.328 5.6696 1.9122 0.024638 77.614 0 x4 e - 305 x5 0.61321 0.038435 15.955 2.6473 e-57 100观察,96错误自由度分散:1 Chi^2-statistic vs. constant model: 4.97e+04, p-value = 0GYdF4y2Ba
mdl1=步骤(mdl,GYdF4y2Ba“NSteps”GYdF4y2Ba5,GYdF4y2Ba“上”GYdF4y2Ba,GYdF4y2Ba“线性”GYdF4y2Ba)GYdF4y2Ba
1.去除x3, Deviance = 93.856, Chi2Stat = 0.00075551, PValue = 0.97807去除x2, Deviance = 96.333, Chi2Stat = 2.4769, PValue = 0.11553 mdl1 =广义线性回归模型:log(y) ~ 1 + x1 + x4 + x5估计SE tStat pValue (Intercept) 0.17604 0.062215 2.8295 0.004662 x1 1.9122 0.024638 77.614 0 x4 0.98521 0.026393 37.328 5.6696e-305 x5 0.61321 0.038435 15.955 2.647e -57 100个观测值,96个误差自由度GYdF4y2Ba




预测或模拟对新数据的响应GYdF4y2Ba
使用线性模型预测对新数据的响应有三种方法:GYdF4y2Ba
预测GYdF4y2Ba
这个GYdF4y2Ba预测GYdF4y2Ba该方法给出了平均响应的预测,以及(若要求)置信限。GYdF4y2Ba
此示例显示了如何使用GYdF4y2Ba预测GYdF4y2Ba方法。GYdF4y2Ba
用人工数据建立一个预测模型。中的数据不使用第二列和第三列GYdF4y2Ba
XGYdF4y2Ba. 因此,您希望模型不会显示出对这些预测值的太多依赖性。逐步构建模型,自动包含相关预测值。GYdF4y2Barng (GYdF4y2Ba“默认”GYdF4y2Ba)GYdF4y2Ba%为了再现性GYdF4y2BaX=randn(100,5);mu=exp(X(:,[14,5])*[2;1;0.5]);y=poissrnd(mu);mdl=stepwiseglm(X,y,GYdF4y2Ba…GYdF4y2Ba“不变”GYdF4y2Ba,GYdF4y2Ba“上”GYdF4y2Ba,GYdF4y2Ba“线性”GYdF4y2Ba,GYdF4y2Ba“分布”GYdF4y2Ba,GYdF4y2Ba“泊松”GYdF4y2Ba);GYdF4y2Ba
1.加上x1, Deviance = 2515.02869, Chi2Stat = 47242.9622, PValue = 0加上x4, Deviance = 328.39679, Chi2Stat = 2186.6319, PValue = 0加上x5, Deviance = 96.3326, Chi2Stat = 232.0642, PValue = 2.114384e-52GYdF4y2Ba
生成一些新的数据,并从数据中评估预测。GYdF4y2Ba
Xnew = randn(3,5) + repmat([1 2 3 4 5],[3,1]); / /重新定义GYdF4y2Ba%的新数据GYdF4y2Ba[ynew, ynewci] =预测(mdl Xnew)GYdF4y2Baynew=1.0e+04*0.1130 1.7375 3.7471 ynewci=1.0e+04*0.0821 0.1555 1.2167 2.4811 2.8419 4.9407GYdF4y2Ba
函数宏指令GYdF4y2Ba
从表或数据集数组构造模型时,GYdF4y2Ba函数宏指令GYdF4y2Ba预测平均响应通常比预测平均响应更方便GYdF4y2Ba预测GYdF4y2Ba.然而,GYdF4y2Ba函数宏指令GYdF4y2Ba不提供置信范围。GYdF4y2Ba
这个例子展示了如何使用GYdF4y2Ba函数宏指令GYdF4y2Ba方法。GYdF4y2Ba
用人工数据建立一个预测模型。中的数据不使用第二列和第三列GYdF4y2Ba
XGYdF4y2Ba. 因此,您希望模型不会显示出对这些预测值的太多依赖性。逐步构建模型,自动包含相关预测值。GYdF4y2Barng (GYdF4y2Ba“默认”GYdF4y2Ba)GYdF4y2Ba%为了再现性GYdF4y2BaX = randn (100 5);mu = exp(X(:,[1 4 5])*[2;1;.5]);y = poissrnd(μ);X = array2table (X);GYdF4y2Ba%创建数据表GYdF4y2Bay = array2table (y);tbl = [X y];mdl = stepwiseglm(资源描述,GYdF4y2Ba…GYdF4y2Ba“不变”GYdF4y2Ba,GYdF4y2Ba“上”GYdF4y2Ba,GYdF4y2Ba“线性”GYdF4y2Ba,GYdF4y2Ba“分布”GYdF4y2Ba,GYdF4y2Ba“泊松”GYdF4y2Ba);GYdF4y2Ba
1.加上x1, Deviance = 2515.02869, Chi2Stat = 47242.9622, PValue = 0加上x4, Deviance = 328.39679, Chi2Stat = 2186.6319, PValue = 0加上x5, Deviance = 96.3326, Chi2Stat = 232.0642, PValue = 2.114384e-52GYdF4y2Ba
生成一些新的数据,并从数据中评估预测。GYdF4y2Ba
Xnew = randn(3,5) + repmat([1 2 3 4 5],[3,1]); / /重新定义GYdF4y2Ba%的新数据GYdF4y2Baynew =函数宏指令(mdl Xnew (: 1), Xnew (:, 4), Xnew (:, 5))GYdF4y2Ba%只需要预测值1,4,5GYdF4y2Ba
Ynew = 1.0e+04 * 0.1130 1.7375 3.7471GYdF4y2Ba
同样,GYdF4y2Ba
ynew = feval(mdl,Xnew(:,[1 4 5]))GYdF4y2Ba%只需要预测值1,4,5GYdF4y2BaYnew = 1.0e+04 * 0.1130 1.7375 3.7471GYdF4y2Ba
随机的GYdF4y2Ba
这个GYdF4y2Ba随机的GYdF4y2Ba方法为指定的预测值生成新的随机响应值。响应值的分布是模型中使用的分布。GYdF4y2Ba随机的GYdF4y2Ba从预测器、估计系数和链接函数计算分布的平均值。对于正态分布,模型还提供响应方差的估计。对于二项分布和泊松分布,响应的方差由均值决定;GYdF4y2Ba随机的GYdF4y2Ba不使用单独的“离散”估计。GYdF4y2Ba
此示例演示如何使用GYdF4y2Ba随机的GYdF4y2Ba方法。GYdF4y2Ba
用人工数据建立一个预测模型。中的数据不使用第二列和第三列GYdF4y2Ba
XGYdF4y2Ba. 因此,您希望模型不会显示出对这些预测值的太多依赖性。逐步构建模型,自动包含相关预测值。GYdF4y2Barng (GYdF4y2Ba“默认”GYdF4y2Ba)GYdF4y2Ba%为了再现性GYdF4y2BaX=randn(100,5);mu=exp(X(:,[14,5])*[2;1;0.5]);y=poissrnd(mu);mdl=stepwiseglm(X,y,GYdF4y2Ba…GYdF4y2Ba“不变”GYdF4y2Ba,GYdF4y2Ba“上”GYdF4y2Ba,GYdF4y2Ba“线性”GYdF4y2Ba,GYdF4y2Ba“分布”GYdF4y2Ba,GYdF4y2Ba“泊松”GYdF4y2Ba);GYdF4y2Ba
1.加上x1, Deviance = 2515.02869, Chi2Stat = 47242.9622, PValue = 0加上x4, Deviance = 328.39679, Chi2Stat = 2186.6319, PValue = 0加上x5, Deviance = 96.3326, Chi2Stat = 232.0642, PValue = 2.114384e-52GYdF4y2Ba
生成一些新的数据,并从数据中评估预测。GYdF4y2Ba
Xnew = randn(3,5) + repmat([1 2 3 4 5],[3,1]); / /重新定义GYdF4y2Ba%的新数据GYdF4y2Baysim=随机(mdl,Xnew)GYdF4y2BaYsim = 1111 17121 37457GYdF4y2Ba
的预测GYdF4y2Ba
随机的GYdF4y2Ba是泊松样本,所以是整数。GYdF4y2Ba评估GYdF4y2Ba
随机的GYdF4y2Ba方法一遍,结果就变了。GYdF4y2Baysim=随机(mdl,Xnew)GYdF4y2Ba
ysim=11751732037126GYdF4y2Ba
合身型GYdF4y2Ba
模型显示包含足够的信息,使其他人能够在理论上重新创建模型。例如,GYdF4y2Ba
rng (GYdF4y2Ba“默认”GYdF4y2Ba)GYdF4y2Ba%为了再现性GYdF4y2BaX=randn(100,5);mu=exp(X(:,[14,5])*[2;1;0.5]);y=poissrnd(mu);mdl=stepwiseglm(X,y,GYdF4y2Ba…GYdF4y2Ba“不变”GYdF4y2Ba,GYdF4y2Ba“上”GYdF4y2Ba,GYdF4y2Ba“线性”GYdF4y2Ba,GYdF4y2Ba“分布”GYdF4y2Ba,GYdF4y2Ba“泊松”GYdF4y2Ba)GYdF4y2Ba
1.加x1,偏差=2515.02869,Chi2Stat=47242.9622,PValue=0.2.加x4,偏差=328.39679,Chi2Stat=2186.6319,PValue=0.3.加x5,偏差=96.3326,Chi2Stat=232.0642,PValue=2.114384e-52 mdl=广义线性回归模型:log(y)~1+x1+x4+x5分布=泊松估计系数:估计SE tStat pValue(截距)0.17604 0.062215 2.8295 0.004662 x1 1.9122 0.024638 77.614 0 x4 0.98521 0.026393 37.328 5.6696e-305 x5 0.61321 0.038435 15.955 2.6473e-57 100个观测值,96个误差自由度分散:1 Chi^2-统计与常数模型:4.97e+04,p值=0GYdF4y2Ba
您也可以通过编程方式访问模型描述。例如,GYdF4y2Ba
mdl.系数.估计GYdF4y2Ba
Ans = 0.1760 1.9122 0.9852 0.6132GYdF4y2Ba
mdl。公式GYdF4y2Ba
Ans = log(y) ~ 1 + x1 + x4 + x5GYdF4y2Ba
参考文献GYdF4y2Ba
[1] Collett D。GYdF4y2Ba二进制数据建模GYdF4y2Ba. 纽约:查普曼和霍尔,2002年。GYdF4y2Ba
多布森GYdF4y2Ba广义线性模型简介GYdF4y2Ba.纽约:查普曼与霍尔出版社,1990。GYdF4y2Ba
[3] McCullagh,P.和J.A.Nelder。GYdF4y2Ba广义线性模型GYdF4y2Ba.纽约:查普曼与霍尔出版社,1990。GYdF4y2Ba
[4] 内特,J.,M.H.库特纳,C.J.纳希特谢姆和W.瓦瑟曼。GYdF4y2Ba应用线性统计模型GYdF4y2Ba,第四版。欧文,芝加哥,1996年。GYdF4y2Ba
选择一个网站GYdF4y2Ba
选择一个网站,在那里获得翻译的内容,并看到当地的活动和优惠。根据您的位置,我们建议您选择:GYdF4y2Ba.GYdF4y2Ba
选择GYdF4y2Ba网站GYdF4y2Ba您还可以从以下列表中选择网站:GYdF4y2Ba
美洲GYdF4y2Ba
- 美国拉丁GYdF4y2Ba(西班牙语)GYdF4y2Ba
- 加拿大GYdF4y2Ba(英语)GYdF4y2Ba
- 美国GYdF4y2Ba(英语)GYdF4y2Ba
欧洲GYdF4y2Ba
- 比利时GYdF4y2Ba(英语)GYdF4y2Ba
- 丹麦GYdF4y2Ba(英语)GYdF4y2Ba
- 德国GYdF4y2Ba(德语)GYdF4y2Ba
- 埃斯帕尼亚GYdF4y2Ba(西班牙语)GYdF4y2Ba
- 芬兰GYdF4y2Ba(英语)GYdF4y2Ba
- 法国GYdF4y2Ba(法兰西)GYdF4y2Ba
- 爱尔兰GYdF4y2Ba(英语)GYdF4y2Ba
- 意大利GYdF4y2Ba(意大利语)GYdF4y2Ba
- 卢森堡GYdF4y2Ba(英语)GYdF4y2Ba
- 荷兰GYdF4y2Ba(英语)GYdF4y2Ba
- 挪威GYdF4y2Ba(英语)GYdF4y2Ba
- ÖsterreichGYdF4y2Ba(德语)GYdF4y2Ba
- 葡萄牙GYdF4y2Ba(英语)GYdF4y2Ba
- 瑞典GYdF4y2Ba(英语)GYdF4y2Ba
- 瑞士GYdF4y2Ba
- 联合王国GYdF4y2Ba(英语)GYdF4y2Ba
亚太地区GYdF4y2Ba
- 澳大利亚GYdF4y2Ba(英语)GYdF4y2Ba
- 印度GYdF4y2Ba(英语)GYdF4y2Ba
- 新西兰GYdF4y2Ba(英语)GYdF4y2Ba
- 中国GYdF4y2Ba
- 日本GYdF4y2Ba(日本語)GYdF4y2Ba
- 한국GYdF4y2Ba(한국어)GYdF4y2Ba
