perfcurve
接受者操作特征(ROC)曲线或其他分类器输出性能曲线
语法
描述
例子
绘制ROC曲线分类Logistic回归
加载示例数据。
负载fisheriris
只使用前两个特性预测变量。定义一个二分类问题,只使用对应的测量物种virginica杂色的。
pred =量(51:结束,1:2);
定义二进制响应变量。
resp = (1:10 0) ' > 50;%多色的= 0,virginica = 1
符合逻辑回归模型。
mdl = fitglm (pred职责,“分布”,“二”,“链接”,分对数的);
计算ROC曲线。使用逻辑回归模型的概率估计的分数。
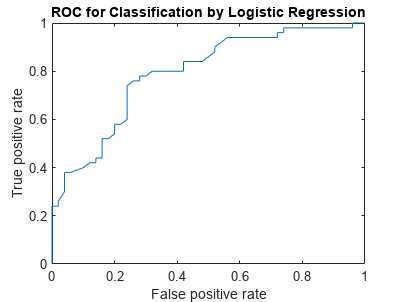
成绩= mdl.Fitted.Probability;(X, Y, T, AUC) = perfcurve(物种(51:,:),分数,“virginica”);
perfcurve存储阈值的数组T。
显示曲线下的面积。
AUC
AUC = 0.7918
曲线下的面积是0.7918。最大的AUC是1,对应于一个完美的分类器。更大的AUC值表明更好的分类性能。
绘制ROC曲线。
情节(X, Y)包含(的假阳性率)ylabel (“真阳性率”)标题(“中华民国的分类逻辑回归”)
另外,您可以通过创建一个计算和绘制ROC曲线rocmetrics对象和使用对象的功能情节。
rocObj = rocmetrics(物种(51:,:),分数,“virginica”);情节(rocObj)
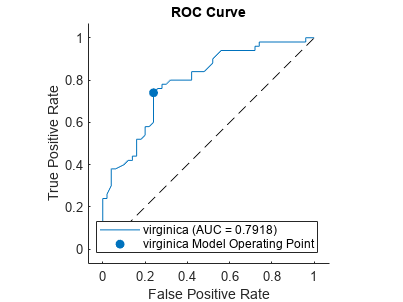
的情节函数显示一个实心圆模型操作点,传说显示类名和AUC值曲线。
比较分类方法使用ROC曲线
加载示例数据。
负载电离层
X是一个351 x34实值矩阵的预测。Y是一个字符数组的类标签:“b”坏和雷达的回报‘g’好的雷达返回。
重新格式化响应符合逻辑回归。使用3至34个预测变量。
resp = strcmp (Y,“b”);% resp = 1,如果Y = b,或0如果Y =‘g’pred = X (: 34);
符合逻辑回归模型来估计后验概率雷达回波是坏的。
mdl = fitglm (pred职责,“分布”,“二”,“链接”,分对数的);score_log = mdl.Fitted.Probability;%概率估计
计算使用概率评分标准ROC曲线。
[Xlog, Ylog Tlog AUClog] = perfcurve(职责、score_log“真正的”);
训练支持向量机分类器在相同的示例数据。标准化数据。
mdlSVM = fitcsvm (pred职责,“标准化”,真正的);
计算后验概率(分数)。
mdlSVM = fitPosterior (mdlSVM);[~,score_svm] = resubPredict (mdlSVM);
第二列的score_svm包含坏雷达的后验概率的回报。
计算标准ROC曲线使用分数从支持向量机模型。
[Xsvm, Ysvm Tsvm AUCsvm] = perfcurve(职责,score_svm (:, mdlSVM.ClassNames),“真正的”);
适合朴素贝叶斯分类器在同一样本数据。
mdlNB = fitcnb (pred、职责);
计算后验概率(分数)。
[~,score_nb] = resubPredict (mdlNB);
计算标准ROC曲线使用朴素贝叶斯分类的分数。
[Xnb, Ynb, Tnb AUCnb] = perfcurve(职责,score_nb (:, mdlNB.ClassNames),“真正的”);
绘制ROC曲线在同一图。
情节(Xlog Ylog)在情节(Xsvm Ysvm)情节(Xnb Ynb)传说(逻辑回归的,“万博1manbetx支持向量机”,“天真的贝叶斯,“位置”,“最佳”)包含(的假阳性率);ylabel (“真阳性率”);标题(ROC曲线的逻辑回归、支持向量机和朴素贝叶斯分类的)举行从
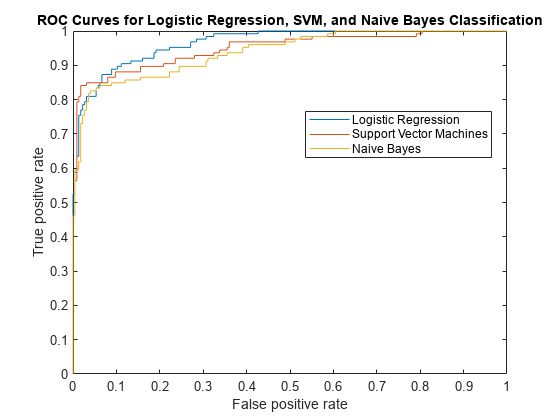
虽然支持向量机产生更好的ROC值更高的门槛,逻辑回归通常更善于区分不好雷达的回报。朴素贝叶斯的ROC曲线通常是低于其他两个ROC曲线,这表明分类性能比其他两个分类器的方法。
比较曲线下的面积为所有三个分类器。
AUClog
AUClog = 0.9659
AUCsvm
AUCsvm = 0.9489
AUCnb
AUCnb = 0.9393
逻辑回归的AUC最高测量分类和朴素贝叶斯的最低。这一结果表明,逻辑回归样本具有更好的平均性能对于此示例数据。
确定自定义内核函数的参数值
这个例子展示了如何确定更好的为一个定制的内核函数参数值分类器使用ROC曲线。
生成一个随机的在单位圆内的点的集合。
rng (1);%的再现性n = 100;%的数量分象限r1 =√兰特(2 * n, 1));%随机半径t1 =[π/ 2 *兰德(n, 1);(π/ 2 *兰德(n - 1) +π)];%随机角度Q1和Q3X1 = (r1。* cos (t1) r1。* sin (t1)];% Polar-to-Cartesian转换r2 =√兰特(2 * n, 1));t2 =[π/ 2 *兰德(n, 1) +π/ 2;(π/ 2 *兰德(n, 1) -π/ 2)];%随机角度为第二季度和第四季度X2 = [r2。* cos (t2) r2。* sin (t2)];
定义预测变量。标签在第一和第三象限属于积极的类,和那些在第二和第四象限负类。
pred = [X1;X2);resp = 1 (4 * n, 1);职责(2 * n + 1:结束)= 1;%的标签
创建函数mysigmoid.m接受两个矩阵的特征空间作为输入,并将其转化为一个格拉姆矩阵使用乙状结肠内核。
函数G = mysigmoid (U, V)% s形的内核函数斜率伽马和拦截cγ= 1;c = 1;G =双曲正切(γ*你* V ' + c);结束
一个使用乙状核函数的支持向量机分类器训练。是一种很好的做法标准化数据。
SVMModel1 = fitcsvm (pred职责,“KernelFunction”,“mysigmoid”,…“标准化”,真正的);SVMModel1 = fitPosterior (SVMModel1);[~,scores1] = resubPredict (SVMModel1);
集γ= 0.5;在mysigmoid.m和另存为mysigmoid2.m。,训练SVM分类器使用调整乙状结肠内核。
函数G = mysigmoid2 (U, V)% s形的内核函数斜率伽马和拦截cγ= 0.5;c = 1;G =双曲正切(γ*你* V ' + c);结束
SVMModel2 = fitcsvm (pred职责,“KernelFunction”,“mysigmoid2”,…“标准化”,真正的);SVMModel2 = fitPosterior (SVMModel2);[~,scores2] = resubPredict (SVMModel2);
计算ROC曲线和曲线下的面积(AUC)两种模型。
~ (x1, y1, auc1] = perfcurve(职责,scores1 (:, 2), 1);[x2, y2, ~, auc2] = perfcurve(职责,scores2 (:, 2), 1);
绘制ROC曲线。
情节(x1, y1)在情节(x2, y2)从传奇(“γ= 1”,“γ= 0.5”,“位置”,“本身”);包含(的假阳性率);ylabel (“真阳性率”);标题(中华民国的分类支持向量机的);

γ的核函数参数设置为0.5给更好的分类结果。
比较AUC的措施。
auc1 auc2
auc1 auc2 = 0.9985 = 0.9518
对伽马曲线下的面积设置为0.5高于伽马设置为1。这也证实了γ参数值0.5产生更好的结果。的视觉比较分类性能与这两个γ参数值,明白了训练SVM分类器使用自定义内核。
分类树的绘制ROC曲线
加载示例数据。
负载fisheriris
列向量,物种三个不同的种类,包括虹膜花:setosa, virginica杂色的。双矩阵量包含四种类型的测量在花:花萼长度,萼片宽,花瓣长度和花瓣宽度。所有的措施都在厘米。
训练一个分类树使用花萼长度和宽度作为预测变量。这是一个很好的练习来指定类名。
模型= fitctree(量(:,1:2),物种,…“类名”,{“setosa”,“多色的”,“virginica”});
预测类标签和分数基于树的物种模型。
[~,分数]= resubPredict(模型);
分数是一个观察的后验概率(中的一行数据矩阵)属于一个类。的列分数对应于指定的类“类名”。所以,第一列对应于setosa,第二个对应于多色的,第三列对应于virginica。
计算的预测的ROC曲线观察属于杂色的,考虑到真正的类标签物种。计算最优操作点和y值为负的子类。返回负类的名称。
因为这是一个多类问题,你不能仅仅供应(得分:2)作为输入,perfcurve。这样做不会给perfcurve足够的信息两个负类的分数(setosa和virginica)。这个问题是与二元分类问题,知道一个类的成绩足以确定其他类的分数。因此,您必须供应perfcurve与功能因素的得分两个负类。一个这样的函数是
,对应于one-versus-all编码设计。
diffscore1 =分数(:,2)- max(分数(:1),分数(:,3));
中的值diffscore分类评分为一个二进制的问题,对第二课堂作为正类,其余为负类。
[X, Y, T, ~, OPTROCPT suby, subnames] = perfcurve(物种,diffscore1,“多色的”);
X默认情况下,假阳性率(影响或1-specificity)Y默认情况下,是真正的积极率(召回或敏感性)。积极的类标签多色的。因为消极的类没有定义,perfcurve假设观察,不属于积极的类是一个类。函数接受它作为负类。
OPTROCPT
OPTROCPT =1×20.1000 - 0.8000
suby
suby =12×20 0 0.1800 0.1800 0.4800 0.4800 0.5800 0.5800 0.6200 0.6200 0.8000 0.8000 0.8800 0.8800 0.9200 0.9200 0.9600 0.9600 0.9800 0.9800⋮
subnames
subnames =1 x2单元格{' setosa} {' virginica '}
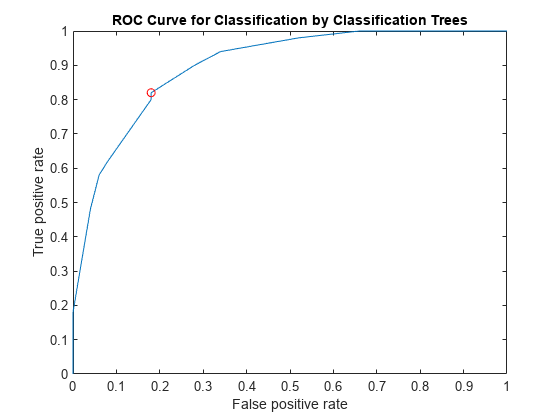
绘制ROC曲线和最优操作点ROC曲线。
情节(X, Y)在情节(OPTROCPT (1) OPTROCPT (2),“罗”)包含(的假阳性率)ylabel (“真阳性率”)标题(“ROC曲线分类的分类树”)举行从
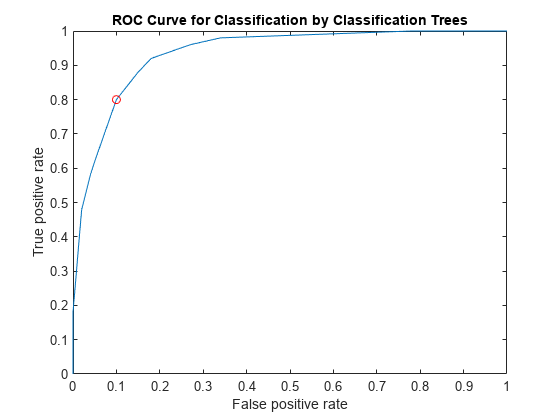
找到对应的阈值的最优操作点。
T ((X = = OPTROCPT (1) & (Y = = OPTROCPT (2)))
ans = 0.2857
指定virginica负类,计算和绘制ROC曲线多色的。
同样的,你必须提供perfcurve与功能因素分数负类的。使用一个函数的一个例子
。
diffscore2 =分数(:,2)——分数(:,3);[X, Y, ~, ~, OPTROCPT] = perfcurve(物种,diffscore2,“多色的”,…“negClass”,“virginica”);OPTROCPT
OPTROCPT =1×20.1800 - 0.8200
人物,情节(X, Y)在情节(OPTROCPT (1) OPTROCPT (2),“罗”)包含(的假阳性率)ylabel (“真阳性率”)标题(“ROC曲线分类的分类树”)举行从
或者,您可以使用一个rocmetrics对象创建ROC曲线。rocmetrics万博1manbetx使用one-versus-all编码设计,支持多类分类问题,减少了多类问题为一组二元问题。您可以检查性能的多级问题每个类为每个类策划one-versus-all ROC曲线。
计算性能指标通过创建一个rocmetrics对象。指定正确的标签,分类分数,和类名。
rocObj = rocmetrics(物种,分数,Model.ClassNames);
情节为每个类通过使用ROC曲线情节的函数rocmetrics。
图绘制(rocObj)
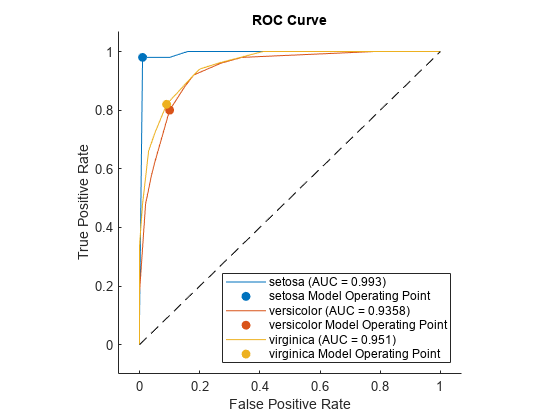
的情节函数显示一个实心圆模型操作点的每个类,和传说显示类名和AUC值曲线。你可以找到最优操作点通过使用存储在属性rocmetrics对象rocObj。例如,看到的找到模型的操作点和最优操作点。
ROC曲线计算逐点的置信区间
加载示例数据。
负载fisheriris
列向量物种包含三个不同物种的虹膜花:setosa, virginica杂色的。双矩阵量包含四种类型的测量在花:花萼长度,萼片宽,花瓣长度和花瓣宽度。所有的措施都在厘米。
只使用前两个特性预测变量。定义一个二元问题,只使用对应的测量多色的和virginica物种。
pred =量(51:结束,1:2);
定义二进制响应变量。
resp = (1:10 0) ' > 50;%多色的= 0,virginica = 1
符合逻辑回归模型。
mdl = fitglm (pred职责,“分布”,“二”,“链接”,分对数的);
计算真阳性率上的点态置信区间(TPR)垂直平均使用引导(VA)和抽样。
[X, Y, T] = perfcurve(物种(51:,:),mdl.Fitted.Probability,…“virginica”,“NBoot”,1000,“XVals”[0:0.05:1]);
“NBoot”, 1000年引导复制的数量设置为1000。“XVals”、“所有”提示perfcurve返回X,Y,T所有分数值,平均的Y值(真阳性)X使用垂直平均值(假阳性)。如果你不指定XVals,然后perfcurve使用默认阈值平均计算置信界限。
绘制点态置信区间。
errorbar (X, Y (: 1), Y (: 1) - Y (:, 2), Y (:, 3) - Y (: 1));xlim ([-0.02, 1.02]);ylim ([-0.02, 1.02]);包含(的假阳性率)ylabel (“真阳性率”)标题(“ROC曲线与逐点的置信界限”)传说(“PCBwVA”,“位置”,“最佳”)
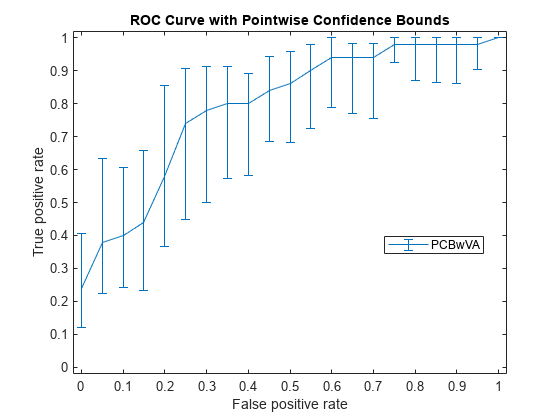
它可能并不总是可能的控制(玻璃钢,假阳性X值在这个例子)。所以你可能会想真阳性利率计算点态置信区间(TPR)阈值平均。
(X1, Y1, T1) = perfcurve(物种(51:,:),mdl.Fitted.Probability,…“virginica”,“NBoot”,1000);
如果你设置“TVals”来“所有”如果你不指定,或“TVals”或“Xvals”,然后perfcurve返回X,Y,T所有分数和计算点态置信界限值X和Y使用阈值平均。
情节的信心。
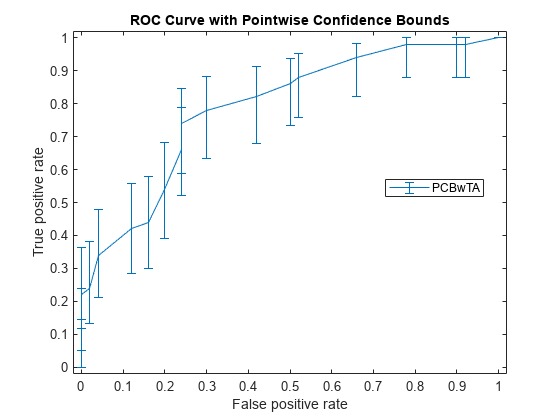
图()errorbar (X1 (: 1), Y1(: 1),日元(:1)日元(:,2),日元(:,3)日元(:1));xlim ([-0.02, 1.02]);ylim ([-0.02, 1.02]);包含(的假阳性率)ylabel (“真阳性率”)标题(“ROC曲线与逐点的置信界限”)传说(“PCBwTA”,“位置”,“最佳”)
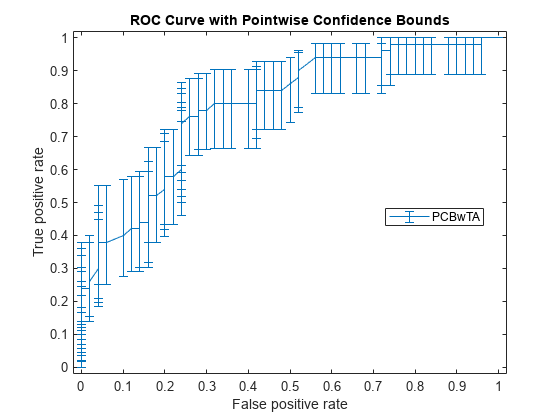
指定阈值来修正和计算ROC曲线。然后绘制曲线。
(X1, Y1, T1) = perfcurve(物种(51:,:),mdl.Fitted.Probability,…“virginica”,“NBoot”,1000,“TVals”,0:0.05:1);图()errorbar (X1 (: 1), Y1(: 1),日元(:1)日元(:,2),日元(:,3)日元(:1));xlim ([-0.02, 1.02]);ylim ([-0.02, 1.02]);包含(的假阳性率)ylabel (“真阳性率”)标题(“ROC曲线与逐点的置信界限”)传说(“PCBwTA”,“位置”,“最佳”)
输入参数
输出参数
算法
选择功能
你可以计算ROC曲线的性能指标和其他性能曲线通过创建一个
rocmetrics对象。rocmetrics万博1manbetx同时支持二进制和多类分类问题。你可以通过分类分数返回的预测函数的分类模型对象(如预测的ClassificationTree)rocmetrics没有调整分数的多级模型。rocmetrics提供了对象函数绘制ROC曲线(情节),发现平均ROC曲线多类问题(平均),并计算额外的指标在创建一个对象(addMetrics)。更多细节,请参见页面和参考ROC曲线和性能指标。