规范判别分析分类器
这个例子展示了如何做一个更健壮和简单的模型试图消除预测没有伤害模型的预测能力。这是特别重要的,当你有很多预测数据。线性判别分析使用两个正则化参数,γ和δ,识别和消除冗余预测。的cvshrink方法帮助确定适当的设置这些参数。
加载数据并创建一个分类器。
创建一个线性判别分析分类器ovariancancer数据。设置SaveMemory和FillCoeffs名称-值对参数保持生成的模型相当小。为计算方便,这个示例使用一个随机的子集大约三分之一的预测训练分类器。
负载ovariancancerrng (1);%的再现性numPred =大小(奥林匹克广播服务公司,2);奥林匹克广播服务公司=突发交换(:,randsample (numPred装天花板(numPred / 3)));grp Mdl = fitcdiscr(奥林匹克广播服务公司,“SaveMemory”,“上”,“FillCoeffs”,“关闭”);
交叉验证分类器。
用25的水平γ和25δ寻找好的参数。这个搜索耗时。集详细的来1查看进度。
(呃,γδ,numpred) = cvshrink (Mdl,…“NumGamma”,24岁,“NumDelta”,24岁,“详细”1);
构建旨在模型完成。处理25伽马步骤1。步骤2处理伽马25。处理25伽马步骤3。处理25伽马步骤4。处理25伽马步骤5。处理25伽马步骤6。处理25伽马步骤7。处理25伽马步骤8。处理25伽马第9步。 Processing Gamma step 10 out of 25. Processing Gamma step 11 out of 25. Processing Gamma step 12 out of 25. Processing Gamma step 13 out of 25. Processing Gamma step 14 out of 25. Processing Gamma step 15 out of 25. Processing Gamma step 16 out of 25. Processing Gamma step 17 out of 25. Processing Gamma step 18 out of 25. Processing Gamma step 19 out of 25. Processing Gamma step 20 out of 25. Processing Gamma step 21 out of 25. Processing Gamma step 22 out of 25. Processing Gamma step 23 out of 25. Processing Gamma step 24 out of 25. Processing Gamma step 25 out of 25.
检查正规化的质量分类器。
情节的数量预测误差。
情节(呃,numpred“k”。)包含(的错误率)ylabel (预测的数量)
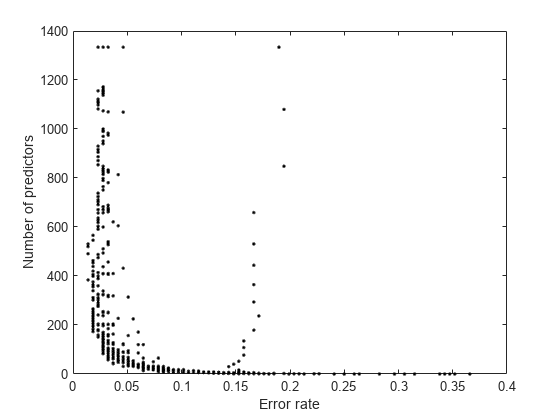
更仔细地检查的左下部分情节。
轴([0。1 0 1000])
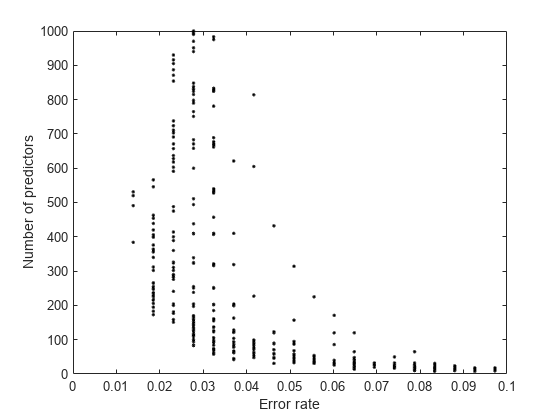
有明显的低数量的预测因子之间的权衡和更低的错误。
选择一个最优的权衡模型的大小和精度。
多个双γ和δ产生相同的最小误差值。显示的指标对和它们的值。
首先,找到最小误差值。
minerr = min (min (err))
minerr = 0.0139
找到的下标犯错生产误差最小。
(p, q) =找到(犯错< minerr + 1的军医);
从下标转换为线性指标。
idx = sub2ind(大小(δ),p, q);
显示γ和δ值。
(γδ(idx) (p))
ans =4×20.7202 0.1145 0.7602 0.1131 0.8001 0.1128 0.8001 0.1410
这些点只有总数的29%与非零系数预测模型。
numpred (idx) /装天花板(numpred / 3) * 100
ans =4×139.8051 38.9805 36.8066 28.7856
为了进一步降低预测的数量,你必须接受更大的错误率。例如,选择γ和δ给的错误率最低200或更少的预测因子。
low200 = min (min(犯错(numpred < = 200)));lownum = min (min (numpred(呃= = low200)));[low200 lownum]
ans =1×20.0185 - 173.0000
你需要有173个预测因子达到0.0185的出错率,这是最低的错误率在那些200预测或更少。
显示γ和δ实现这一错误/数量的预测。
(r, s) =找到((呃= = low200) & (numpred = = lownum));(γ(r);δ(r, s)]
ans =2×10.6403 - 0.2399
设置正则化参数。
设置这些值的分类器γ和δ,使用点符号。
Mdl。γ=γ(r);Mdl。δ=δ(r, s);
热图情节
比较cvshrink计算在郭,Hastie, Tibshirani[1]、情节的热图误差和预测对的数量γ和的索引δ参数。(δ参数范围取决于的价值γ参数。所以一个矩形图,使用δ指数,而不是参数本身。)
%创建一个增量索引矩阵indx = repmat(1:大小(δ2),大小(三角洲,1),1);图次要情节(1、2、1)显示亮度图像(err) colorbar colormap (“喷气机”)标题(分类错误的)包含(“三角洲指数”)ylabel (“伽马指数”次要情节(1、2、2)显示亮度图像(numpred) colorbar标题(模型的预测数量的)包含(“三角洲指数”)ylabel (“伽马指数”)
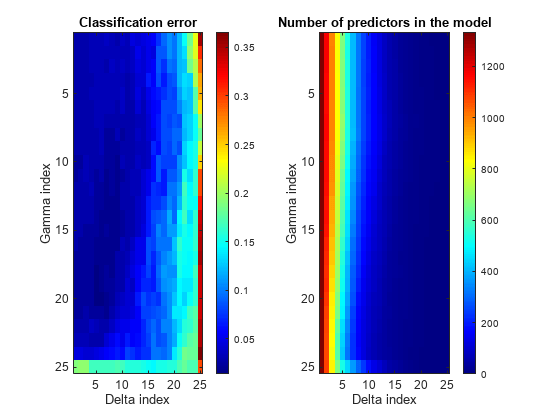
当你看到最好的分类错误δ很小,但最少的预测什么时候δ很大。
引用
[1]郭,Y。,T. Hastie, and R. Tibshirani. "Regularized Discriminant Analysis and Its Application in Microarray."生物统计学,8卷,1号,第100 - 86页,2007年。