选择LDA模型的主题数量
这个例子展示了如何为一个潜在的Dirichlet分配(LDA)模型确定合适的主题数量。
要决定合适数量的主题,您可以比较LDA模型的高度适合符合不同数量的主题。您可以通过计算一组文件集的困惑来评估LDA模型的健康。困惑表明模型描述了一组文档的程度。较低的困惑表明更适合。
提取和预处理文本数据
加载示例数据。文件factoryreports.csv.包含工厂报告,包括每个事件的文本描述和分类标签。从字段中提取文本数据描述。
filename =.“factoryReports.csv”;数据= readtable(文件名,'texttype'那'串');textData = data.Description;
使用该功能授权和预处理文本数据preprocessText它列在本示例的最后。
文件= preprocessText (textData);文档(1:5)
ans = 5×1令牌Document:6个代币:物品偶尔得到扫描仪卷轴7令牌:响亮的拨浪鼓响起来了瓶子活塞4令牌:切割电源启动工厂3令牌:Fry电容器组件3令牌:搅拌机跳闸保险丝
随机预留10%的文件以进行验证。
numDocuments =元素个数(文件);本量利= cvpartition (numDocuments,'坚持',0.1);documentstrain =文档(cvp.train);documentsvalidation =文档(cvp.test);
从训练文档创建单词袋模型。删除总共出现次数不超过两次的单词。删除任何不包含单词的文档。
bag = bagofwords(DocumentStrain);袋= removeinfreqwinds(袋子,2);BAG = RoverimementyDocuments(袋);
选择主题数量
目标是选择许多主题,与其他主题相比,最小化困惑。这不是唯一的考虑因素:模型适合大量主题可能需要更长的时间来收敛。要查看权衡的影响,请计算适合的身高和配件时间。如果最佳主题数很高,那么您可能希望选择较低的值以加快拟合过程。
适用于某种值的LDA模型,以获得主题次数。比较每个模型对所持式测试文档集的拟合时间和困惑。困惑是第二个输出logp函数。要获得第二个输出而不将第一个输出赋值给任何对象,请使用〜符号。配件时间是TimesIncestart.最后迭代的价值。这个值是在的历史结构的结构FitInfo.LDA模型属性。
为了更快的合身,请指定“规划求解”成为“savb”。要抑制详细输出,请设置“详细”至0.。这可能需要几分钟的时间来运行。
numTopicsRange = [5 10 15 20 40];对于numTopicsRange = 1: numTopics = numTopicsRange(i);mdl = fitlda(袋、numTopics、......“规划求解”那“savb”那......“详细”,0);[〜,ValidationPerplexity(i)] = logp(mdl,documentValidation);TimeLapsed(i)= mdl.fitinfo.history.timesIncestart(END);结束
为绘图中的每个主题显示困惑和经过的时间。绘制左轴上的困惑,右轴上经过的时间。
图yyaxis剩下绘图(NumtopicsRange,ValidationPerplearity,“+ -”) ylabel (“验证困惑”) yyaxis对绘图(NumtopicsRange,TimeLapsed,'O-') ylabel (“时间运行(s)”)传说([“验证困惑”“时间运行(s)”),“位置”那“东南”)包含(“主题”)
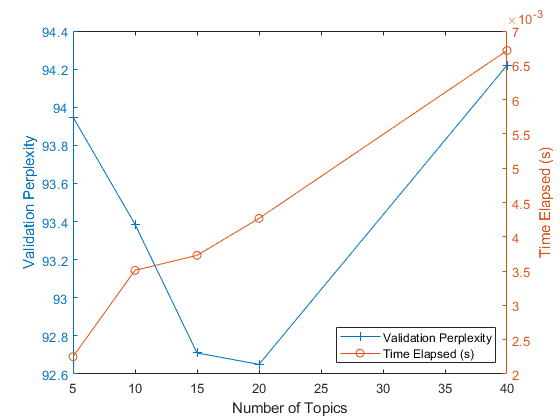
绘图表明,用10-20个主题拟合模型可能是一个不错的选择。与具有不同主题数量不同的模型相比,困惑低。通过这个解决者,这么多主题的经过时间也是合理的。通过不同的求解器,您可能会发现增加主题的数量可能导致更好的合适,但拟合模型需要更长的时间来收敛。
例子预处理功能
这个函数preprocessText,按顺序执行以下步骤:
将文本数据转换为小写使用
较低的。使用授权文本
tokenizedDocument。删除标点符号使用
erasePunctuation。删除使用的停止单词列表(例如“和”,“和”和“该”)的列表
removeStopWords。使用2或更少的字符删除单词
removeShortWords。使用15个或更多字符删除单词
removelongwords.。对用词进行归纳
正常化字。
函数文件= preprocessText (textData)%将文本数据转换为小写。cleanTextData =低(textData);%标记文本。文档= tokenizeddocument(cleantextdata);%擦掉标点符号。= erasePunctuation文件(文档);%删除停止单词列表。文档= Removestopwords(文件);%删除字符数小于或等于2的单词和大于或等于15的单词%字符。文件= removeShortWords(文件,2);= removeLongWords文档(文档、15);%lemmatize单词。= addPartOfSpeechDetails文件(文档);文档= normalizeWords(文档,'风格'那'引理');结束
也可以看看
addPartOfSpeechDetails|Bagofwords.|Bagofwords.|erasePunctuation|菲达|Ldamodel.|logp|正常化字|删除程序|removeinfrequentwords.|removelongwords.|removeShortWords|removeStopWords|tokenizedDocument
相关的话题
您也可以从以下列表中选择一个网站:
