置信度和预测界限
关于信心和预测界限
曲线拟合工具箱™软件可以计算拟合系数的置信边界,以及新观测值或拟合函数的预测边界。此外,对于预测边界,可以计算同时边界(考虑所有预测器值),也可以计算非同时边界(只考虑单个预测器值)。系数置信边界以数字形式表示,而预测边界则以图形形式显示,也可以用数字形式表示。
可用置信度和预测界限总结如下。
置信度和预测界限的类型
间隔类型 |
描述 |
|---|---|
拟合系数 |
拟合系数的置信界限 |
新观察 |
新观测值(响应值)的预测边界 |
新功能 |
新函数值的预测边界 |
请注意
预测边界也经常被描述为置信边界,因为您正在计算预测响应的置信区间。
置信度和预测界定义了相关区间的上下限,并定义了区间的宽度。区间的宽度表明你对拟合系数、预测观察结果或预测拟合的不确定程度。例如,拟合系数的间隔非常大,这表明在拟合时应该使用更多的数据,然后才能非常明确地说出关于系数的任何东西。
边界的定义具有您指定的确定性级别。确定性的级别通常是95%,但它可以是任何值,如90%、99%、99.9%,等等。例如,在预测一个新的观察结果时,你可能想要承担5%的错误几率。因此,您将计算95%的预测区间。这个区间表明,您有95%的机会,新的观察结果实际上包含在下限和上限预测边界内。
系数的置信界限
拟合系数的置信限为
在哪里b是由拟合产生的系数,t依赖于置信度水平,并使用Student的倒数计算t累积分布函数,和年代是来自系数估计的协方差矩阵的对角元素的向量,(XTX)1年代2.在线性拟合中,X是设计矩阵,而为非线性拟合X是拟合值对系数的雅可比矩阵。XT是的转置X,年代2是均方误差。
置信界限显示在结果面板中的曲线拟合器应用程序使用以下格式。
P1 = 1.275 (1.113, 1.437)
系数的拟合值p1为1.275,下界为1.113,上界为1.437,区间宽度为0.324。默认情况下,边界的置信度为95%。
方法可以在命令行上计算置信区间confint函数。
拟合预测边界
如前所述,可以计算拟合曲线的预测边界。预测是基于现有的数据拟合。此外,这些边界可以是同时的并测量所有预测值的置信度,也可以是非同时的并仅测量单个预定预测值的置信度。如果要预测一个新的观察结果,则非同时界度量新观察结果位于给定单个预测值的区间内的置信度。同时界度量新观测值位于区间内的置信度,而不考虑预测值。
| 绑定类型 | 观察 | 功能 |
|---|---|---|
| 同时 |
|
|
| 异时 |
|
|
地点:
年代2是均方误差吗
t依赖于置信度水平,并使用Student的倒数计算t累积分布函数
f取决于置信水平,并使用的倒数计算F累积分布函数。
年代为系数估计的协方差矩阵,(XTX)1年代2.
x是设计矩阵或雅可比矩阵在指定预测值处的行向量。
您可以使用曲线Fitter应用程序图形化地显示预测边界。在曲线Fitter应用程序中,您可以显示新观测的非同时预测边界。在曲线更健康选项卡,可视化节中,选择一个确定的级别预测范围列表。您可以通过选择将此级别更改为任何值自定义从列表中。
控件可以在命令行上显示任何类型的数值预测边界predint函数。
要理解与每种类型的预测区间相关的数量,回想一下数据、拟合和残差是通过公式联系起来的
数据=适合+残差
其中拟合项和残差项是公式中项的估计值
数据=模型+随机误差
假设您计划在预测值处进行新的观察xn+1.称之为新的观察结果yn+1(xn+1)和相关的错误εn+1.然后
yn+1(xn+1) =f(xn+1) +εn+1
在哪里f(xn+1)是你想估计的真实但未知的函数xn+1.新观测值或估计函数的可能值由非同时预测界提供。
相反,如果你想让新观察值的可能值与任何预测值相关联,前面的方程就变成
yn+1(x) =f(x) +ε
这个新的观察值或估计函数的可能值由同时预测界提供。
预测边界的类型总结如下。
预测界限的类型
类型的绑定 |
同时或异时 |
相关的方程 |
|---|---|---|
观察 |
异时 |
yn+1(xn+1) |
同时 |
yn+1(x),为所有x |
|
函数 |
异时 |
f(xn+1) |
同时 |
f(x),为所有x |
一个新的观测值和拟合函数的非同时和同时预测边界如下所示。每个图包含三条曲线:拟合曲线、置信下限曲线和置信上限曲线。拟合是生成的数据的单项指数,其边界反映了95%的置信水平。注意,与新观测值相关的区间要比拟合函数区间宽,这是因为在预测新响应值时存在额外的不确定性(曲线加上随机误差)。
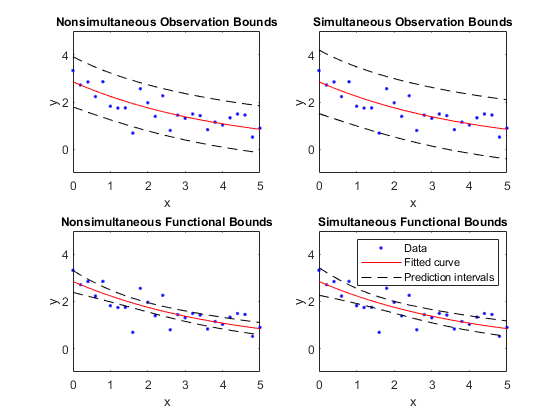
计算预测区间
计算并绘制观测和函数预测区间,以拟合噪声数据。
生成具有指数趋势的噪声数据。
x =(0:0.2:5)”;Y = 2*exp(-0.2*x) + 0.5*randn(size(x));
用单项指数拟合数据曲线。
fitresult =适合(x, y,“exp1”);
计算95%的观测和功能预测区间,同时和非同时。非同时边界适用于x的单个元素;同时边界适用于x的所有元素。
侯= predint (fitresult x 0.95,“观察”,“关闭”);p12 = predint (fitresult x 0.95,“观察”,“上”);p21 = predint (fitresult x 0.95,“功能”,“关闭”);第22位= predint (fitresult x 0.95,“功能”,“上”);
绘制数据、拟合和预测间隔。观测界比函数界宽,因为它们衡量的是预测拟合曲线的不确定性加上新观测的随机变化。
次要情节(2、2、1)情节(fitresult, x, y)在、情节(x,侯,“m——”), xlim([0 5]), ylim([-1 5]) title(“异时观测范围”,“字形大小”9)传奇从次要情节(2 2 2)情节(fitresult, x, y)在、情节(x, p12,“m——”), xlim([0 5]), ylim([-1 5]) title(“同步观测范围”,“字形大小”9)传奇从次要情节(2,2,3)情节(fitresult, x, y)在p21、情节(x,,“m——”), xlim([0 5]), ylim([-1 5]) title(“异时功能范围”,“字形大小”9)传奇从次要情节(2,2,4)情节(fitresult, x, y)在、情节(x,第22位,“m——”), xlim([0 5]), ylim([-1 5]) title(“同步功能范围”,“字形大小”9)传奇({“数据”,的拟合曲线,预测区间的},...“字形大小”8“位置”,“东北”)
您也可以从以下列表中选择网站: