基于深度学习的时间序列预测
这个例子展示了如何使用长短期记忆(LSTM)网络预测时间序列数据。
为了预测序列未来时间步长的值,可以训练一个序列到序列回归LSTM网络,其中的响应是值移动一个时间步长的训练序列。即在输入序列的每一个时间步长,LSTM网络学习预测下一个时间步长的值。
要预测未来多个时间步的值,请使用预测和更新房地产函数一次预测一个时间步,并在每次预测时更新网络状态。
本例使用数据集chickenpox_dataset。该示例训练LSTM网络,根据前几个月的水痘病例数预测水痘病例数。
加载序列数据
加载示例数据。chickenpox_dataset包含单个时间序列,时间步长对应于月份,值对应于案例数。输出为单元格数组,其中每个元素为单个时间步长。将数据重塑为行向量。
数据=水痘数据集;数据=[数据{:}];图形绘图(数据)xlabel(“月”) ylabel (“案例”)标题(“每月水痘病例”)

对培训和测试数据进行分区。在序列的前90%进行训练,在最后10%进行测试。
地板numTimeStepsTrain =(0.9 *元素个数(数据);dataTrain =数据(1:numTimeStepsTrain + 1);人数(=数据(numTimeStepsTrain + 1:结束);
标准化数据
为了更好地拟合并防止训练发散,将训练数据标准化为零均值和单位方差。在预测时,必须使用与训练数据相同的参数标准化测试数据。
μ=意味着(dataTrain);sig =性病(dataTrain);datatrain标准化= (datatrainmu) / sig;
准备预测因素和反应
要预测序列未来时间步的值,请将响应指定为值移动一个时间步的训练序列。也就是说,在输入序列的每个时间步,LSTM网络学习预测下一个时间步的值。预测器是没有最终时间步的训练序列。
XTrain = dataTrainStandardized (1: end-1);YTrain = dataTrainStandardized(2:结束);
定义LSTM网络体系结构
创建一个LSTM回归网络。指定LSTM层有200个隐藏单元。
numFeatures=1;numResponses=1;numHiddenUnits=200;图层=[...sequenceInputLayer(numFeatures)lstmLayer(numHiddenUnits)fullyConnectedLayer(numResponses)regressionLayer];
指定训练选项。将解算器设置为“亚当”训练250个时代。为了防止渐变发生爆炸,设置渐变阈值为1。指定初始学习率为0.005,并将125个纪元后的学习率乘以0.2。
选择= trainingOptions (“亚当”,...“MaxEpochs”, 250,...“GradientThreshold”,1,...“初始学习率”,0.005,...“LearnRateSchedule”,“分段”,...“LearnRateDropPeriod”,125,...“LearnRateDropFactor”,0.2,...“详细”0,...“情节”,“培训进度”);
列车LSTM网络
使用指定的培训选项培训LSTM网络列车网络.
网= trainNetwork (XTrain、YTrain层,选择);

预测未来的时间步长
要预测未来多个时间步的值,请使用预测和更新房地产函数一次预测一个时间步长,并在每次预测时更新网络状态。对于每次预测,使用以前的预测作为函数的输入。
使用与培训数据相同的参数标准化测试数据。
dataTestStandardized=(dataTest-mu)/sig;XTest=dataTestStandardized(1:end-1);
要初始化网络状态,首先对训练数据进行预测XTrain.接下来,使用训练反应的最后一个时间步骤进行第一次预测YTrain(结束).循环剩余的预测并输入之前的预测预测和更新房地产.
对于大型数据集合、长序列或大型网络,GPU上的预测计算速度通常快于CPU上的预测。否则,CPU上的预测计算速度通常更快。对于单时间步预测,使用CPU。要使用CPU进行预测,请设置“执行环境”选择预测和更新房地产到“cpu”.
网= predictAndUpdateState(净,XTrain);[净,YPred] = predictAndUpdateState(净,YTrain(结束));numTimeStepsTest =元素个数(XTest);对于i = 2:numTimeStepsTest [net,YPred(:,i)] = predictAndUpdateState(net,YPred(:,i)),“执行环境”,“cpu”);终止
使用前面计算的参数使预测不标准化。
YPred = sig*YPred + mu;
训练进度图报告从标准化数据计算的均方根误差(RMSE)。从非标准化预测计算RMSE。
YTest=数据测试(2:结束);rmse=sqrt(平均值((YPED YTest)。^2))
rmse=仅有一个的248.5531
用预测值绘制训练时间序列。
图绘制(dataTrain (1: end-1))在idx = numTimeStepsTrain:(numTimeStepsTrain + numTimeStepsTest);情节(idx (numTimeStepsTrain) YPred][数据,'.-')举行从包含(“月”) ylabel (“案例”)标题(“预测”)传说([“观察到”“预测”])

将预测值与试验数据进行比较。
figure subplot(2,1,1) plot(YTest) hold在地块(YPred,'.-')举行从传奇([“观察到”“预测”])伊拉贝尔(“案例”)标题(“预测”)子地块(2,1,2)茎(YPred-YTest)xlabel(“月”) ylabel (“错误”)标题(" RMSE = "+rmse)

使用观察到的值更新网络状态
如果您可以访问预测之间的实际时间步长的值,那么您可以使用观测值而不是预测值更新网络状态。
首先,初始化网络状态。要对新序列进行预测,请使用resetState.重置网络状态可以防止先前的预测影响对新数据的预测。重置网络状态,然后通过对训练数据的预测来初始化网络状态。
网= resetState(净);网= predictAndUpdateState(净,XTrain);
预测每个时间步。对于每个预测,使用前一时间步的观测值预测下一时间步。设定“执行环境”选择预测和更新房地产到“cpu”.
YPred = [];numTimeStepsTest =元素个数(XTest);对于i = 1:numTimeStepsTest [net,YPred(:,i)] = predictAndUpdateState(net,XTest(:,i)),“执行环境”,“cpu”);终止
使用前面计算的参数使预测不标准化。
YPred = sig*YPred + mu;
计算均方根误差(RMSE)。
rmse=sqrt(平均值((YPred y试验)。^2))
rmse = 158.0959
将预测值与试验数据进行比较。
figure subplot(2,1,1) plot(YTest) hold在地块(YPred,'.-')举行从传奇([“观察到”“预测”])伊拉贝尔(“案例”)标题(“与更新预测”)子地块(2,1,2)茎(YPred-YTest)xlabel(“月”) ylabel (“错误”)标题(" RMSE = "+rmse)
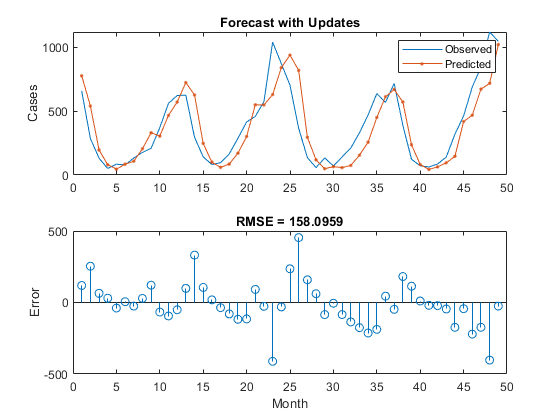
在这里,当用观测值而不是预测值更新网络状态时,预测会更准确。
另见
lstmLayer|序列输入层|trainingOptions|列车网络
相关的话题
你也可以从以下列表中选择一个网站:
