sequenceInputlayer.
序列输入层
描述
序列输入层将序列数据输入到网络。
创建
属性
例子
创建序列输入层
创建一个序列输入层的名称“seq1”和输入大小为12。
层= sequenceInputLayer (12,“名字”,“seq1”)
layer = SequenceInputLayer with properties: Name: 'seq1' InputSize: 12 Hyperparameters Normalization: 'none' NormalizationDimension: 'auto'
控件中包含序列输入层层数组中。
inputSize = 12;numHiddenUnits = 100;numClasses = 9;层= [...sequenceInputLayer inputSize lstmLayer (numHiddenUnits,“OutputMode”,“最后一次”)软连接层(numClasses)
Layer = 5x1 Layer array with layers: 1 " Sequence Input Sequence Input with 12 dimensions 2 " LSTM LSTM with 100 hidden units 3 " Fully Connected 9 Fully Connected Layer 4 " Softmax Softmax 5 " Classification Output crossentropyex . LSTM与100个隐藏单元
为图像序列创建序列输入层
创建一个序列输入层的序列224-224 RGB图像的名称“seq1”.
layer = sequenceInputLayer([224 224 3],“名字”,“seq1”)
tillay = sequenceInputLayer具有属性:名称:'SEQ1'输入:[224 224 3] radipameters标准化:'无'标准化dimension:'auto'
序列分类训练网络
培训深度学习LSTM网络,用于序列到标签分类。
如[1]和[2]中所述加载日语元音数据集。XTrain是含有270个变化长度序列的细胞阵列,其具有对应于LPC综合系数的12个特征。Y是标签1,2,…,9的分类向量。的条目XTrain矩阵有12行(每个特征一行)和不同数量的列(每个时间步骤一列)。
[XTrain, YTrain] = japaneseVowelsTrainData;
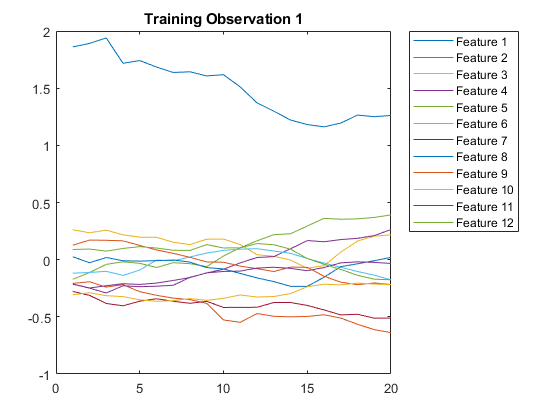
想象情节中的第一个时间序列。每一行对应一个特征。
图绘制(XTrain{1}”)标题(“训练观察1”)numfeatures = size(xtrain {1},1);传奇(“特性”+字符串(1:numFeatures),'地点',“northeastoutside”)
定义LSTM网络架构。指定输入大小为12(输入数据的特征数量)。指定一个LSTM层有100个隐藏单元,并输出序列的最后一个元素。最后,通过包含大小为9的完全连接层、softmax层和分类层来指定9个类。
inputSize = 12;numHiddenUnits = 100;numClasses = 9;层= [...sequenceInputLayer inputSize lstmLayer (numHiddenUnits,“OutputMode”,“最后一次”)软连接层(numClasses)
Layer = 5×1 Layer array with layers: 1 " Sequence Input Sequence Input with 12 dimensions 2 " LSTM LSTM with 100 hidden units 3 " Fully Connected 9 Fully Connected Layer 4 " Softmax Softmax 5 " Classification Output crossentropyex . jpg
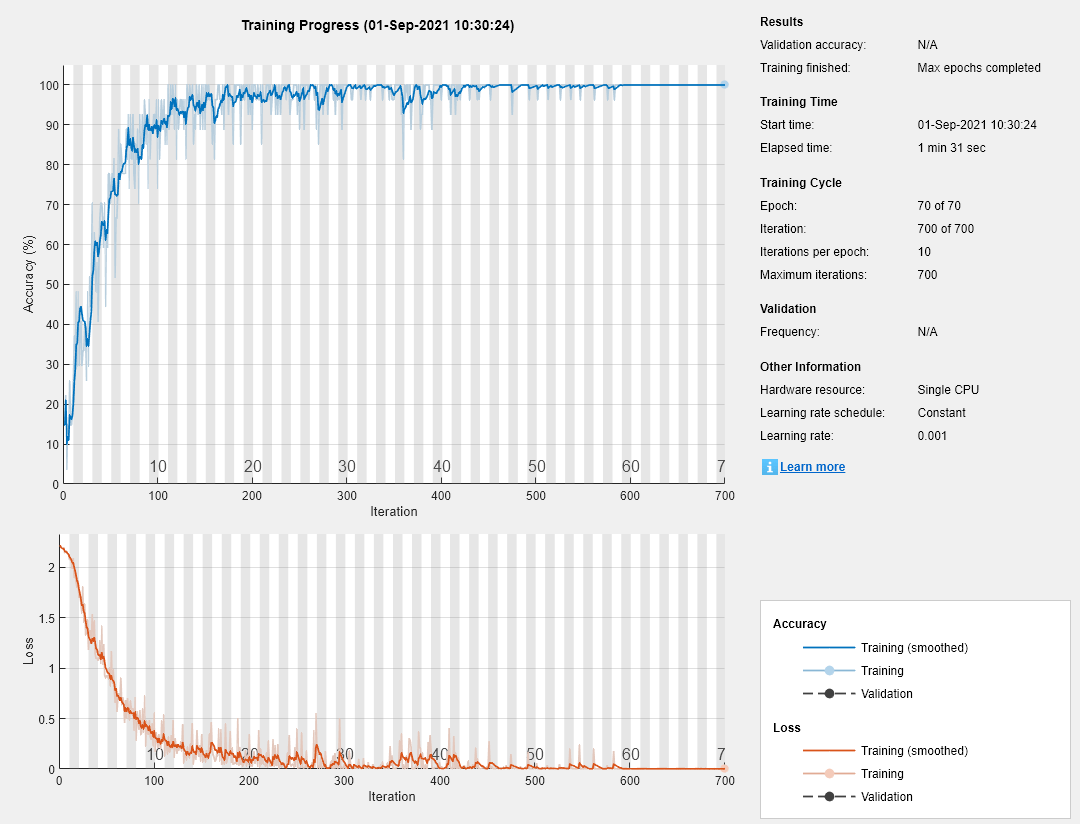
指定培训选项。指定求解器为“亚当”和“GradientThreshold”为1。设置mini-batch size为27,最大epoch数为70。
因为迷你批很小,序列很短,所以CPU更适合于训练。集“ExecutionEnvironment”来“cpu”.如果需要在GPU上进行训练,请设置“ExecutionEnvironment”来“汽车”(默认值)。
maxEpochs = 70;miniBatchSize = 27个;选择= trainingOptions (“亚当”,...“ExecutionEnvironment”,“cpu”,...'maxepochs',maxepochs,...“MiniBatchSize”miniBatchSize,...“GradientThreshold”, 1...“详细”,错误的,...“阴谋”,“训练进步”);
使用指定的训练选项训练LSTM网络。
网= trainNetwork (XTrain、YTrain层,选择);
加载测试集并将序列分类为扬声器。
[XTest,欧美]= japaneseVowelsTestData;
分类测试数据。指定用于培训的相同百分比大小。
XTest YPred =分类(净,“MiniBatchSize”, miniBatchSize);
计算预测的分类精度。
acc = sum(YPred == YTest)./numel(YTest)
acc = 0.9514
分类LSTM网络
为了创建一个LSTM网络进行序列到标签的分类,需要创建一个包含序列输入层、LSTM层、全连接层、softmax层和分类输出层的层数组。
将序列输入层的大小设置为输入数据的特征数量。将完全连接层的大小设置为类的数量。您不需要指定序列长度。
对于LSTM层,指定隐藏单元的数量和输出模式“最后一次”.
numFeatures = 12;numHiddenUnits = 100;numClasses = 9;层= [...sequenceInputLayer numFeatures lstmLayer (numHiddenUnits,“OutputMode”,“最后一次”) fulllyconnectedlayer (numClasses) softmaxLayer classificationLayer;
有关如何培训LSTM网络以获取序列到标签分类和分类新数据的示例,请参阅使用深度学习序列分类.
要创建用于序列到序列分类的LSTM网络,请使用与序列到标签分类相同的架构,但设置LSTM层的输出模式为“序列”.
numFeatures = 12;numHiddenUnits = 100;numClasses = 9;层= [...sequenceInputLayer numFeatures lstmLayer (numHiddenUnits,“OutputMode”,“序列”) fulllyconnectedlayer (numClasses) softmaxLayer classificationLayer;
回归LSTM网络
要创建序列到一回归的LSTM网络,需要创建一个包含序列输入层、LSTM层、全连接层和回归输出层的层阵列。
将序列输入层的大小设置为输入数据的特征数量。将完全连接层的大小设置为响应的数量。您不需要指定序列长度。
对于LSTM层,指定隐藏单元的数量和输出模式“最后一次”.
numFeatures = 12;numhidendunits = 125;numreponses = 1;层= [...sequenceInputLayer numFeatures lstmLayer (numHiddenUnits,“OutputMode”,“最后一次”)全连接列(NumResponses)回归范围];
要创建序列到序列回归的LSTM网络,使用与序列到一回归相同的架构,但设置LSTM层的输出模式为“序列”.
numFeatures = 12;numhidendunits = 125;numreponses = 1;层= [...sequenceInputLayer numFeatures lstmLayer (numHiddenUnits,“OutputMode”,“序列”)全连接列(NumResponses)回归范围];
有关如何训练LSTM网络进行序列到序列回归和预测新数据的示例,请参见使用深度学习的序列到序列回归.
更深层次的LSTM网络
通过插入带有输出模式的额外LSTM层,可以使LSTM网络更深入“序列”LSTM层之前。为了防止过拟合,可以在LSTM层之后插入dropout层。
对于序列到标签分类网络,必须是最后一个LSTM层的输出模式“最后一次”.
numFeatures = 12;numHiddenUnits1 = 125;numHiddenUnits2 = 100;numClasses = 9;层= [...SequenceInputLayer(NumFeatures)LSTMLAYER(numhidentunits1,“OutputMode”,“序列”) dropoutLayer (0.2) lstmLayer (numHiddenUnits2“OutputMode”,“最后一次”) dropoutLayer(0.2) fulllyconnectedlayer (numClasses) softmaxLayer classificationLayer];
对于序列到序列分类网络,必须是最后一个LSTM层的输出模式“序列”.
numFeatures = 12;numHiddenUnits1 = 125;numHiddenUnits2 = 100;numClasses = 9;层= [...SequenceInputLayer(NumFeatures)LSTMLAYER(numhidentunits1,“OutputMode”,“序列”) dropoutLayer (0.2) lstmLayer (numHiddenUnits2“OutputMode”,“序列”) dropoutLayer(0.2) fulllyconnectedlayer (numClasses) softmaxLayer classificationLayer];
创建视频分类网络
为包含图像序列的数据创建一个深度学习网络,如视频和医学图像数据。
要将图像序列输入到网络中,使用序列输入层。
为了将卷积操作独立应用于每次步骤,首先使用序列折叠层将图像的序列转换为图像阵列。
要在执行这些操作后恢复序列结构,请使用序列展开层将该图像数组转换回图像序列。
要将图像转换为特征向量,使用flatten图层。
然后,您可以将向量序列输入到LSTM和Bilstm层中。
定义网络体系结构
创建一个分类LSTM网络,将28 × 28的灰度图像序列分为10类。
定义以下网络架构:
序列输入层,其输入大小为
[28 28 1].具有20个5 × 5滤波器的卷积、批处理归一化和ReLU层块。
具有200个隐藏单元的LSTM层,只输出最后一个时间步长。
完全连接的大小10(类数),后跟软MAX层和分类层。
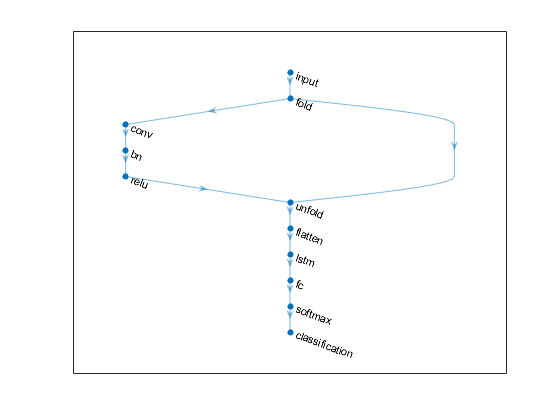
为了独立地在每次上执行卷积操作,包括卷积层之前的序列折叠层。LSTM层预计向量序列输入。为了恢复序列结构并将卷积层的输出重新塑造到特征向量的序列,在卷积层和LSTM层之间插入序列展开层和平坦层。
inputSize = [28 28 1];filterSize = 5;numFilters = 20;numHiddenUnits = 200;numClasses = 10;层= [...sequenceInputLayer (inputSize“名字”,“输入”) sequenceFoldingLayer (“名字”,“折”) convolution2dLayer (filterSize numFilters,“名字”,“conv”) batchNormalizationLayer (“名字”,bn的) reluLayer (“名字”,'relu') sequenceUnfoldingLayer (“名字”,'展开') flattenLayer (“名字”,“平”) lstmLayer (numHiddenUnits“OutputMode”,“最后一次”,“名字”,“lstm”)全连接列(numcrasses,“名字”,'fc') softmaxLayer (“名字”,“softmax”scassificationlayer(“名字”,“分类”)];
将层转换为层图并连接miniBatchSize序列折叠层的输出到序列展开层的相应输入。
lgraph = layerGraph(层);lgraph = connectLayers (lgraph,“折/ miniBatchSize”,'展开/小贴士');
查看最终的网络架构使用情节函数。
图绘制(lgraph)
兼容性考虑因素
参考文献
[1] M. Kudo,J. Toyama和M. Shimbo。“使用过度区域的多维曲线分类。”模式识别的字母.第20卷,第11-13期,第1103-1111页。
[2]UCI机器学习知识库:日语元音数据集.https://archive.ics.uci.edu/ml/datasets/Japanese+Vowels
扩展功能
另请参阅
Bilstmlayer.|classifyAndUpdateState|深层网络设计师|featureInputLayer|flattenLayer|gruLayer|lstmLayer|predictAndUpdateState|resetState|sequenceFoldingLayer|sequenceUnfoldingLayer
您还可以从以下列表中选择一个网站:
