使用深度学习的序列到序列回归
此示例显示如何通过使用深度学习来预测引擎的剩余使用寿命(RUL)。
要培训深度神经网络以预测时间序列或序列数据的数值,可以使用长短期内存(LSTM)网络。
此示例使用TurboOman引擎劣化模拟数据集,如[1]中所述。该示例列举了LSTM网络以预测在循环中测量的发动机(预测性维护)的剩余使用寿命,给定时间序列数据表示发动机中的各种传感器。培训数据包含100个发动机的模拟时间序列数据。每个序列的长度变化,对应于全部运行到故障(RTF)实例。测试数据包含100个部分序列和每个序列末尾的剩余使用寿命的相应值。
数据集包含100个训练观测值和100个测试观测值。
下载数据
下载和解压缩TurboOman发动机劣化模拟数据集https://ti.art.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/[2]。
每个时间序列的涡扇发动机退化仿真数据集代表一个不同的发动机。每台发动机启动时的初始磨损程度和制造差异都是未知的。发动机在每个时间序列开始时正常工作,并在序列的某个点上出现故障。在训练集中,故障的大小不断增长,直到系统发生故障。
数据包含带有26列的ZIP压缩文本文件,由空格分隔。每行是在单个操作周期期间拍摄的数据的快照,每列都是不同的变量。列对应以下:
第一列-单位编号
第二列-周期中的时间
第3-5列-操作设置
柱6-26 - 传感器测量1-21
创建一个目录以存储TurboOman引擎劣化模拟数据集。
datafolder = fullfile(tempdir,“TurboOman”);如果〜存在(DataFolder,“dir”)mkdir(DataFolder);结尾
下载并提取涡扇发动机退化仿真数据集https://ti.art.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/。
从文件中解压缩数据cmapssdata.zip.。
filename =.“CMAPSSData.zip”;解压缩(文件名,datafolder)
准备训练数据
使用函数加载数据processTurboFanDataTrain附上这个例子。功能processTurboFanDataTrain从中提取数据filenamepredictors.并返回单元格阵列XTrain.和YTrain,包含培训预测器和响应序列。
filenamepredictors = fullfile(datafolder,“train_fd001.txt”);[xtrain,ytrain] = processturbofandataTrain(filenamepredictors);
删除具有恒定值的功能
在所有时间步骤中保持不变的特征会对训练产生负面影响。找到具有相同最小值和最大值的数据行,并删除这些行。
m = min([xtrain {:}],[],2);m = max([xtrain {:}],[],2);idxconstant = m == m;为了i = 1:numel(XTrain) XTrain{i}(idxConstant,:) = [];结尾
查看序列中剩余功能的数量。
numFeatures =大小(XTrain {1}, 1)
numfeatures = 17.
规范化培训预测
将训练预测因子标准化为零均值和单位方差。为了计算所有观察结果的平均值和标准偏差,水平地连接序列数据。
μ=意味着([XTrain {:}), 2);sig =性病([XTrain {}):, 0, 2);为了i = 1:numel(XTrain) XTrain{i} = (XTrain{i} - mu) ./ sig;结尾
剪辑的反应
为了在引擎接近失败时从序列数据中了解更多信息,将响应修剪到阈值150。这使得网络将具有更高RUL值的实例视为同等的。
用力推= 150;为了i = 1:numel(ytrain)ytrain {i}(ytrain {i}> thr)= thr;结尾
该图显示了第一观察和相应的剪裁响应。

为填充准备数据
为了最小化添加到迷你批次的填充量,可以按序列长度对训练数据进行排序。然后,选择一个小批量大小,将训练数据平均分割,减少小批量中的填充量。
按序列长度对训练数据进行排序。
为了i=1:numel(XTrain)序列= XTrain{i};sequenceLengths (i) =(序列,2)大小;结尾[Sequencelengths,IDx] =排序(Sequencelengths,“下”);XTrain = XTrain (idx);YTrain = YTrain (idx);
在条形图中查看排序的序列长度。
图栏(Sequencelengths)XLabel(“顺序”)ylabel(“长度”)标题(“排序数据”)
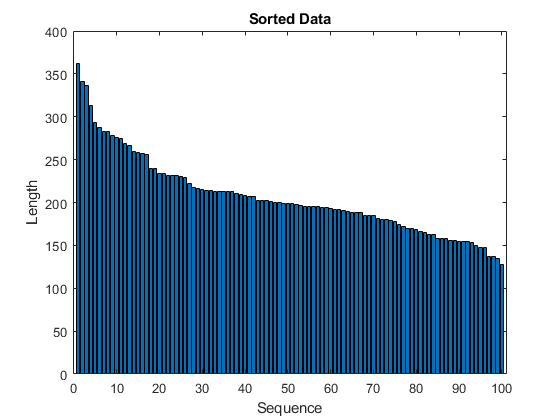
选择迷你批量大小,均匀地将培训数据分成,并减少粉碎中的填充量。指定迷你批次大小为20.该图示出了添加到未蚀刻和分类序列的填充。
minibatchsize = 20;

定义网络架构
定义网络架构。创建一个LSTM网络,该网络由带有200个隐藏单元的LSTM层组成,然后是一个完全连接的大小50层和辍学概率0.5的丢弃层。
numreponses = size(ytrain {1},1);numhidendunits = 200;层= [......sequenceInputlayer(numfeatures)lstmlayer(numhidentunits,“OutputMode”那“序列”) fulllyconnectedlayer (50) dropoutLayer(0.5) fulllyconnectedlayer (numResponses) regressionLayer];
指定培训选项。使用求解器训练60个时代的20个小批量'亚当'。指定学习率0.01。要防止渐变爆炸,请将梯度阈值设置为1.以保持按长度排序的序列“洗牌”到'绝不'。
Maxepochs = 60;minibatchsize = 20;选项=培训选项('亚当'那......'maxepochs',maxepochs,......'minibatchsize'miniBatchSize,......“InitialLearnRate”, 0.01,......“GradientThreshold”, 1......“洗牌”那'绝不'那......'plots'那'培训 - 进步'那......“详细”, 0);
训练网络
使用培训网络trainNetwork。
net = trainnetwork(xtrain,ytrain,图层,选项);
测试网络
使用函数准备测试数据processturbofandataTest.附上这个例子。功能processturbofandataTest.从中提取数据filenamepredictors.和filenameResponses并返回单元格阵列XTest.和欧美,分别包含测试预测因子和反应序列。
filenamepredictors = fullfile(datafolder,“test_FD001.txt”);filenameResponses = fullfile (dataFolder,“RUL_FD001.txt”);[xtest,ytest] = procesctturbofandataTest(filenamepredictors,filenamersponses);
使用移除带有常量值的特性idxConstant根据训练数据计算。使用与训练数据相同的参数对测试预测器进行归一化。在用于训练数据的相同阈值上剪辑测试响应。
为了i = 1:numel(XTest) XTest{i}(idxConstant,:) = [];XTest{i} = (XTest{i} - mu) ./ sig;YTest{i}(YTest{i} > thr) = thr;结尾
利用测试数据进行预测预测。为防止功能向数据添加填充,请指定迷你批量大小1。
ypred =预测(net,xtest,'minibatchsize'1);
LSTM网络一次对部分序列进行预测一次。在每个时间步骤中,网络在此时间步骤中使用该值的值,以及从上一时间步骤计算的网络状态。网络在每个预测之间更新其状态。这预测函数返回这些预测的序列。预测的最后一个元素对应于预测的部分序列的RUL。
或者,您可以通过使用predictandanddatestate.。当您具有到达流的时间步骤的值时,这很有用。通常,与一次进行预测相比,在完全序列上进行预测更快。有关示例,显示如何通过在单时间步骤预测之间更新网络来预测未来时间步骤,请参阅基于深度学习的时间序列预测。
在一个情节中设想一些预测。
idx = randperm(元素个数(YPred), 4);数字为了i = 1:numel(idx) subplot(2,2,i) plot(YTest{idx(i)},“——”) 抓住在情节(YPred {idx (i)},'.-') 抓住从ylim([0 thr + 25])标题(“测试观察”+ idx (i))包含(“时间步骤”)ylabel(“rul”)结尾传奇([“测试数据”“预料到的”],'地点'那“东南”)
对于给定的部分序列,预测的当前RUL是预测序列的最后一个元素。计算预测的根均方误差(RMSE),并在直方图中可视化预测误差。
为了i = 1:numel(ytest)ytestlast(i)= ytest {i}(结束);ypredlast(i)= ypred {i}(结束);结尾图rmse = sqrt(mean((YPredLast - YTestLast).^2))直方图(YPredLast - YTestLast) title(“rmse =”+ RMSE)Ylabel(“频率”)xlabel(“错误”)
参考
Saxena,Abhinav,Kai Goebel,Don Simon和Neil Eklund。“飞机发动机碰到故障模拟的损伤传播建模。”在预测和健康管理,2008年。2008年PHM。国际会议1 - 9页。IEEE 2008。
萨克森,阿比纳夫,凯·戈贝尔。涡扇发动机退化模拟数据集NASA AMES预测数据存储库https://ti.art.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/,美国宇航局阿米斯研究中心,迈夫特田,加州
也可以看看
lstmLayer|predictandanddatestate.|sequenceInputlayer.|trainingOptions|trainNetwork
相关话题
你也可以从以下列表中选择一个网站:
