classifyandupdateState.
使用经过培训的经常性神经网络对数据进行分类并更新网络状态
句法
描述
您可以在CPU或GPU上使用培训的深度学习网络进行预测。使用GPU需要并行计算工具箱™和支持的GPU设备。万博1manbetx有关支持设备的信息,请参阅万博1manbetxGPU通万博1manbetx过发布支持(并行计算工具箱).使用该硬件要求指定硬件要求'executionenvironment'名称值对参数。
[分类数据UpdatedNet.那ypred.] = classiffandupdateState(regnet.那序列)序列使用培训的经常性神经网络regnet.并更新网络状态。
此功能仅支持经常性的神经网络万博1manbetx。输入regnet.必须至少有一个复发层。
[使用先前语法中的任何参数和一个或多个指定的其他选项UpdatedNet.那ypred.] = classiffandupdateState(___那名称,价值)名称,价值对论点。例如,'minibatchsize',27使用少量批量进行分类数据27
[使用先前语法中的任何参数,返回分类得分的矩阵,并更新网络状态。UpdatedNet.那ypred.那得分] = classiffandupdateState(___)
小费
当用不同长度的序列进行预测时,迷你批量大小可以影响添加到的输入数据的填充量,这导致不同的预测值。尝试使用不同的值,以查看最适合您的网络。要指定小批量大小和填充选项,请使用'minibatchsize'和'sequencelength'选项分别。
例子
分类和更新网络状态
利用递归神经网络对数据进行分类,并更新网络状态。
加载Japanesevowelsnet.,如[1]和[2]中所述,在日本元音数据集上培训的预训练的长短期内存(LSTM)网络。该网络在序列上培训,序列长度与迷你批量大小为27。
加载Japanesevowelsnet.
查看网络架构。
网。层
ANS = 5x1层阵列具有图层:1'SENDUNINPUT'序列输入序列输入序列输入12尺寸2'LSTM'LSTM LSTM LSTM LSTM为100个隐藏单元3'FC'完全连接的9完全连接的第4层SoftMax'SoftMax SoftMax SoftMax 5'ClassOutput'分类输出Crossentropyex与“1”和其他8个类
加载测试数据。
[XTest,欧美]= japaneseVowelsTestData;
循环在序列中的时间步长。分类每次步骤并更新网络状态。
X = XTest {94};numTimeSteps =大小(X, 2);为了i = 1:numtimesteps v = x(:,i);[net,label,score] = classifyandupdattestate(net,v);标签(i)=标签;结尾
在楼梯绘图中绘制预测的标签。该曲线显示了预测如何在时间步骤之间发生变化。
图楼梯(标签,'-o')xlim([1 numtimesteps])xlabel(“时间步骤”)ylabel(“预测的课程”) 标题(“随着时间的推移分类”)
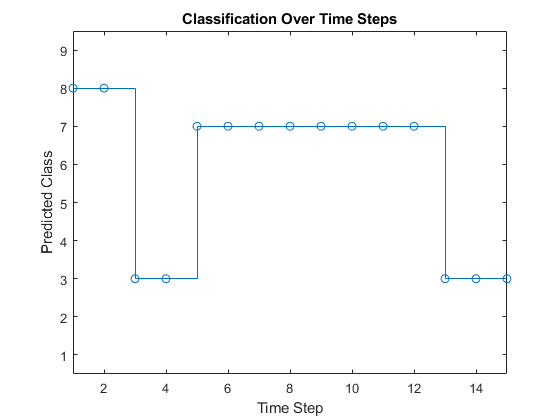
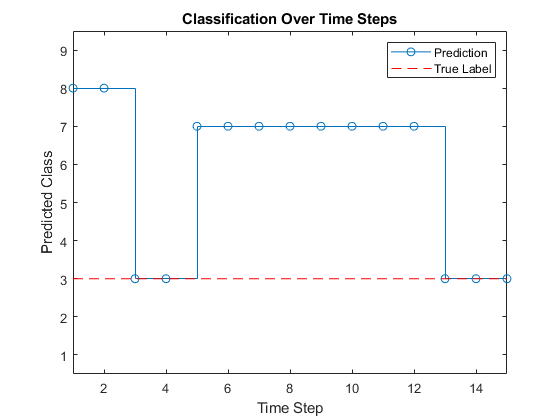
将预测与真实标签进行比较。绘制一个水平线,显示观察的真实标签。
truelabel = ytest(94)
truilabel =分类3.
抓住在线([1 numtimesteps],[Truilabel Truilabel],......'颜色'那'红色的'那......“线型”那' - ')传说([“预言”“真品”])
输入参数
输出参数
算法
当您使用该网络训练网络时Trainnetwork.功能,或使用预测或验证功能时Dagnetwork.和系列网络对象,软件使用单精度浮点算术执行这些计算。培训,预测和验证的功能包括Trainnetwork.那预测那分类, 和激活.当您使用CPU和GPU培训网络时,该软件使用单精度算术。
参考文献
[1] M. Kudo,J. Toyama和M. Shimbo。“使用过度区域的多维曲线分类。”模式识别字母.第20卷,第11-13期,第1103-1111页。
[2]UCI机器学习知识库:日语元音数据集.https://archive.ics.uci.edu/ml/datasets/japanese+vowels.
扩展能力
您还可以从以下列表中选择一个网站:
