使用卷积神经网络对文本数据进行分类
此示例显示如何使用卷积神经网络对文本数据进行分类。
要使用卷积对文本数据进行分类,必须将文本数据转换为图像。为此,垫或截断观察结果是否具有恒定长度S.并将文档转换为长度的单词矢量序列C使用单词嵌入。然后,您可以将文档表示为1-by-S.-经过-C图像(高度1,宽度的图像S., 和C频道)。
要将文本数据从CSV文件转换为图像,请创建一个tabulartextdatastore.目的。转换从中读取的数据tabulartextdatastore.通过呼叫来实现图像的图像转变使用自定义转换功能。这变换extdata.函数,在示例的末尾列出,取自数据存储读取的数据和预先映射的单词嵌入,并将每个观察转换为单词向量数组。
该示例列举了一个网络,其具有不同宽度的1-D卷积滤波器。每个过滤器的宽度对应过滤器可以看到的单词数(n-gram长度)。网络具有多个卷积层分支,因此它可以使用不同的n克长度。
加载佩带的单词嵌入
加载佩带的FastText Word嵌入。此功能需要文本分析工具箱™模型对于FastText英语160亿令牌字嵌入万博1manbetx支持包。如果未安装此支持万博1manbetx包,则该函数提供了下载链接。
emb = fasttextwordembedding;
加载数据
从数据中创建表格文本数据存储factoryreports.csv.。阅读数据“描述”和“类别”仅限列。
Filenametrain =.“factoryreports.csv”;TextName =.“描述”;labelName =“类别”;ttdstrain = tabulartextdataStore(filenametrain,'selectedvariamblenames',[textname labelname]);
预览数据存储。
ttdstrain.readsize = 8;预览(TTDStrain)
ans =.8×2表说明类别_______________________________________________________________________ ______________________ {“项目是偶尔卡在扫描器卷轴。”} {'机械故障'} {'响亮的嘎嘎声和敲打声来自瓶子活塞。'} {'机械故障'} {'在开始工厂时有削减到电源。} {'电子失败'} {'汇编程序中的油炸电容器。'} {'电子失败'} {'混音器绊倒了保险丝。'{“电子故障”} {“构造代理中的”突发管道喷洒冷却剂“。} {'泄漏'} {'一个熔丝是在混音器中吹来的。} {'电子失败'} {'事情继续滚动腰带。'} {'机械故障'}
创建自定义转换函数,将从数据存储读取的数据转换为包含预测器和响应的表。这变换extdata.函数,在示例末尾列出,获取从a读取的数据tabulartextdatastore.对象并返回预测器表和响应表。预测器是1-by-Sequencelength.-经过-C由嵌入单词给出的单词向量阵列胚胎, 在哪里C是嵌入的维度。对课程的响应是分类标签Classnames.。
使用培训数据读取标签readlabels.函数,在示例的末尾列出,并找到唯一的类名。
Labels = ReadLabels(TTDStrain,LabelName);ClassNames =独特(标签);numobservations = numel(标签);
使用DataStore使用变换extdata.功能并指定序列长度为14。
Sequencelength = 14;TDStrain = Transform(TTDStrain,@(数据)变换extData(数据,序列),emb,classNames))
TDStrain = TranspordedDataStore具有属性:下面的atataStore:[1×1 matlab.io.datastore.tabulartextextdataStore] SupportedOutputFo万博1manbetxrmats:[“TXT”“CSV”“XLSX”“XLS”“Parquet”“Parq”“PAGG”“JCG”“JPG”“JPG”“JPG”“JPG”“JPG”“JPG”“JPG”“JPG”“JPG”“JPG”“JPG”“JPG”“JPG”“JPG”“JPG”“JPG”“JPG”“JPG”)“tif”“tiff”“wav”“flac”“ogg”“mp4”“m4a”]变换:{@(数据)变换extdata(数据,semencelength,emb,classNames)} includeinfo:0
预览转换的数据存储。预测器是1-by-S.-经过-C阵列,在哪里S.是序列长度和C是功能数量(嵌入尺寸)。答案是分类标签。
预览(TDStrain)
ans =.8×2表预测_________________ __________________ {1×14×300单}机械故障{1×14×300单} {1×14×300单}电子故障{1×14×300单}电子故障{1×14×300单}电子故障{1×14×300单}泄漏{1×14×300单}电子故障{1×14×300单}机械故障
定义网络架构
为分类任务定义网络架构。
以下步骤描述了网络架构。
指定输入大小为1-by-S.-经过-C, 在哪里S.是序列长度和C是功能数量(嵌入尺寸)。
对于n克长度2,3,4和5,形成包含卷积层,批量归一化层,Relu层,丢弃层和最大池层的层的块。
对于每个块,指定200个卷积滤波器的1-by-N和汇集区域为1-by-S., 在哪里N是n-gram长度。
将输入层连接到每个块,并使用深度级联层连接块的输出。
要对输出进行分类,请包括具有输出大小的完全连接的图层K.,softmax层和分类层,在哪里K.是课程的数量。
首先,在层阵列中,指定输入层,为UNIGRAM的第一块,深度倾斜层,完全连接的层,软MAX层和分类层。
numfeatures = emb.dimension;InputSize = [1个Sequencelength NumFeatures];numfilters = 200;ngramlengths = [2 3 4 5];numblocks = numel(ngramlengths);numclasses = numel(classnames);
创建包含输入层的图层图。将归一化选项设置为'没有任何'和图层名称'输入'。
tallay = imageInputLayer(输入,'正常化'那'没有任何'那'名称'那'输入');Lgraph = LayerGraph(层);
对于每个n克长度,创建卷积块,批量归一化,relu,丢弃和最大池池层。将每个块连接到输入层。
为了j = 1:numblocks n = n = ngramlengths(j);block = [卷积2dlayer([1 n],numfilters,'名称'那“conc”+ n,'填充'那'相同的'batchnormalizationlayer('名称'那“bn”+ n)剥离器('名称'那“relu”+ n)oppoutlayer(0.2,'名称'那“降低”+ n)maxpooling2dlayer([1个Sequencelength],'名称'那“最大限度”+ n)];Lgraph = Addlayers(LGROPL,块);Lgraph = ConnectLayers(LAPHAGE,'输入'那“conc”+ n);结尾
在绘图中查看网络架构。
图绘制(3)标题(“网络架构”)
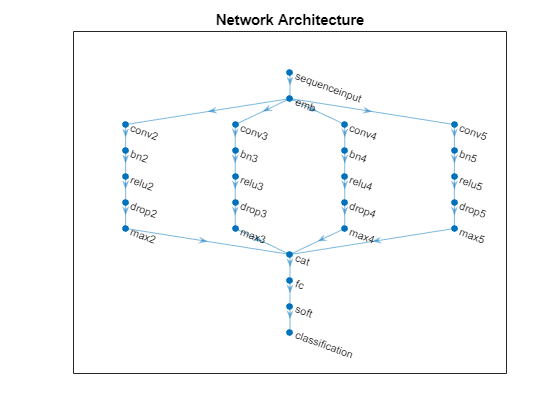
添加深度级联层,完全连接的层,软墨幅层和分类层。
图层= [深度扫描层(numblocks,'名称'那'深度')全连接列(numcrasses,'名称'那'fc')softmaxlayer('名称'那'柔软的'scassificationlayer('名称'那'分类')];Lgraph = Addlayers(LAGHAGH,层);图绘制(3)标题(“网络架构”)
将最大池层连接到深度连接层,并在绘图中查看最终网络架构。
为了j = 1:numblocks n = n = ngramlengths(j);Lgraph = ConnectLayers(LAPHAGE,“最大限度”+ n,“深度/在”+ j);结尾图绘制(3)标题(“网络架构”)
火车网络
指定培训选项:
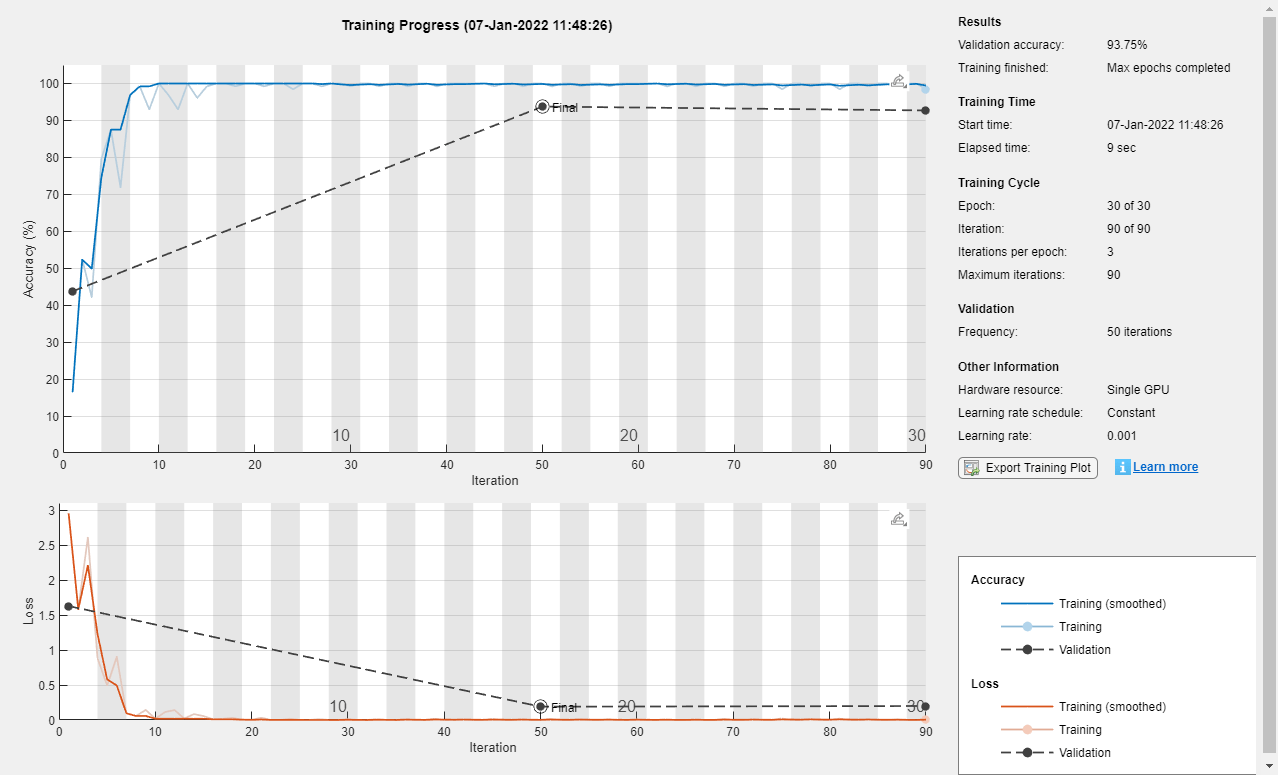
迷你批量大小为128的火车。
不要随数据存储而擦拭数据,因为数据存储不是可擦拭的。
显示培训进度绘图并抑制冗长输出。
minibatchsize = 128;numiterationsperepoch = bloor(numobservations / minibatchsize);选项=培训选项('亚当'那......'minibatchsize',小匹马,......'洗牌'那'绝不'那......'plots'那'培训 - 进步'那......'verbose',错误的);
使用培训网络Trainnetwork.功能。
net = trainnetwork(tdstrain,lgraph,选项);

使用新数据预测
对三个新报告的事件类型进行分类。创建包含新报告的字符串数组。
eportsnew = [“冷却液在分拣机下面汇集。”“分拣机在启动时吹熔断。”“汇编者有一些非常响亮的嘎嘎声的声音。”];
使用预处理步骤作为培训文档预处理文本数据。
xnew = preprocesstext(eportsnew,sequencelength,mem);
使用培训的LSTM网络对新序列进行分类。
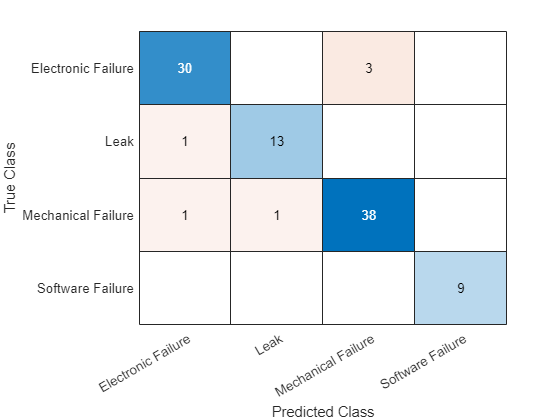
labelsnew =分类(net,xnew)
Labelsnew =3×1分类泄漏电子故障机械故障
读取标签功能
这readlabels.函数创建副本tabulartextdatastore.目的TTDS.并从中读取标签labelName.柱子。
功能标签= readlabels(ttds,labelname)ttdsnew = copy(ttds);ttdsnew.selectedvariablenames = labelName;tbl = readall(ttdsnew);标签= TBL。(LabelName);结尾
转换文本数据函数
这变换extdata.函数取自读取的数据tabulartextdatastore.对象并返回预测器表和响应表。预测器是1-by-Sequencelength.-经过-C由嵌入单词给出的单词向量阵列胚胎, 在哪里C是嵌入的维度。对课程的响应是分类标签Classnames.。
功能DataTransformed = TransformTextData(数据,Sequencelength,EMB,ClassNames)%预处理文件。TextData = Data {:,1};%prepecess文本dataTransformed =预处理文本(TextData,Sequencelength,EMB);%读取标签。标签=数据{:,2};响应=分类(标签,ClassNames);%将数据转换为表。datatransformed.responses =响应;结尾
预处理文本功能
这preprocesstextdata.函数采用文本数据,序列长度和单词嵌入并执行以下步骤:
授权文本。
将文本转换为小写。
使用嵌入将文档转换为指定长度的字向量的序列。
将单词矢量序列重新插入输入到网络中。
功能tbl = preprocesstext(textdata,sequencelength,mem)文档= tokenizeddocument(textdata);文件=较低(文件);%将文档转换为嵌入式逐个0个图像。predictors = doc2sequence(mem,文件,'长度',sequencelength);%重塑图像大小为1-ef-sequenceLight-EmbeddingDimension。预测器= Cellfun(@(x)置换(x,[3 2 1]),预测器,'统一输出',错误的);TBL =表;tbl.predictors =预测因子;结尾
也可以看看
BatchnormalizationLayer.|Convolution2Dlayer.|分层图|培训选项|Trainnetwork.|转变|doc2sequence.(文本分析工具箱)|fasttextwordembeddings.(文本分析工具箱)|令人畏缩的鳕文(文本分析工具箱)|WordCloud.(文本分析工具箱)|Wordembeddings.(文本分析工具箱)
相关话题
- 使用深度学习对文本数据进行分类(文本分析工具箱)
- 使用自定义迷你批处理数据存储对内存外文本数据进行分类(文本分析工具箱)
- 为分类创建简单的文本模型(文本分析工具箱)
- 使用主题模型分析文本数据(文本分析工具箱)
- 使用多字词分析文本数据(文本分析工具箱)
- 训练情感分类器(文本分析工具箱)
- 使用深度学习序列分类
- 深入学习的数据购物
- 在Matlab中深入学习
您还可以从以下列表中选择一个网站:
