比较深入学习网络信用违约预测
得到工作流统计套利的概述,然后遵循一系列的例子来看看MATLAB®应用功能。
消费贷款的面板数据集允许您识别和预测违约率模式。你可以使用面板数据训练神经网络来预测违约率从去年书籍和风险水平。
这个例子需要深度学习工具箱™和风险管理工具箱™。
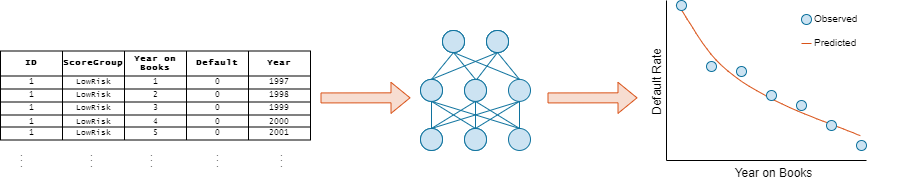
在本例中,您创建和火车三个信用违约预测模型:
逻辑回归网络(有时也称为一个单层感知器)
多层感知器(MLP)
剩余网络(ResNet)
你可以表达这些模型的神经网络不同的复杂性和深度。
信用违约数据加载
加载零售信贷面板数据集。这些数据包括以下变量:
ID——贷款标识符。ScoreGroup——贷款信用评分开始时,离散分成三组:高的风险,中等风险,低风险。小无赖——年书。默认的违约指标。的值1为默认的意味着相应的日历年贷款违约。一年-日历年度。
文件名= fullfile (toolboxdir (“风险”),“riskdata”,“RetailCreditPanelData.mat”);台=负载(文件名). data;
编码分类变量
培训深入学习网络,首先必须对分类编码ScoreGroup变量在一个炎热的编码向量。
视图的顺序ScoreGroup类别。
类别(tbl.ScoreGroup) '
ans =1×3细胞{“高风险”}{中等风险的}{“低风险”}
将分类ScoreGroup使用的变量在一个炎热的编码向量onehotencode函数。
riskGroup = onehotencode (tbl.ScoreGroup 2);
在一个炎热的向量添加到表中。
资源描述。HighRisk = riskGroup (: 1);资源描述。MediumRisk = riskGroup (:, 2);资源描述。LowRisk = riskGroup (: 3);
删除原来的ScoreGroup从表中变量使用removevars。
台= removevars(资源描述,{“ScoreGroup”});
因为你想预测默认的变量的反应,移动默认的变量的桌子上。
台= movevars(资源描述,“默认”,“后”,“LowRisk”);
查看表的前几行。请注意,ScoreGroup变量被分成多个列,分类值作为变量名。
头(台)
ID小无赖年HighRisk MediumRisk LowRisk默认__ ___ ____ ____ ____ ________ __________ 1998 1 1997 0 0 1 0 1 2 0 0 1 0 1 3 1999 0 0 1 0 1 2000 0 0 1 0 1 2002 2001 0 0 1 0 1 6 0 0 1 0 1 2004 2003 0 0 1 0 1 8 0 0 1 0
分割数据
分区数据集训练、验证和测试分区使用独特的贷款ID数字。留出60%的数据进行训练,20%进行验证,20%用于测试。
找到独特的贷款id。
idx =独特(tbl.ID);numObservations =长度(idx);
确定每个分区的数量的观察。
numObservationsTrain =地板(0.6 * numObservations);numObservationsValidation =地板(0.2 * numObservations);numObservationsTest = numObservations - numObservationsTrain numObservationsValidation;
创建一个数组的随机指标的观察和分区使用分区大小。
rng (“默认”)idxShuffle = idx (randperm (numObservations));idxTrain = idxShuffle (1: numObservationsTrain);idxValidation = idxShuffle (numObservationsTrain + 1: numObservationsTrain + numObservationsValidation);idxTest = idxShuffle (numObservationsTrain + numObservationsValidation + 1:结束);
找到相对应的表条目的数据集的分区。
idxTrainTbl = ismember (tbl.ID idxTrain);idxValidationTbl = ismember (tbl.ID idxValidation);idxTestTbl = ismember (tbl.ID idxTest);
把感兴趣的变量任务(小无赖,HighRisk,MediumRisk,LowRisk,默认的),从表中删除所有其他变量。
台= removevars(资源描述,{“ID”,“年”});头(台)
小无赖HighRisk MediumRisk LowRisk默认___ ____ ____ ________ __________ 1 0 0 1 0 2 0 0 1 0 3 0 0 1 0 4 0 0 1 0 5 0 0 1 0 6 0 0 1 0 7 0 0 1 0 8 0 0 1 0
分区表的数据训练、验证和测试使用索引分区。
tblTrain =(资源(idxTrainTbl:);tblValidation =(资源(idxValidationTbl:);tblTest =(资源(idxTestTbl:);
定义网络体系结构
您可以使用不同的深度学习架构信用违约概率预测的任务。小型网络快速火车,但更深层次的网络可以学习更抽象的特性。选择神经网络架构需要平衡计算时间与精度。在这个例子中,您定义三个网络体系结构,不同层次的复杂性。
逻辑回归网络
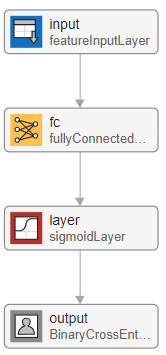
第一个包含四层网络是一个简单的神经网络。
从一个功能的输入层,它通过表格数据(信用面板数据)到网络中。在这个例子中,有四个输入功能:小无赖,HighRisk,MediumRisk,LowRisk。配置输入层使用z分数标准化规范化数据。规范化的数据是重要的任务的规模和范围的输入变量是非常不同的。
接下来,使用一个完全连接层和一个输出乙状结肠层紧随其后。对于最后一层,使用一个自定义二叉叉损失层。这一层是附属于这个例子作为支持文件。万博1manbetx
logisticLayers = [featureInputLayer (4“归一化”,“zscore”)fullyConnectedLayer (1) sigmoidLayer BinaryCrossEntropyLossLayer (“输出”));
这个网络被称为单层感知器。你可以想象网络使用深层网络设计师或者是analyzeNetwork函数。
deepNetworkDesigner (logisticLayers)
你可以很容易地表明,单层感知器神经网络相当于逻辑回归。让 观察1-by-4向量包含的特性 。与输入 完全连接层的输出
。
完全连接的输出层为乙状结肠提供输入层。乙状结肠层然后输出
。
乙状结肠的输出层相当于逻辑回归模型。最后一层的神经网络是一种二进制叉损失层。最小化损失相当于二进制叉最大化可能在逻辑回归模型。
多层感知器
下一个网络也有类似的建筑逻辑回归模型,但有一个额外的完全连接层和一个输出大小为100,其次是ReLU非线性激活函数。这种类型的网络被称为多层感知器由于添加另一个隐藏层和非线性激活函数。而单层感知器只能学习线性函数,多层感知器可以学习复杂,非线性的输入和输出数据之间的关系。
mlpLayers = [featureInputLayer (4“归一化”,“zscore”)fullyConnectedLayer (100) reluLayer fullyConnectedLayer (1) sigmoidLayer BinaryCrossEntropyLossLayer (“输出”));deepNetworkDesigner (mlpLayers)

剩余的网络
最后网络,创建一个残余网络(ResNet)[1]从多个栈完全连接层和ReLU激活。最初开发的图像分类、ResNets已被证明成功的在许多领域。因为ResNet有更多的参数比多层感知器和物流网络,他们需要更长的时间来训练。
residualLayers = [featureInputLayer (4“归一化”,“zscore”,“名字”,“输入”)fullyConnectedLayer (16“名字”,“fc1”)batchNormalizationLayer (“名字”,“bn1”)reluLayer (“名字”,“relu1”)fullyConnectedLayer (32,“名字”,“resblock1-fc1”)batchNormalizationLayer (“名字”,“resblock1-bn1”)reluLayer (“名字”,“resblock1-relu1”)fullyConnectedLayer (32,“名字”,“resblock1-fc2”)additionLayer (2“名字”,“resblock1-add”)batchNormalizationLayer (“名字”,“resblock1-bn2”)reluLayer (“名字”,“resblock1-relu2”)fullyConnectedLayer (64,“名字”,“resblock2-fc1”)batchNormalizationLayer (“名字”,“resblock2-bn1”)reluLayer (“名字”,“resblock2-relu1”)fullyConnectedLayer (64,“名字”,“resblock2-fc2”)additionLayer (2“名字”,“resblock2-add”)batchNormalizationLayer (“名字”,“resblock2-bn2”)reluLayer (“名字”,“resblock2-relu2”)fullyConnectedLayer (1,“名字”,“取得”)sigmoidLayer (“名字”,“乙状结肠”)BinaryCrossEntropyLossLayer (“输出”));residualLayers = layerGraph (residualLayers);residualLayers = addLayers (residualLayers fullyConnectedLayer(32岁“名字”,“resblock1-fc-shortcut”));residualLayers = addLayers (residualLayers fullyConnectedLayer (64,“名字”,“resblock2-fc-shortcut”));residualLayers = connectLayers (residualLayers,“relu1”,“resblock1-fc-shortcut”);residualLayers = connectLayers (residualLayers,“resblock1-fc-shortcut”,“resblock1-add / in2”);residualLayers = connectLayers (residualLayers,“resblock1-relu2”,“resblock2-fc-shortcut”);residualLayers = connectLayers (residualLayers,“resblock2-fc-shortcut”,“resblock2-add / in2”);deepNetworkDesigner (residualLayers)
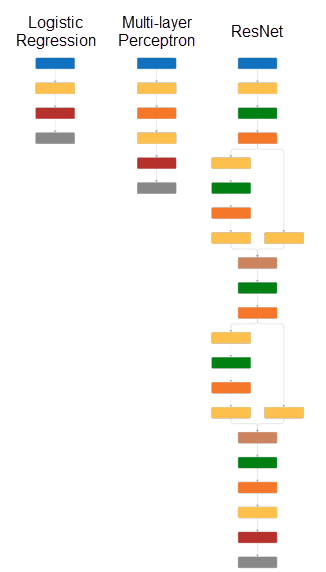
网络深度
的深度深度学习的网络是一个重要的概念和定义是最多的连续卷积或完全连接层(由黄色块在下图)在从输入层到输出层。更深层次的一个网络,它可以学习更复杂的功能。在这个例子中,物流网络的深度为1、2的多层感知器有一个深度和剩余网络的深度6。
指定培训选项
指定培训选项。
火车用亚当优化器。
设置初始学习速率为0.001。
mini-batch大小设置为512。
打开培训发展情节和关闭命令窗口的输出。
混乱的数据在每一个时代的开始。
监控网络在训练精度通过指定验证数据,并使用它来验证网络每1000次迭代。
选择= trainingOptions (“亚当”,…“InitialLearnRate”,0.001,…“MiniBatchSize”,512,…“阴谋”,“训练进步”,…“详细”假的,…“洗牌”,“every-epoch”,…“ValidationData”tblValidation,…“ValidationFrequency”,1000);
逻辑回归的损失景观网络是凸的,因此,它不需要训练的时代。逻辑回归和多层感知器模型,火车15时代。对剩余网络越复杂,火车50时代。
logisticOptions =选项;logisticOptions。MaxEpochs = 15;mlpOptions =选项;mlpOptions。MaxEpochs = 15;residualOptions =选项;residualOptions。MaxEpochs = 50;
三个网络有不同的体系结构,所以它们需要不同的训练集的选择达到最佳性能。您可以执行优化编程方式或交互使用实验管理器。为一个例子,演示如何执行hyperparameter扫描训练选项,看看创建一个分类深度学习实验。
列车网络的
使用定义的架构培训网络,训练数据,训练选项。默认情况下,trainNetwork使用GPU如果可用;否则,它使用一个CPU。培训在GPU需要并行计算工具箱™和支持GPU设备。万博1manbetx支持设备的信息,请参阅万博1manbetxGPU计算的需求(并行计算工具箱)。您还可以指定使用的执行环境ExecutionEnvironment名称-值参数trainingOptions。
为了避免等待培训、负载pretrained网络通过设置doTrain旗帜假。训练网络使用trainNetwork,设置doTrain旗帜真正的。
培训时间使用NVIDIA®GeForce®RTX 2080 Ti:
物流网络,大约4分钟
多层感知器,大约5分钟
剩余网络——大约35分钟
doTrain = false;如果doTrain logisticNet = trainNetwork (tblTrain,“默认”、logisticLayers logisticOptions);mlpNet = trainNetwork (tblTrain,“默认”、mlpLayers mlpOptions);residualNet = trainNetwork (tblTrain,“默认”、residualLayers residualOptions);其他的负载logisticTrainedNetwork负载mlpTrainedNetwork负载residualTrainedNetwork结束
测试网络
违约概率预测的测试数据使用训练网络。
tblTest。logisticPred =预测(logisticNet tblTest (: 1: end-1));tblTest。mlpPred =预测(mlpNet tblTest (: 1: end-1));tblTest。residualPred =预测(residualNet tblTest (: 1: end-1));
违约率在书上
评估网络的性能,使用groupsummary函数组的真正的违约率和相应的预测(由年书小无赖变量),并计算平均值。
summaryYOB = groupsummary (tblTest,“小无赖”,“的意思是”,{“默认”,“logisticPred”,“mlpPred”,“residualPred”});头(summaryYOB)
小无赖GroupCount mean_Default mean_logisticPred mean_mlpPred mean_residualPred ___ __________ _______ _________________ _______ _________________ 18917 19364 0.017352 0.017471 0.018056 0.017663 0.012158 0.014209 0.015486 0.014192 18526 0.011875 0.011538 0.013154 0.011409 18232 0.011683 0.0093902 0.011151 0.010311 17727 17925 0.0082008 0.007626 0.0089826 0.0093438 0.0066565 0.0062047 0.0062967 0.0073401 12294 0.0030909 6361 0.0017293 0.0041463 0.0029052 0.0025272 0.0050643 0.0042998 0.0047071 8
情节真实的平均违约率在平均预测年的书。
网络= [“逻辑回归网络”,“多层Percerptron网络”,“剩余网络”];图tiledlayout (“流”,“TileSpacing”,“紧凑”)为i = 1:3 nexttile散射(summaryYOB.YOB summaryYOB.mean_Default * 100,‘*’);持有在情节(summaryYOB.YOB summaryYOB{:,我+ 3}* 100);持有从标题(网络(i))包含(“年书”)ylabel (的违约率(%))传说(“观察”,“预测”)结束

所有三个网络表现出明显的下降趋势,与违约率下降年书的数量增加。年3和4是一个异常下降的趋势。总的来说,这三个模型预测违约率,甚至简单的逻辑回归模型预测的一般趋势。剩余网络捕获一个更复杂的、非线性关系到物流模型相比,这只能满足线性关系。
违约率由分数组
使用信用评分小组作为分组变量来计算每个分数的观察和预测违约率组。
解码ScoreGroup回到绝对分数组。
ScoreGroup = onehotdecode (tblTest {: 2:4}, {“HighRisk”,“MediumRisk”,“LowRisk”2)};tblTest。年代coreGroup = ScoreGroup; tblTest = removevars(tblTest,{“HighRisk”,“MediumRisk”,“LowRisk”});riskGroups =类别(tblTest.ScoreGroup);
使用groupsummary函数组真正的违约率和预测小无赖和ScoreGroup,并返回意味着每组。
numYOB =身高(summaryYOB);numRiskGroups =身高(riskGroups);summaryYOBScore = groupsummary (tblTest, {“ScoreGroup”,“小无赖”},“的意思是”,{“默认”,“logisticPred”,“mlpPred”,“residualPred”});头(summaryYOBScore)
ScoreGroup小无赖GroupCount mean_Default mean_logisticPred mean_mlpPred mean_residualPred __________ ___ __________ _______ _________________ _______ _________________ HighRisk 1 6424 0.029577 0.028404 0.031563 0.02973 HighRisk 2 6180 0.020065 0.02325 0.026649 0.023655 HighRisk 3 5949 0.019163 0.019013 0.022484 0.018724 HighRisk 4 5806 0.020668 0.015535 0.018957 0.017207 HighRisk 5 5634 0.01349 0.012686 0.01577 0.015374 HighRisk 6 5531 0.013379 0.010354 0.010799 0.01215 HighRisk 7 3862 0.0051787 0.0084466 0.0071398 0.0083738 HighRisk 8 2027 0.0034534 0.0068881 0.0047145 0.0040559
情节真实的平均违约率与预期利率年书和风险。
图t = tiledlayout (“流”,“TileSpacing”,“紧凑”);颜色=线(3);小无赖= summaryYOBScore.YOB;默认= summaryYOBScore.mean_Default * 100;组= summaryYOBScore.ScoreGroup;为我= 1:3 pred = summaryYOBScore {:, i + 4} * 100;meanScore =重塑(pred numYOB numRiskGroups);nexttile hs = gscatter(小无赖,默认情况下,集团,颜色,‘*’6、假);持有在colororder(颜色)情节(meanScore)从标题(网络(i))包含(“年书”)ylabel (的违约率(%)网格)在结束标签= [“真正的:“+ riskGroups;”Pred:“+ riskGroups];乐金显示器=传奇(标签);lgd.Layout。瓦= 4;
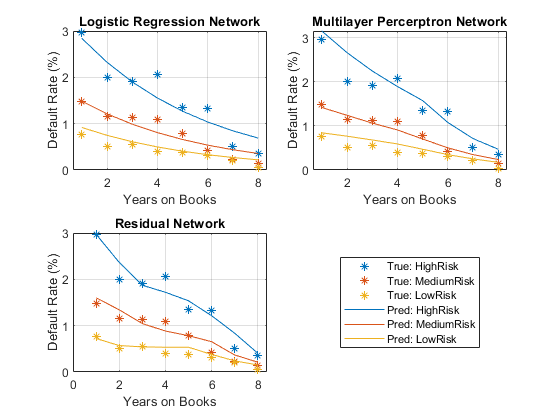
图显示所有分数组同样的行为随着时间的推移,总体下降的趋势。在高危人群,第四年没有下降的趋势。中等风险集团年3和4平。最后,在低风险组,第三年增加。这些不规则的趋势很难辨别与简单的逻辑回归模型。
对于一个例子,演示如何使用locally-interpretable model-agnostic解释(石灰)和沙普利值可解释性的预测技术来理解剩余网络信用违约预测,明白了解释为违约概率和压力测试深度学习网络(风险管理工具箱)。
引用
[1]他开明、象屿张任Shaoqing,剑太阳。“深层残留图像识别的学习。”在《IEEE计算机视觉与模式识别会议,770 - 778页。2016年。
另请参阅
trainNetwork|trainingOptions|fullyConnectedLayer|深层网络设计师|featureInputLayer
相关的例子
- 解释为违约概率和压力测试深度学习网络(风险管理工具箱)
- 使用强化学习工具箱™对冲期权(金融工具箱)
- 创建简单的深度学习网络分类
- 火车卷积神经网络回归