使用强化学习工具箱™对冲期权
超越传统的BSM方法使用一个最佳选择套期保值策略。
选择使用Black-Scholes-Merton模型建模
Black-Scholes-Merton (BSM)模型,获得其创造者诺贝尔经济学奖1997年,提供了一个建模框架和分析金融衍生品定价或选项。期权是金融工具,其价值来自特定的标的资产。的概念动态对冲是BSM模型的基础。动态对冲的想法,通过不断地买卖股票在相关的基础资产,可以对冲风险的衍生工具的风险为零。这种“风险中性”定价框架获得定价公式用于许多不同的金融工具。
最简单的欧洲金融衍生品是一个看涨期权,为买方提供了合适的,但不是义务,购买标的资产在先前指定的值(价)在先前指定的时间(成熟)。
您可以使用一个BSM模型价格欧洲看涨期权。BSM模型使得简化的假设如下:
标的资产的行为被定义为几何布朗运动(GBM)。
不存在交易成本。
波动率是恒定的。
BSM动态对冲策略也被称为“delta-hedging”后的数量δ,这是选择的敏感性对标的资产。在一个环境,满足前面所述的BSM的假设,使用delta-hedging策略是最优的套期保值方法的选择。然而,众所周知,在一个环境与交易成本、BSM模型的使用会导致低效的对冲策略。这个例子的目的是利用强化学习工具箱™学习策略优于BSM套期保值策略,在交易成本的存在。
强化学习(RL)的目标是培养一个代理在未知环境中完成一个任务。代理接收来自环境的观察和奖励和发送操作环境。的回报是衡量成功的一个动作是对完成任务的目标。
代理包含两个组件:一个策略和学习算法。
政策是一个映射,选择行为的基础上,从环境中观察。通常,政策和可调参数是一个函数的估计值,如深层神经网络。
学习算法不断更新政策参数的基础上操作,观察,和奖励。学习算法的目标是找到一个最优策略,最大化的累积奖励期间收到的任务。
换句话说,强化学习涉及到一个代理通过反复试错学习最优行为与环境的相互作用而无需人工干预。强化学习的更多信息,请参阅强化学习是什么?(强化学习工具箱)。
曹(2描述了强化学习的设置:
国家在时间吗 。
的行动吗 。
得到的奖励是 。
强化学习的目的是最大化预期未来的回报。强化学习在这个金融应用程序,预期回报最大化学习delta-hedging策略作为最佳欧洲看涨期权套期保值方法。
这个例子之前,曹中概述的框架(2]。具体地说,会计损益(损益表)配方,纸是用来设置强化学习问题,深决定性策略梯度(DDPG)代理使用。这个例子不完全复制的方法(2因为曹等。艾尔。推荐一个q学习方法与两个独立Q-functions(一个用于套期保值的成本和一个预期的平方的对冲成本),但是这个示例使用一个简化的回报函数。
定义训练参数
接下来,指定一个平价期权到期三个月对冲。为简单起见,利息和股息收益率将0。
%选择参数罢工= 100;成熟= 21 * 3/250;%资产参数SpotPrice = 100;ExpVol = 2;ExpReturn = . 05;%仿真参数rfRate = 0;dT = 1/250;nSteps =成熟度/ dT;nTrials = 5000;% Transacation成本和代价函数的参数c = 1.5;kappa = . 01;InitPosition = 0;%设置随机发生器再现性的种子。提高(3)
定义环境
在本节中,操作和观察参数,actInfo和obsInfo。代理行为是当前h边缘价值之间0和1。代理有三个变量观察:
Moneyness(比现货价格的执行价格)
到期时间
位置或数量的标的资产
ObservationInfo = rlNumericSpec (1 [3],“LowerLimit”0,“UpperLimit”,10成熟度1 ');ObservationInfo。Name =“对冲状态”;ObservationInfo。描述= [“Moneyness”,“TimeToMaturity”,“位置”];ActionInfo = rlNumericSpec ([1],“LowerLimit”0,“UpperLimit”1);ActionInfo。Name =“对冲”;
定义的奖励
从曹2),会计损益表配方和奖励(负成本)
+ ( - - - - - - )- - -
在哪里
最后一个奖励在最后时间步则停业的对冲
在这个实现中,奖励( )被惩罚,奖励的平方乘以一个常数来惩罚大幅波动的价值对冲位置:
中定义的奖励stepFcn也就是模拟的每一步。
env = rlFunctionEnv (ObservationInfo ActionInfo,…@(对冲,LoggedSignals) stepFcn(对冲,LoggedSignals rfRate, ExpVol, dT,罢工,ExpReturn, c,卡巴),…@ ()resetFcn (SpotPrice /罢工,成熟,InitPosition));obsInfo = getObservationInfo (env);actInfo = getActionInfo (env);
为RL创建环境接口代理
创建DDPG代理使用rlDDPGAgent(强化学习工具箱)。虽然可以创建自定义的演员和评论家网络,这个示例使用默认的网络。
initOpts = rlAgentInitializationOptions (“NumHiddenUnit”,64);criticOpts = rlOptimizerOptions (“LearnRate”1的军医);actorOpts = rlOptimizerOptions (“LearnRate”1的军医);agentOptions = rlDDPGAgentOptions (…“ActorOptimizerOptions”actorOpts,…“CriticOptimizerOptions”criticOpts,…“DiscountFactor”.9995,…“TargetSmoothFactor”5的军医);代理= rlDDPGAgent (obsInfo actInfo、initOpts agentOptions);
可视化的演员和评论家网络
可视化的演员和评论家网络使用深层网络设计师。
deepNetworkDesigner (layerGraph (getModel (getActor(代理))))
火车代理
火车代理使用火车(强化学习工具箱)函数。
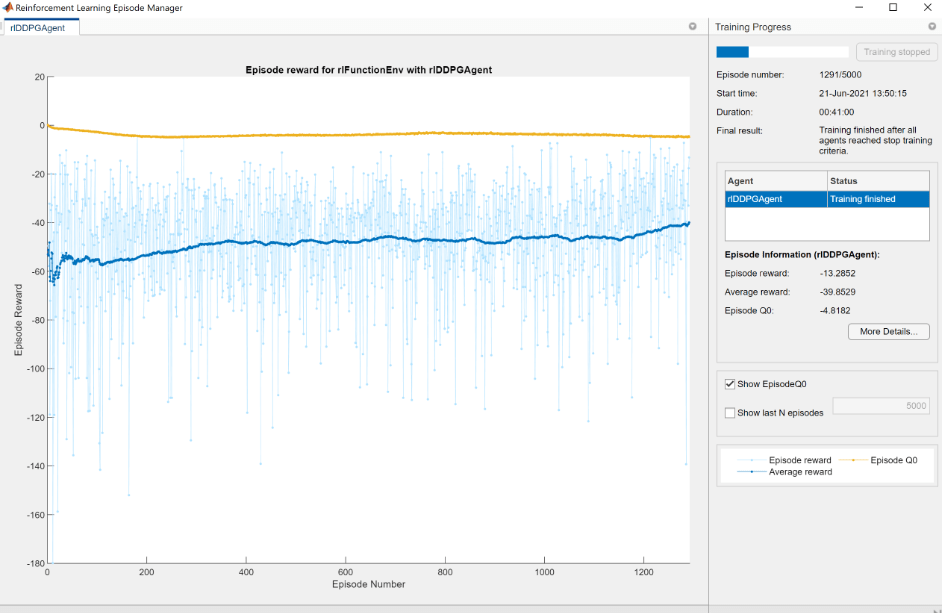
trainOpts = rlTrainingOptions (…“MaxEpisodes”nTrials,…“MaxStepsPerEpisode”nSteps,…“详细”假的,…“ScoreAveragingWindowLength”,200,…“StopTrainingCriteria”,“AverageReward”,…“StopTrainingValue”,-40,…“StopOnError”,“上”,…“UseParallel”、假);doTraining = false;如果doTraining%培训代理。trainingStats =火车(代理,env, trainOpts);其他的%加载pretrained代理的例子。负载(“DeepHedgingDDPG.mat”,“代理”)结束
为了避免等待培训、负载pretrained网络通过设置doTraining旗帜假。如果你设置doTraining来真正的,强化学习集管理器显示培训进展。
验证代理
使用金融工具箱™函数blsdelta和blsprice传统方式贵司作为欧洲看涨期权的价格。当RL方法比较传统的方法,结果发现类似的曹2在展览4]。这个例子演示了RL方法显著降低套期保值成本。
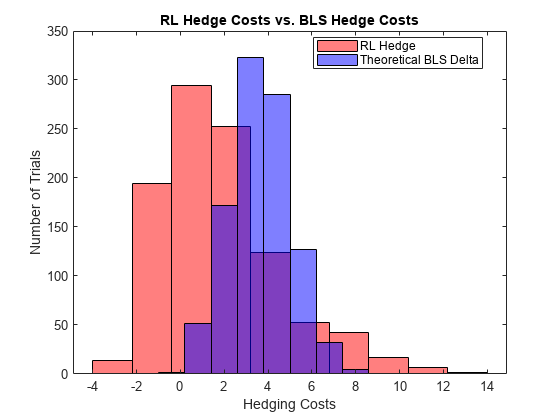
%仿真参数nTrials = 1000;policy_BSM = @ (TTM先生,Pos) blsdelta (rfRate先生,1日,马克斯(TTM, eps) ExpVol);policy_RL = @ (TTM先生,Pos) arrayfun (@ (TTM先生,Pos) cell2mat (getAction(代理,(TTM Pos先生))),先生,TTM, Pos);OptionPrice = blsprice (SpotPrice,罢工,rfRate,成熟,ExpVol);Costs_BSM = computeCosts (policy_BSM nTrials、nSteps SpotPrice,罢工,成熟,rfRate, ExpVol, InitPosition, dT, ExpReturn,卡巴);Costs_RL = computeCosts (policy_RL nTrials、nSteps SpotPrice,罢工,成熟,rfRate, ExpVol, InitPosition, dT, ExpReturn,卡巴);HedgeComp =表(100 *(意思是(Costs_BSM)性病(Costs_BSM)]的/ OptionPrice,…100 *(意思是(Costs_RL)性病(Costs_RL)]的/ OptionPrice,…“RowNames”,(期权价格的“对冲成本平均(%)”,“STD对冲成本期权价格(%)”),…“VariableNames”,(“BSM”,“RL”]);disp (HedgeComp)
BSM RL交平均对冲成本期权价格(%)91.259 - 47.022性病对冲成本期权价格(%)35.712 - 68.119
下面的柱状图显示了不同的套期保值成本这两种方法。RL方法表现更好,但方差比BSM方法。本例中的RL appraoch可能受益于这两个曹Q-function方法(2讨论并实现了。
图numBins = 10;直方图(-Costs_RL numBins,“FaceColor”,“r”,“FaceAlpha”5)举行在直方图(-Costs_BSM numBins,“FaceColor”,“b”,“FaceAlpha”5)包含(“对冲成本”)ylabel (试验的数量)标题(“RL对冲成本和劳工统计局对冲成本”)传说(“RL对冲”,“理论BLS三角洲”,“位置”,“最佳”)
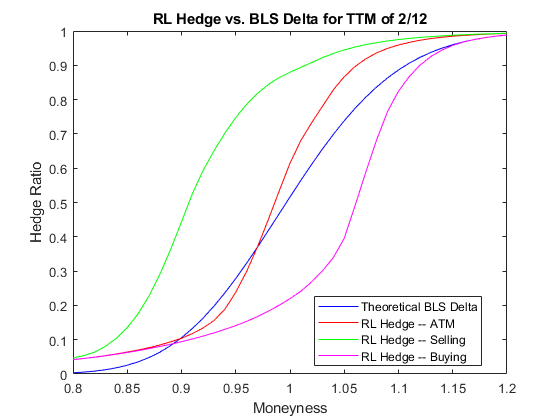
阴谋的对冲比率对moneyness显示BSM和RL方法之间的差异。如前所述在曹2),在交易成本的存在,代理了解到“当δ对冲将需要购买股票,这往往是最佳的一个交易员underhedged相对于三角洲。同样的,当δ对冲将需要出售股票,这往往是最佳的一个交易员over-hedged相对于三角洲”。
policy_RL_mR = @ (TTM先生,Pos) cell2mat (getAction(代理,(TTM Pos先生)'));mRange = (。8: .01:1.2) ';图t_plot = 2/12;情节(mRange blsdelta (mRange 1 rfRate、t_plot ExpVol),“b”)举行在情节(mRange arrayfun (@ (mR) policy_RL_mR(先生、t_plot blsdelta(先生,1 rfRate、t_plot ExpVol)), mRange),“r”)情节(mRange arrayfun (@ (mR) policy_RL_mR(先生、t_plot blsdelta(+ 1。先生,1 rfRate t_plot, ExpVol)), mRange),‘g’)情节(mRange arrayfun (@ (mR) policy_RL_mR(先生、t_plot blsdelta(约先生1 rfRate t_plot, ExpVol)), mRange),“米”)传说(“理论BLS三角洲”,“RL对冲——ATM”,“RL对冲——销售”,“RL对冲——购买”,…“位置”,“最佳”)包含(“Moneyness”)ylabel (“对冲比率”)标题(的RL对冲与劳工统计局三角洲TTM 2/12的)
引用
[1]比勒H。,L. Gonon, J. Teichmann, and B. Wood. "Deep hedging."定量金融学。8号卷。19日,2019年,页1271 - 91。
[2]曹J。,J. Chen, J. Hull, and Z. Poulos. "Deep Hedging of Derivatives Using Reinforcement Learning."财务数据的科学杂志上。3卷,1号,2021,pp。10-27。
[3]Halperin我。“QLBS: Q-learner在布莱克-斯科尔斯(默顿)的世界。”《华尔街日报》的衍生品。1号卷28日,2020年,页99 - 122。
[4]柯姆煤期票和g·里特。“动态复制和套期保值:强化学习方法。”财务数据的科学杂志上。1卷,1号,2019年,页159 - 71。
本地函数
函数[InitialObservation, LoggedSignals] = resetFcn (Moneyness、TimeToMaturity InitPosition)%重置功能重置在每集的开始。LoggedSignals。年代tate = [Moneyness TimeToMaturity InitPosition]'; InitialObservation = LoggedSignals.State;结束函数[NextObs,奖励,结束,LoggedSignals] = stepFcn (Position_next LoggedSignals, r,卷,dT, X,μ,c,卡巴)%的阶跃函数来评估每一步。Moneyness_prev = LoggedSignals.State (1);TTM_prev = LoggedSignals.State (2);Position_prev = LoggedSignals.State (3);S_prev = Moneyness_prev * X;% GBM运动S_next = S_prev *((1 +μ* dT) + (randn *卷)。* sqrt (dT));TTM_next = max (0, TTM_prev - dT);结束= TTM_next <每股收益;stepReward = (S_next - S_prev) * Position_prev - abs (Position_next - Position_prev) * S_next *κ-…blsprice (S_next X r, TTM_next,卷)+ blsprice (S_prev X r, TTM_prev,卷);如果结束stepReward = stepReward - Position_next * S_next * kappa;结束奖励= stepReward - c * stepReward。^ 2;LoggedSignals。年代tate = [S_next/X;TTM_next;Position_next]; NextObs = LoggedSignals.State;结束函数perCosts = computeCosts(政策、nTrials nSteps SpotPrice,罢工,T, r, ExpVol, InitPos, dT,μ,卡巴)% Helper函数来计算成本对于任何对冲的方法。rng (0) simOBJ =“绿带运动”(μ,ExpVol,“StartState”,SpotPrice);[simPaths, simTimes] =模拟(simOBJ nSteps,“nTrials”nTrials,“deltaTime”,dT);simPaths =挤压(simPaths);结果= 0 (nSteps nTrials);Position_prev = InitPos;:Position_next =政策(simPaths(1) /罢工,T * (1, nTrials), InitPos *的(nTrials));为timeidx = 2: nSteps + 1奖赏(timeidx-1:) = (simPaths (timeidx:) - simPaths (timeidx-1,:))。* Position_prev -…abs (Position_next - Position_prev)。* simPaths (timeidx:) * k -…blsprice (simPaths (timeidx:),罢工,r,马克斯(0,T - simTimes (timeidx)), ExpVol) +…blsprice (simPaths (timeidx-1:),罢工,r, T - simTimes (timeidx-1) ExpVol);如果timeidx = = nSteps + 1奖赏(timeidx-1:) =效益(timeidx-1:) - Position_next。* simPaths (timeidx,:,:) * kappa;其他的Position_prev = Position_next;Position_next =政策(simPaths (timeidx,:,:) /罢工,(T - simTimes (timeidx)。* (1, nTrials), Position_prev);结束结束perCosts =总和(效益);结束
另请参阅
blsprice|blsdelta|rlDDPGAgent(强化学习工具箱)