深入学习使用贝叶斯优化
此示例显示如何将贝叶斯优化应用于深度学习,并找到卷积神经网络的最佳网络超参数和培训选项。
要训练深层神经网络,你必须指定的神经网络结构,以及训练算法的选择。选择和调整这些超参数可能是困难和需要时间。贝叶斯优化是非常适合于优化分类和回归模型的超参数的算法。您可以使用贝叶斯算法优化是不可微,不连续的,且耗时的评价功能。该算法在内部维护目标函数的高斯过程模型,并利用目标函数的评估来训练这种模式。
此示例显示了如何:
下载并准备用于网络训练的CIFAR-10数据集。该数据集是测试图像分类模型使用最广泛的数据集之一。
使用贝叶斯优化指定变量以优化。这些变量是培训算法的选项,以及网络架构本身的参数。
定义目标函数,它将优化变量的值作为输入,指定网络架构和培训选项,列车并验证网络,并将培训的网络保存到磁盘。目标函数在此脚本的末尾定义。
通过最小化验证集上的分类错误来执行贝叶斯优化。
从磁盘加载最好的网络,并在测试集中对其进行评估。
作为一种替代方法,你可以使用贝叶斯优化来找到最优的训练选项实验经理。有关更多信息,请参阅通过使用贝叶斯优化调整实验超参数。
准备数据
下载CiFar-10数据集[1]。该数据集包含60,000个图像,每个图像具有32×32和三种颜色通道(RGB)。整个数据集的大小为175 MB。根据您的Internet连接,下载过程可能需要一些时间。
datadir = tempdir;downloadcardata(datadir);
将CIFAR-10数据设置为培训图像和标签,以及测试图像和标签。要启用网络验证,请使用5000个测试图像进行验证。
[xtrain,ytrain,xtest,ytest] = loadcifardata(Datadir);IDX = RANDPERM(NUMER(YTEST),5000);xvalidation = xtest(:,::,idx);xtest(::::,idx)= [];yvalidation = ytest(Idx);ytest(idx)= [];
您可以使用以下代码显示培训图像的样本。
数字;IDX = randperm(numel(YTrain),20);为了I = 1:numel(idx) subplot(4,5, I);imshow (XTrain (:,:,:, idx(我)));结尾
选择优化变量
选择要使用贝叶斯优化优化的变量,并指定要搜索的范围。此外,还指定变量是否为整数以及是否在对数空间中搜索间隔。优化以下变量:
网络部分的深度。该参数控制网络的深度。这个网络有三个部分,每个部分都有
切段相同的卷积层。所以卷积层的总数是3 *部分。脚本后面的目标函数采用每层成比例的卷积滤波器数量1 / SQRT(SectionDepth)。结果,对于不同的部分深度,每个迭代的参数和所需计算量大致相同。初始学习率。最好的学习率可以取决于您的数据以及您正在培训的网络。
随机梯度下降势头。动量通过使用当前更新包含与先前迭代中的更新成比例的贡献,为参数更新添加惯性。这导致更平滑的参数更新和随机梯度下降所固有的噪声的降低。
L2正规化的力量。使用正规化来防止过拟合。搜索正则化强度的空间,找到一个好的值。数据增强和批处理归一化也有助于网络的正则化。
Optimvars = [优化不变('sectiondepth',[1 3],“类型”那'整数')optimizableVariable('InitialLearnRate',[1E-2 1],“转换”那'日志')optimizableVariable('势头',[0.8 0.98])优化可变('L2Regularization',[1E-10 1E-2],“转换”那'日志')];
执行优化贝叶斯
对于贝叶斯优化创建目标函数,利用训练和验证数据作为输入。目标函数训练卷积神经网络和回报的验证集的分类错误。此功能在这个脚本的最后确定。因为bayesopt使用验证集的错误率选择最佳模型,可以在验证集上的最终网络过度填写。然后在独立的测试集上测试最终选择的模型以估计泛化误差。
objfcn = makeobjfcn(xtrain,ytrain,xvalidation,yvalidation);
通过最小化验证集上的分类错误来执行贝叶斯优化。指定总优化时间(以秒为单位)。为了最好地利用贝叶斯优化的力量,您应该执行至少30个目标函数评估。要在多个gpu上并行训练网络,请设置'UseParallel'值真的。如果您有一个GPU并设置'UseParallel'值真的,那么所有工作人员都共享该GPU,而您没有获得培训加速,并增加GPU耗尽内存的机会。
每个网络完成培训后,bayesopt将结果打印到命令窗口。这bayesopt函数然后返回文件名BayesObject。用rDataTrace。目标函数将培训的网络保存到磁盘并返回文件名bayesopt。
BayesObject = Bayesopt(Objfcn,Optimvars,......'MAXTIME',14 * 60 * 60,......“IsObjectiveDeterministic”,错误的,......'UseParallel',错误的);
| =================================================================================================================================== ||ITER |EVAL |目的|目的|BestSoFar |BestSoFar |SectionDepth |InitialLearn- | Momentum | L2Regulariza-| | | result | | runtime | (observed) | (estim.) | | Rate | | tion | |===================================================================================================================================| | 1 | Best | 0.197 | 955.69 | 0.197 | 0.197 | 3 | 0.61856 | 0.80624 | 0.00035179 |
| 2 | Best | 0.1918 | 790.38 | 0.1918 | 0.19293 | 2 | 0.074118 | 0.91031 | 2.7229e-09 |
|3 |接受|0.2438 |660.29 |0.1918 |0.19344 |1 |0.051153 |0.90911 | 0.00043113 |
|4 |接受|0.208 |672.81 |0.1918 |0.1918 |1 |0.70138 |0.81923 | 3.7783e-08 |
|5 |最佳|0.1792 |844.07 |0.1792 |0.17921 |2 |0.65156 |0.93783 | 3.3663e-10 |
|6 |最佳|0.1776 |851.49 |0.1776 |0.17759 |2 |0.23619 |0.91932 | 1.0007e-10 |
| 7 |接受| 0.2232 | 883.5 | 0.1776 | 0.17759 | 2 | 0.011147 | 0.91526 | 0.0099842 |
|8 |接受|0.2508 |822.65 |0.1776 |0.17762 |1 |0.023919 |0.91048 | 1.0002e-10 |
|9 |接受|0.1974 |1947.6 |0.1776 |0.17761 |3 |0.010017 |0.97683 | 5.4603e-10 |
|10 |最佳|0.176 |1938.4 |0.176 |0.17608 |2 |0.3526 |0.82381 | 1.4244e-07 |
|11 |接受|0.1914 |2874.4 |0.176 |0.17608 |3 |0.079847 |0.86801 | 9.7335e-07 |
|12 |接受|0.181 |2578 |0.176 |0.17809 |2 |0.35141 |0.80202 | 4.5634e-08 |
|13 |接受|0.1838 |2410.8 |0.176 |0.17946 |2 |0.39508 |0.95968 | 9.3856e-06 |
|14 |接受|0.1786 |2490.6 |0.176 |0.17737 |2 |0.44857 |0.91827 | 1.0939e-10 |
|15 |接受|0.1776 |2668 |0.176 |0.17751 |2 |0.95793 |0.85503 | 1.0222e-05 |
| 16 |接受| 0.1824 | 3059.8 | 0.176 | 0.17812 | 2 | 0.41142 | 0.86931 | 1.447e-06 |
|17 |接受|0.1894 |3091.5 |0.176 |0.17982 |2 |0.97051 |0.80284 | 1.5836e-10 |
|18 |接受|0.217 |2794.5 |0.176 |0.17989 |1 |0.2464 |0.84428 | 4.4938e-06 |
|19 |接受|0.2358 |4054.2 |0.176 |0.17601 |3 |0.22843 |0.9454 | 0.00098248 |
|20 |接受|0.2216 |4411.7 |0.176 |0.17601 |3 |0.010847 |0.82288 | 2.4756e-08 |
| =================================================================================================================================== ||ITER |EVAL |目的|目的|BestSoFar |BestSoFar |SectionDepth |InitialLearn- | Momentum | L2Regulariza-| | | result | | runtime | (observed) | (estim.) | | Rate | | tion | |===================================================================================================================================| | 21 | Accept | 0.2038 | 3906.4 | 0.176 | 0.17601 | 2 | 0.09885 | 0.81541 | 0.0021184 |
|22 |接受|0.2492 |4103.4 |0.176 |0.17601 |2 |0.52313 |0.83139 | 0.0016269 |
|23 |接受|0.1814 |4240.5 |0.176 |0.17601 |2 |0.29506 |0.84061 | 6.0203e-10 |

__________________________________________________________ 优化完成。MaxTime达到50400秒。总函数计算:23总运行时间:53088.5123秒总目标函数计算时间:53050.7026最佳观测可行点:SectionDepth InitialLearnRate Momentum L2Regularization ____________ ________________ ________ ________________ 2 0.3526 0.82381 1.4244e-07 Observed objective function value = 0.176 Estimated objective function value = 0.17601 function evaluation time = 1938.4483 Best Estimated feasible point (according to models):SectionDepth InitialLearnRate Momentum L2Regularization ____________ ________________ ________ ________________ 2 0.3526 0.82381 1.4244e-07 Estimated objective function value = 0.17601 Estimated function evaluation time = 1898.2641
评估最终的网络
加载优化中发现的最佳网络及其验证精度。
bestIdx = BayesObject.IndexOfMinimumTrace(端);文件名= BayesObject.UserDataTrace {bestIdx};savedStruct =负载(文件名);valError = savedStruct.valError
Valerror = 0.1760.
预测测试集的标签并计算测试误差。将测试中的每个图像的分类视为具有一定的成功概率的独立事件,这意味着错误分类的图像的数量遵循二项式分布。使用它来计算标准错误(testerrse.)和近似95%的置信区间(testerror95ci.)泛化误差率。这种方法通常被称为沃尔德方法。bayesopt使用验证集确定最佳网络,而不将网络公开给测试集。这样,测试错误就有可能高于验证错误。
(YPredicted,聚合氯化铝)= (savedStruct.trainedNet XTest)进行分类;testror = 1 - mean(YPredicted == YTest)
testerror = 0.1910
元=元素个数(欧美);testErrorSE =√testError * (1-testError) / nt);testror95ci = [testror - 1.96* testrorse, testror + 1.96* testrorse]
testerror95ci =1×20.1801 0.2019
积为测试数据的混淆矩阵。显示的精度和通过使用列和行摘要召回为每个类。
数字('单位'那“规范化”那'位置',[0.2 0.2 0.4 0.4]);厘米= confusionchart(欧美,YPredicted);厘米。Title =“混淆矩阵测试数据”;cm.columnsummary =“列归一化”;cm.RowSummary ='行标准化';

您可以使用以下代码与其预测的类和这些类的概率一起显示一些测试图像。
图IDX = randperm(numel(YTest),9);为了i = 1:numel(idx)子图(3,3,i)imshow(xtest(:,:,:,iDx(i))));prob = num2str(100 * max(probs(idx(i),:)),3);predclass = char(ypreedicted(idx(i)));标签= [predcrass,',',概率,“%”];标题(标签)结尾
优化目标函数
定义目标函数以进行优化。此函数执行以下步骤:
将优化变量的值作为输入。
bayesopt使用每个列名称等于变量名称的表中的优化变量的当前值调用目标函数。例如,网络部分深度的当前值是optVars。切段。定义网络架构和培训选项。
列车并验证网络。
将培训的网络,验证错误和培训选项保存到磁盘上。
返回验证错误并保存网络的文件名。
功能objfcn = makeobjfcn(xtrain,ytrain,xvalidation,yvalidation)objfcn = @valerrorfun;功能[valerror,cons,filename] = valerrorfun(Optvars)
定义卷积神经网络结构。
添加填充到卷积层,使得所述空间输出大小始终是一样的输入大小。
每次使用MAX池层都将空间尺寸缩小到两个倍数,将过滤器数量增加了两倍。这样做确保每个卷积层所需的计算量大致相同。
选择与之成比例的过滤器数量
1 / SQRT(SectionDepth),因此不同深度的网络具有大致相同的参数数量,并且需要大约相同的计算量的每次迭代量。增加网络参数的数量和整体网络灵活性,增加numf.。要培训更深入的网络,更改范围切段多变的。用
Convblock(过滤,numfilters,numconvlayers)创建一个块numConvLayers卷积层,每个具有指定的filterSize和numFilters滤波器,并且每个随后分批正常化层和RELU层。这convBlock函数在此示例的末尾定义。
图像_ [32 32 3];numclasses = numel(唯一(ytrain));numf = round(16 / sqrt(Optvars.sectionDepth));图层= [imageInputLayer(图像化)%这些卷积的空间输入和输出尺寸%层是32×32,和下面的最大池层%将其降低至16×16。Convblock(3,Numf,OptVars.sectionDepth)MaxPooling2Dlayer(3,'走吧'2,“填充”那'相同的')%这些卷积的空间输入和输出尺寸%图层为16-by-16,以及以下最大池池层%将它减少为8 × 8。Convblock(3,2 * numf,Optvars.sectionDepth)MaxPooling2Dlayer(3,'走吧'2,“填充”那'相同的')%这些卷积的空间输入和输出尺寸%层是8 × 8的。全球平均池层平均值%超过8×8的输入,给出了大小的输出% 1-by-1-by-4 * initialNumFilters。全球平均水平%池层,最终分类输出仅限对存在的每个特征的总量敏感%输入图像,但对空间位置不敏感% 特征。convBlock(3,4- * numF,optVars.SectionDepth)averagePooling2dLayer(8)%添加完全连接的图层和最终软邮件和%分类层。全连接列(numcrasses)softmaxlayer分类层];
指定网络训练选项。优化初始学习率、SGD动量和L2正则化强度。
指定验证数据并选择'验证职业'价值这样的价值Trainnetwork.验证网络每时期一次。训练对于固定数量的历元的最后时期期间通过降低了10倍的学习速率。这降低了参数更新的噪声,并允许网络参数定下来接近最小的损失函数的。
minibatchsize = 256;验证频率=地板(Numel(YTrain)/小型匹配);选项=培训选项(“个”那......'InitialLearnRate',optVars.InitialLearnRate,......'势头', optVars。动力,......'maxepochs'60,......“LearnRateSchedule”那'分段'那......'学习ropperiod',40,......'学习ropfactor',0.1%,......'minibatchsize'miniBatchSize,......'L2Regularization', optVars。L2Regularization,......“洗牌”那'每个时代'那......“详细”,错误的,......'plots'那'培训 - 进步'那......'vightationdata',{xvalidation,yvalidation},......'验证职业',验证职权;
使用数据增强沿垂直轴随机翻转训练图像,并随机将其水平和垂直平移到4个像素。数据增强有助于防止网络过度拟合和记忆训练图像的确切细节。
PIXELRANGE = [-4 4];imageaugmenter = imagedataAugmenter(......'randxreflection',真的,......“RandXTranslation”,pixelrange,......'randytranslation', pixelRange);数据源= augmentedImageDatastore(图象尺寸、XTrain YTrain,'DataAugmentation',imageAugmenter);
训练网络和训练中绘制训练进度。关闭训练结束后,所有培训地块。
trousainnet = trainnetwork(DataSource,图层,选项);关闭(findall(groot,“标签”那“NNET_CNN_TRAININGPLOT_UIFIGURE”)))
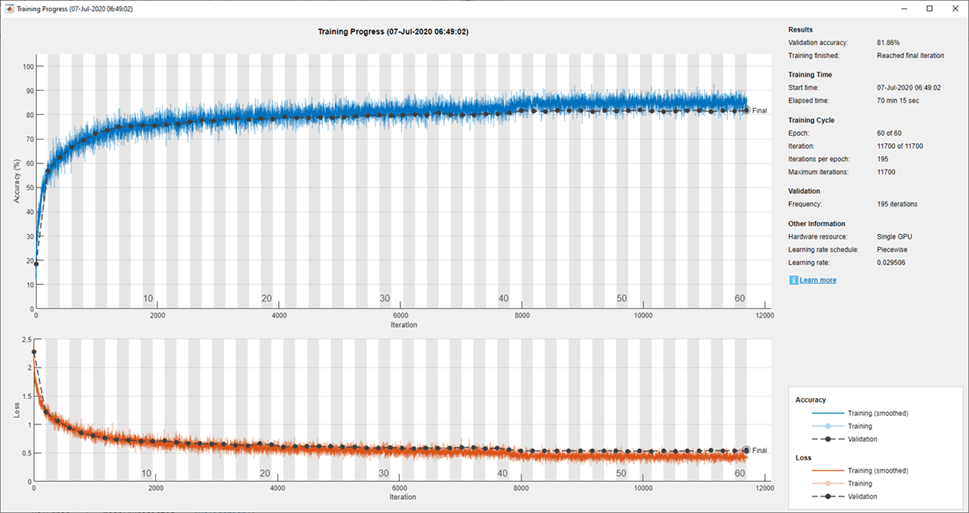
评价对验证集训练网络,计算所预测的图像标签,并计算所述验证数据的错误率。
YPredicted =分类(trainedNet,XValidation);valError = 1 - 平均(YPredicted == YValidation);
创建包含验证错误的文件名,并将网络,验证错误和培训选项保存到磁盘。目标函数返回文档名称作为输出参数,并bayesopt返回所有文件名BayesObject。用rDataTrace。其他必需的输出参数缺点指定变量之间的约束。没有可变约束。
filename = num2str(valerror)+“。垫”;保存(文件名,'trousahynet'那'瓦尔罗'那'选项') cons = [];结尾结尾
这convBlock函数创建的块numConvLayers卷积层,每个具有指定的filterSize和numFilters滤波器,并且每个随后分批正常化层和RELU层。
功能图层= Convblock(过滤,NumFilters,NumConvlayers)图层= [Convolution2Dlayer(Filtersize,NumFilters,“填充”那'相同的')BatchnormalizationLayer Ruilulayer];图层= Repmat(图层,NumConvlayers,1);结尾
参考
[1] Krizhevsky,Alex。“从微小图像学习多层特征。”(2009)。https://www.cs.toronto.edu/~kriz/learning-features-2009-tra.pdf.
也可以看看
实验经理|培训选项|Trainnetwork.|bayesopt(统计和机器学习工具箱)
相关话题
您还可以从以下列表中选择一个网站:
