使用自动编码器生成文本
这个例子展示了如何使用自动编码器生成文本数据。
自动编码器是一种深度学习网络,经过训练可以复制其输入。自动编码器由两个较小的网络组成:编码器和解码器。编码器将输入数据映射到某个潜在空间中的特征向量。解码器利用这个潜在空间中的向量重构数据。
培训过程没有监督。换句话说,模型不需要标记数据。要生成文本,可以使用解码器从任意输入重新构造文本。
这个例子训练一个自动编码器来生成文本。编码器使用单词嵌入和LSTM操作将输入文本映射到潜在向量。解码器使用LSTM操作和相同的嵌入从潜在向量重建文本。
加载数据
该文件sonnets.txt在一个文本文件中包含了莎士比亚所有的十四行诗。
从文件中阅读莎士比亚十四行诗的数据“sonnets.txt”.
文件名=“sonnets.txt”;textData = fileread(文件名);
十四行诗用两个空格缩进。删除缩进使用取代并将文本分割为单独的行分裂函数。删除头九个元素和短十四行诗标题。
textData = replace(textData,”“,"");textData = split(textData,换行符);textData(1:9) = [];textData(strlength(textData)<5) = [];
准备数据
创建一个对文本数据进行标记和预处理的函数。这个函数preprocessText,在示例末尾列出,执行以下步骤:
分别用指定的开始和停止标记在每个输入字符串的前面和后面。
使用标记化文本
tokenizedDocument.
预处理文本数据并指定开始和停止标记“<开始>”而且“<停止>”,分别。
startToken =“<开始>”;stopToken =“<停止>”;documents = preprocessText(textData,startToken,stopToken);
从标记化的文档创建一个单词编码对象。
enc = wordEncoding(文档);
在训练深度学习模型时,输入数据必须是包含固定长度序列的数字数组。因为文档的长度不同,所以必须用填充值填充较短的序列。
重新创建单词编码以包含填充令牌并确定该令牌的索引。
paddingToken =“<垫>”;newVocabulary = [en . vocabulary paddingToken];enc = wordEncoding(新词汇);paddingIdx = word2ind(enc,paddingToken)
paddingIdx = 3595
初始化模型参数
初始化以下模型的参数。

在这里, 为序列长度, 是输入序列的词索引,和 是重构序列。
编码器通过使用嵌入将输入转换为单词向量序列,将单词向量序列输入到LSTM操作中,并对LSTM输出的最后一个时间步应用完全连接操作,从而将单词索引序列映射到潜在向量。解码器使用初始化编码器输出的LSTM重构输入。对于每个时间步,解码器预测下一个时间步,并使用输出进行下一个时间步预测。编码器和解码器都使用相同的嵌入。
指定参数的尺寸。
embeddingDimension = 100;numHiddenUnits = 150;latentDimension = 75;vocabularySize = en . numwords;
为参数创建一个结构。
参数= struct;
初始化嵌入的权值使用高斯函数initializeGaussian函数,该函数作为支持文件附加到本示例中。万博1manbetx指定平均值为0,标准差为0.01。要了解更多,请参见高斯函数初始化.
Mu = 0;σ = 0.01;parameters.emb.Weights = initializeGaussian([embeddingDimension vocabularySize],mu,sigma);
初始化编码器LSTM操作的可学习参数:
sz = [4*numHiddenUnits embeddingDimension];numOut = 4*numHiddenUnits;numIn = embeddingDimension;parameters.lstmEncoder.InputWeights = initializeGlorot(sz,numOut,numIn);parameters.lstmEncoder.RecurrentWeights = initializeOrthogonal([4*numHiddenUnits numHiddenUnits]);parameters.lstmEncoder.Bias = initializeUnitForgetGate(numHiddenUnits);
初始化编码器完全连接操作的可学习参数:
使用gloot初始化器初始化权值。
方法初始化带有零的偏置
initializeZeros函数,该函数作为支持文件附加到本示例中。万博1manbetx要了解更多,请参见零初始化.
sz = [latentDimension numHiddenUnits];numOut = latentDimension;numIn = numHiddenUnits;parameters.fcEncoder.Weights = initializeGlorot(sz,numOut,numIn);parameters. fcencoders . bias = initializeZeros([latentDimension 1]);
初始化解码器LSTM操作的可学习参数:
使用gloot初始化器初始化输入权重。
用正交初始化器初始化递归权值。
使用单元忘记门初始化器初始化偏置。
sz = [4*latentDimension embeddingDimension];numOut = 4*latentDimension;numIn = embeddingDimension;parameters.lstmDecoder.InputWeights = initializeGlorot(sz,numOut,numIn);parameters. lstmdecoders . recurrentweights = initializeOrthogonal([4*latentDimension]);parameters. lstmdecoders . bias = initializeZeros([4*latentDimension 1]);
初始化解码器全连接操作的可学习参数:
使用gloot初始化器初始化权值。
初始偏差为零。
sz = [vocabularySize latentDimension];numOut = vocabularySize;numIn = latentDimension;parameters.fcDecoder.Weights = initializeGlorot(sz,numOut,numIn);parameters. fcdecoer . bias = initializeZeros([vocabularySize 1]);
要了解关于权重初始化的更多信息,请参见初始化模型函数的可学习参数.
定义模型编码器函数
创建函数modelEncoder,列于编码器模型函数部分,该部分计算编码器模型的输出。的modelEncoder函数,取单词索引、模型参数和序列长度作为输入序列,并返回相应的潜在特征向量。要了解关于定义模型编码器函数的更多信息,请参见定义文本编码器模型函数.
定义模型解码器函数
创建函数modelDecoder,列于解码器模型函数部分,该部分计算解码器模型的输出。的modelDecoder函数,取单词索引、模型参数和序列长度作为输入序列,并返回相应的潜在特征向量。要了解关于定义模型解码器函数的更多信息,请参见定义文本解码器模型函数.
定义模型梯度函数
的modelGradients函数中列出的模型梯度函数示例部分,以模型可学习参数为输入,输入数据dlX,和用于屏蔽的序列长度向量,并返回损失相对于可学习参数和相应损失的梯度。要了解关于定义模型梯度函数的更多信息,请参见定义自定义训练循环的模型梯度函数.
指定培训选项
指定培训选项。
训练100个周期,小批次大小为128。
miniBatchSize = 128;numEpochs = 100;
以0.01的学习率进行训练。
learnRate = 0.01;
以图表形式展示训练进度。
情节=“训练进步”;
如果有GPU,请使用GPU进行训练。使用GPU需要并行计算工具箱™和支持的GPU设备。万博1manbetx有关支持的设备的信息,请参见万博1manbetxGPU支万博1manbetx持按版本划分(并行计算工具箱).
executionEnvironment =“汽车”;
列车网络的
使用自定义训练循环训练网络。
初始化Adam优化器的参数。
trailingAvg = [];trailingAvgSq = [];
初始化训练进度图。创建一条动画线,绘制对应迭代的损失。
如果情节= =“训练进步”图lineLossTrain = animatedline(“颜色”,[0.85 0.325 0.098]);包含(“迭代”) ylabel (“损失”) ylim([0 inf])网格在结束
训练模型。对于第一个纪元,洗牌数据并循环处理小批量数据。
对于每个小批次:
将文本数据转换为单词索引序列。
将数据转换为
dlarray.GPU训练时,将数据转换为
gpuArray对象。计算损耗和梯度。
方法更新可学习的参数
adamupdate函数。更新训练进度图。
跑步训练需要一些时间。
numObservations = numel(文档);numIterationsPerEpoch = floor(numObservations / miniBatchSize);迭代= 0;开始= tic;为纪元= 1:numEpochs%洗牌。idx = randperm(numObservations);文档=文档(idx);为i = 1:numIterationsPerEpoch迭代=迭代+ 1;读取小批。= (i-1)*miniBatchSize+1:i*miniBatchSize;documentsBatch = documents(idx);%转换为序列。X = doc2sequence(enc,documentsBatch,...“PaddingDirection”,“对”,...“PaddingValue”, paddingIdx);X = cat(1,X{:});%转换为dlarray。dlX = dlarray(X,“BTC”);如果在GPU上训练,那么将数据转换为GPU array。如果(executionEnvironment = =“汽车”&& canUseGPU) || executionEnvironment ==“图形”dlX = gpuArray(dlX);结束计算序列长度。sequenceLengths = doclth (documentsBatch);评估模型梯度。[gradients,loss] = dlfeval(@modelGradients, parameters, dlX, sequenceLengths);更新可学习参数。[parameters,trailingAvg,trailingAvgSq] = adamupdate(参数,gradient,...trailingAvg trailingAvgSq,迭代,learnRate);显示培训进度。如果情节= =“训练进步”D = duration(0,0,toc(开始),“格式”,“hh: mm: ss”);addpoints (lineLossTrain、迭代、双(收集(extractdata(损失))))标题(”时代:“+ epoch +,消失:"+字符串(D)结束结束结束
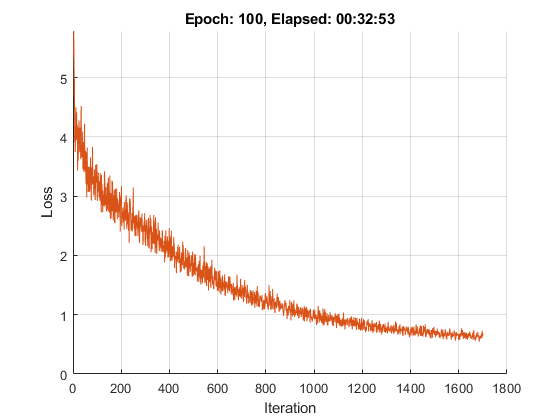
生成文本
通过初始化具有不同随机状态的解码器,使用闭环生成生成文本。闭环生成是指模型每次生成一个时间步数据,并使用前一个预测作为下一个预测的输入。
指定生成3个长度为16的序列。
numGenerations = 3;sequenceLength = 16;
创建随机值数组以初始化解码器状态。
dlZ = dlarray(randn(latentDimension,numGenerations),“CB”);
如果在GPU上预测,那么将数据转换为gpuArray.
如果(executionEnvironment = =“汽车”&& canUseGPU) || executionEnvironment ==“图形”dlZ = gpuArray(dlZ);结束
使用modelPredictions函数,在示例末尾列出。的modelPredictions函数在给定模型参数、解码器初始状态、最大序列长度、单词编码、开始标记和小批处理大小的情况下返回解码器的输出分数。
dlY = modeldecoderprediction (parameters,dlZ,sequenceLength,enc,startToken,miniBatchSize);
找出得分最高的单词索引。
[~,idx] = max(dlY,[],1);Idx =挤压(Idx);
将数值索引转换为单词并使用加入函数。
strGenerated = join(en . vocabulary (idx));
方法提取第一个停止令牌之前的文本extractBefore函数。为了防止在没有停止令牌时函数返回缺失,请在每个序列的末尾追加一个停止令牌。
strGenerated = extractBefore(strGenerated+stopToken,stopToken);
删除填充标记。
strGenerated = erase(strGenerated,paddingToken);
生成过程在每个预测之间引入空白字符,这意味着一些标点字符出现前后有不必要的空格。通过删除适当的标点符号前后的空格来重构生成的文本。
删除出现在指定标点符号字符之前的空格。
标点符号= [“。””、““”“)””:“”;““?”“啊!”];strGenerated = replace(strGenerated,”“+ punctuationCharacters punctuationCharacters);
删除出现在指定标点符号字符后的空格。
标点符号= [”(““”];strGenerated = replace(strGenerated,标点符号+”“, punctuationCharacters);
方法删除前导和尾随空白带函数并查看生成的文本。
strGenerated = strip(strGenerated)
strGenerated =3×1的字符串"爱是你的安息之光最好的错误表现在我面前看得更远" "就像在他弯曲的镰刀的罗盘来找。"“夏天的了?真理一旦被引导,就会被带走。”
编码器模型函数
的modelEncoder函数,以模型参数、词索引序列和序列长度为输入,并返回相应的潜在特征向量。
由于输入数据包含不同长度的填充序列,填充会对损失计算产生不利影响。对于LSTM操作,与其返回序列的最后一个时间步的输出(这可能对应于处理大量填充值后的LSTM状态),不如确定由sequenceLengths输入。
函数dlZ = modelEncoder(参数,dlX,sequenceLengths)%嵌入。weights = parameters.emb.Weights;dlZ = embedding(dlX,weights);% LSTM。inputWeights = parameters.lstmEncoder.InputWeights;recurrentWeights = parameters.lstmEncoder.RecurrentWeights;bias = parameters.lstmEncoder.Bias;numHiddenUnits = size(recurrentWeights,2);hiddenState = 0 (numHiddenUnits,1,“喜欢”dlX);cellState = 0 (numHiddenUnits,1,“喜欢”dlX);dlZ1 = lstm(dlZ,hiddenState,cellState,inputWeights,recurrentWeights,bias,“DataFormat”,“认知行为治疗”);带有屏蔽的输出模式'last'。miniBatchSize = size(dlZ1,2);dlZ = 0 (numHiddenUnits,miniBatchSize,“喜欢”dlZ1);为n = 1:miniBatchSize t = sequenceLengths(n);dlZ(:,n) = dlZ1(:,n,t);结束%完全连接。weights = parameters.fcEncoder.Weights;bias = parameters.fcEncoder.Bias;dlZ = fullconnect (dlZ,权重,偏差,“DataFormat”,“CB”);结束
解码器模型函数
的modelDecoder函数,以模型参数、词索引序列和网络状态为输入,返回解码后的序列。
因为lstm函数是有状态(当给定一个时间序列作为输入时,函数在每个时间步之间传播和更新状态)和嵌入而且fullyconnect函数在默认情况下是时间分布的(当给定一个时间序列作为输入时,函数独立地对每个时间步进行操作)modelDecoder函数支持序列和单时万博1manbetx间步输入。
函数[dlY,state] = modelDecoder(参数,dlX,state)%嵌入。weights = parameters.emb.Weights;dlX =嵌入(dlX,权重);% LSTM。inputWeights = parameters.lstmDecoder.InputWeights;recurrentWeights = parameters.lstmDecoder.RecurrentWeights;bias = parameters.lstmDecoder.Bias;hiddenState = state.HiddenState;cellState = state.CellState;[dlY,hiddenState,cellState] = lstm(dlX,hiddenState,cellState,...inputWeights recurrentWeights,偏见,“DataFormat”,“认知行为治疗”);状态。HiddenState = HiddenState;状态。CellState = CellState;%完全连接。weights = parameters.fcDecoder.Weights;bias = parameters.fcDecoder.Bias;d1 =完全连接(d1,权重,偏差,“DataFormat”,“认知行为治疗”);% Softmax。= softmax(dy,“DataFormat”,“认知行为治疗”);结束
模型梯度函数
的modelGradients以模型可学习参数、输入数据为输入的函数dlX,和用于屏蔽的序列长度向量,并返回损失相对于可学习参数和相应损失的梯度。
在计算掩模损失时,模型梯度函数采用maskedCrossEntropy损失函数,在示例的最后列出。为了训练解码器预测序列的下一个时间步,将目标指定为移动了一个时间步的输入序列。
要了解关于定义模型梯度函数的更多信息,请参见定义自定义训练循环的模型梯度函数.
函数[gradients, loss] = modelGradients(parameters,dlX,sequenceLengths)模型编码器。dlZ = modelEncoder(参数,dlX,sequenceLengths);初始化LSTM状态。State = struct;状态。HiddenState = dlZ;状态。CellState = 0 (size(dlZ),“喜欢”, dlZ);老师强迫。dlY = modelDecoder(参数,dlX,状态);%的损失。dlYPred = dlY(:,:,1:end-1);dlT = dlX(:,:,2:结束);loss = mean(maskedCrossEntropy(dlYPred,dlT,sequenceLengths));%梯度。gradient = dlgradient(损失,参数);为绘图规范化损失。sequenceLength = size(dlX,3);loss = loss / sequenceLength;结束
模型预测函数
的modelPredictions函数在给定模型参数、解码器初始状态、最大序列长度、单词编码、开始标记和小批处理大小的情况下返回解码器的输出分数。
函数dlY = modeldecoderprediction (parameters,dlZ,maxLength,enc,startToken,miniBatchSize) numObservations = size(dlZ,2);numIterations = ceil(numObservations / miniBatchSize);startTokenIdx = word2ind(enc,startToken);vocabularySize = en . numwords;词汇量,numObservations,maxLength,“喜欢”, dlZ);在小批量上循环。为i = 1:numIterations idxMiniBatch = (i-1)*miniBatchSize+1:min(i*miniBatchSize,numObservations);miniBatchSize = numel(idxMiniBatch);初始化状态。State = struct;状态。HiddenState = dlZ(:,idxMiniBatch);状态。CellState = 0 (size(dlZ(:,idxMiniBatch)),“喜欢”, dlZ);初始化解码器输入。decoderInput = dlarray(repmat(startTokenIdx,[1 miniBatchSize]),“认知行为治疗”);%循环时间步骤。为t = 1:maxLength预测下一个时间步骤。[dlY(:,idxMiniBatch,t), state] = modelDecoder(parameters,decoderInput,state);%闭环生成。[~,idx] = max(d1 (:,idxMiniBatch,t));decoderInput = idx;结束结束结束
掩模交叉熵损失函数
的maskedCrossEntropy函数使用指定的序列长度向量计算指定输入序列和目标序列之间的损失,忽略包含填充的任何时间步。
函数maskedLoss = maskedCrossEntropy(dlY,T,sequenceLengths) numClasses = size(dlY,1);miniBatchSize = size(dd,2);sequenceLength = size(d1,3);maskedLoss = 0 (sequenceLength,miniBatchSize,“喜欢”、海底);为t = 1:sequenceLength T1 = single(oneHot(t(:,:,t),numClasses));mask = (t<=sequenceLengths)';maskedLoss (t):) =面具。* crossentropy(海底(:,:,t), T1,“DataFormat”,“认知行为治疗”);结束maskedLoss = sum(maskedLoss,1);结束
文本预处理功能
这个函数preprocessText执行以下步骤:
分别用指定的开始和停止标记在每个输入字符串的前面和后面。
使用标记化文本
tokenizedDocument.
函数documents = preprocessText(textData,startToken,stopToken)添加开始和停止令牌。textData = startToken + textData + stopToken;标记文本。文档= tokenizedDocument(textData,“CustomTokens”, (startToken stopToken]);结束
嵌入函数
的嵌入函数使用给定的权值将索引序列映射到向量。
函数Z =嵌入(X,权重)将输入重塑为向量。[N, T] = size(X, 2:3);X =重塑(X, N*T, 1);%索引到嵌入矩阵。Z = weights(:, X);通过分离批和序列维度来重塑输出。。Z =重塑(Z, [], N, T);结束
一热编码函数
的oneHot函数将数值索引数组转换为一次编码的向量。
函数oh = oneHot(idx, outputSize) miniBatchSize = numel(idx);oh = 0 (outputSize,miniBatchSize);为1:miniBatchSize c = idx(n);Oh (c,n) = 1;结束结束
另请参阅
相关的话题
您也可以从以下列表中选择网站:
