使用注意力的图像说明
这个例子展示了如何训练一个深度学习模型来使用注意力进行图像字幕。
大多数预训练的深度学习网络配置为单标签分类。例如,给定一张典型的办公桌的图像,网络可能预测单一类别的“键盘”或“鼠标”。相比之下,图像字幕模型结合了卷积和循环操作来生成图像内容的文本描述,而不是单个标签。
本例中训练的模型使用编码器-解码器体系结构。编码器是一个预训练的Inception-v3网络,用作特征提取器。解码器是一个递归神经网络(RNN),它将提取的特征作为输入并生成字幕。解码器包含一个注意机制这使得解码器在生成标题时能够关注部分编码输入。
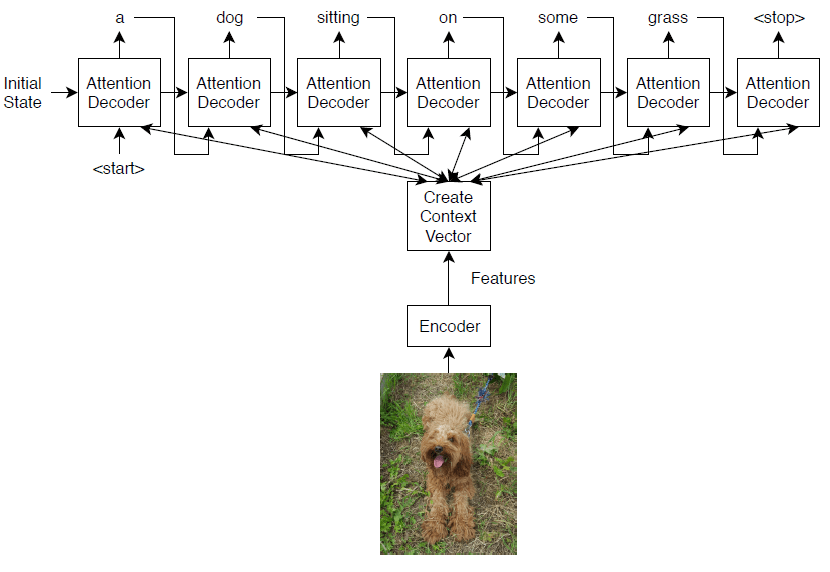
编码器模型是一个预先训练的Inception-v3模型,它从“mixed10”层,然后是完全连接和ReLU操作。

译码器模型包括一个单词嵌入、一个注意机制、一个选通循环单元(GRU)和两个完全连接的操作。

负载Pretrained网络
加载预训练的Inception-v3网络。此步骤需要深度学习工具箱™ 模型对于Inception-v3网络万博1manbetx支持包。如果您没有安装所需的支持包,那么该软件将提供下载链接。万博1manbetx
净= inceptionv3;inputSizeNet = net.Layers(1).InputSize;
将网络转换为dlnetwork对象进行特征提取,并删除最后四层,保留“mixed10”层作为最后一层。
lgraph = layerGraph(净);lgraph = removeLayers (lgraph, (“avg_pool”“预测”“predictions_softmax”“ClassificationLayer_predictions”]);
查看网络的输入层。Inception-v3网络使用对称缩放归一化,最小值为0,最大值为255。
lgraph.Layers(1)
ans = ImageInputLayer with properties: Name: 'input_1' InputSize: [299 299 3] Hyperparameters DataAugmentation: 'none' Normalization: ' scale-symmetric' NormalizationDimension: 'auto' Max: 255 Min: 0
自定义训练不支持此规范化,因此必须在网络中禁用规范万博1manbetx化,并在自定义训练循环中执行规范化。将最小值和最大值保存为名为输入分钟和输入最大值,将输入层替换为不规格化的图像输入层。
inputMin=double(lgraph.Layers(1.Min);inputMax=double(lgraph.Layers(1.Max);layer=imageInputLayer(inputSizeNet,“归一化”那“没有”那'姓名'那'输入');lgraph = replaceLayer (lgraph,“输入_1”层);
确定网络的输出大小。使用analyzeNetwork函数查看最后一层的激活大小。深度学习网络分析仪显示了网络的一些问题,这些问题可以在定制培训工作流中安全地忽略。
analyzeNetwork (lgraph)

创建一个名为输出SizeNet包含网络输出大小。
outputSizeNet = [8 8 2048];
该层图形转换成dlnetwork对象并查看输出层。输出层是“mixed10”先启-V3网络的层。
dlnet = dlnetwork(lgraph)
dlnet = dlnetwork with properties: Layers: [311×1 net.cnn.layer. layer] Connections: [345×2 table] Learnables: [376×3 table] State: [188×3 table] InputNames: {'input'} OutputNames: {'mixed10'}
导入COCO数据集
从数据集“2014 Train images”和“2014 Train/val annotation”分别下载图片和注释https://cocodataset.org/#download.将图像和注释提取到一个名为“可可”.COCO 2014数据集由可可协会.
从文件中提取标题“captions_train2014.json”使用jsondecode函数。
dataFolder = fullfile (tempdir,“可可”);文件名=完整文件(dataFolder,“annotations_trainval2014”那“注释”那“captions_train2014.json”);str = fileread(文件名);data = jsondecode (str)
资料=带字段的结构:信息:[1×1结构]图片:[82783×1结构]许可证:[8×1结构]注释:[414113×1结构]
这注释结构体的字段包含图像标题所需的数据。
data.annotations
ans =414113×1带有字段的结构数组:image_id id标题
数据集包含每个图像的多个标题。为确保在训练集和验证集中不会出现相同的图像,请使用唯一的通过使用image_id字段,然后查看唯一图像的数量。
numObservationsAll =元素个数(data.annotations)
numObservationsAll = 414113
imageid = [data.annotations.image_id];imageIDsUnique =独特(imageid);numUniqueImages =元素个数(imageIDsUnique)
numUniqueImages = 82783
每个图像至少有五个标题。创建一个结构注释所有使用以下字段:
ImageID-图片ID文件名-图像的文件名标题— 原始标题的字符串数组CaptionIDs-中相应标题的索引向量data.annotations
为了使合并更容易,可以根据图像id对注释进行排序。
[~, idx] = ([data.annotations.image_id])进行排序;data.annotations= data.annotations(idx);
循环注释并在必要时合并多个注释。
我= 0;J = 0;imageIDPrev = 0;虽然I < numel(data.annotations) I = I + 1;imageID = data.annotations .image_id;标题=字符串(data.annotations(我).caption);如果imageID ~ = imageIDPrev%创建新条目j=j+1;注释所有(j).ImageID=ImageID;注释所有(j).Filename=fullfile(dataFolder,“train2014”那“COCO_train2014_u”+pad(字符串(图像ID),12,“左”那'0') +“.jpg”);annotationsAll(j)的.Captions =字幕;annotationsAll(j)的.CaptionIDs = I;其他的%追加字幕annotationsAll (j)。标题= [annotationsAll(j).Captions; caption]; annotationsAll(j).CaptionIDs = [annotationsAll(j).CaptionIDs; i];结束imageIDPrev=imageID;结束
将数据划分为训练集和验证集。拿出5%的观察值进行测试。
CVP = cvpartition(numel(annotationsAll),“坚持”, 0.05);idxTrain =培训(cvp);idxTest =测试(cvp);annotationsTrain = annotationsAll (idxTrain);annotationsTest = annotationsAll (idxTest);
该结构包含三个字段:
id-标题的唯一标识符标题-图像标题,指定为字符向量image_id-图像与标题对应的唯一标识符
若要查看图像和相应的标题,请定位带有文件名的图像文件“train2014 \ COCO_train2014_XXXXXXXXXXXX.jpg”,在那里“XXXXXXXXXX”对应的图像ID左填充为0,长度为12。
imageID = annotationsTrain (1) .ImageID;标题= annotationsTrain (1) .Captions;文件名= annotationsTrain (1) .Filename;
要查看图像,请使用伊姆雷德和imshow功能。
img=imread(文件名);图imshow(img)标题(字幕)
为培训准备数据
准备训练和测试的字幕。摘自文标题包含训练和测试数据的结构体的字段(注释所有),删除标点符号,并将文本转换为小写。
captionsAll=类别(1,注释所有标题);captionsAll=删除标点符号(captionsAll);captionsAll=较低(captionsAll);
为了生成标题,RNN解码器需要特殊的开始和停止标记,分别指示何时开始和停止生成文本。添加自定义令牌“<开始>”和“<停止>”以分别开始和字幕的端部。
captionsAll =“<开始>”+ captionsAll +“<停止>”;
标记标题使用标记化文档功能,并指定使用的开始和结束标记“CustomTokens”选择。
documentsAll = tokenizedDocument (captionsAll,“CustomTokens”,[“<开始>”“<停止>”]);
创建一个wordEncoding对象,该对象将单词映射为数字索引并返回。根据训练数据中最常观察到的单词,将词汇量设定为5000,以减少记忆要求。为了避免偏差,只使用与训练集相对应的文档。
ENC = wordEncoding(documentsAll(idxTrain),“MaxNumWords”, 5000,“订单”那“频率”);
创建包含与标题相对应的图像的增强图像数据存储。设置输出大小以匹配卷积网络的输入大小。若要使图像与标题保持同步,请通过使用图像ID重建文件名来指定数据存储的文件名表。若要以3-ch格式返回灰度图像,请退火RGB图像,设置“颜色预处理”选项“gray2rgb”.
tblFilenames=表格(cat(1,annotationsTrain.Filename));augimdsTrain=增强图像数据存储(inputSizeNet,tblFilenames,“颜色预处理”那“gray2rgb”)
augimdsTrain = augmentedImageDatastore with properties: NumObservations: 78644 MiniBatchSize: 1 DataAugmentation: 'none' ColorPreprocessing: 'gray2rgb' OutputSize: [299 299] OutputSizeMode: 'resize' DispatchInBackground: 0
初始化模型参数
初始化模型参数。指定512个隐藏单元,单词嵌入维数为256。
embeddingDimension = 256;numHiddenUnits = 512;
初始化包含编码器模型参数的结构体。
属性指定的gloria初始化器初始化全连接操作的权值
initializeGlorot函数,列在示例的最后。指定输出大小以匹配解码器的嵌入维数(256),以及输入大小以匹配预先训练网络的输出通道数。这“mixed10”Inception-v3网络的一层有2048个通道输出数据。
numFeatures=outputSizeNet(1)*outputSizeNet(2);InputSizenCoder=outputSizeNet(3);parametersEncoder=struct;%完全连接parametersEncoder.fc.Weights = dlarray (initializeGlorot (embeddingDimension inputSizeEncoder));parametersEncoder.fc.Bias = dlarray(zeros([embedingdimension 1]),“单一”));
初始化包含解码器模型参数的结构体。
初始化单词嵌入权值,其大小由嵌入维度和词汇表大小加1给出,其中额外的条目对应于填充值。
初始化Bahdanau注意机制的权重和偏差,其大小与GRU操作的隐藏单元数相对应。
初始化GRU操作的权重和偏差。
初始化两个完全连接操作的权值和偏差。
对于模型解码器参数,分别使用Glorot初始值设定项和零初始化每个权重和偏差。
inputSizeDecoder = enc.NumWords + 1;parametersDecoder =结构;%单词嵌入参数decoder.emb.Weights=dlarray(initializeGroot(EmbeddedingDimension,InputSizedCoder));%的关注parametersDecoder.attention.Weights1 = dlarray(initializeGlorot(numHiddenUnits,embeddingDimension));parametersDecoder.attention.Bias1 = dlarray(零([numHiddenUnits 1],“单一”));parametersDecoder.attention。Weights2 = dlarray (initializeGlorot (numHiddenUnits numHiddenUnits));parametersDecoder.attention。Bias2 = dlarray(0 ([numHiddenUnits 1],),“单一”));numHiddenUnits parametersDecoder.attention.WeightsV = dlarray (initializeGlorot (1));parametersDecoder.attention.BiasV = dlarray (0 (1, - 1,“单一”));%GRUparametersDecoder.gru.InputWeights = dlarray(initializeGlorot(3个* numHiddenUnits,2 * embeddingDimension));parametersDecoder.gru.RecurrentWeights = dlarray(initializeGlorot(3个* numHiddenUnits,numHiddenUnits));parametersDecoder.gru.Bias = dlarray(零(3个* numHiddenUnits,1,“单一”));%完全连接parametersDecoder.fc1。重量= dlarray (initializeGlorot (numHiddenUnits numHiddenUnits));parametersDecoder.fc1。Bias = dlarray(0 ([numHiddenUnits 1]),“单一”));%完全连接parametersDecoder.fc2.Weights=dlarray(初始化为Lorot(enc.NumWords+1,numHiddenUnits));parametersDecoder.fc2.Bias=dlarray(零([enc.NumWords+1],“单一”));
定义模型函数
创建函数modelEncoder和modelDecoder,分别计算编码器和解码器模型的输出。
这modelEncoder函数中列出的编码器模型函数在本例的一节中,将一个激活数组作为输入dlX从预训练网络的输出,并通过一个完全连接的操作和一个ReLU操作。由于预先训练的网络不需要跟踪自动区分,提取编码器模型函数外的特征更具有计算效率。
这modelDecoder函数中列出的解码器型号功能在示例的一部分中,将对应于输入字的单个输入时间步长、解码器模型参数、编码器的特征和网络状态作为输入,并返回对下一个时间步长、更新的网络状态和注意力权重的预测。
指定培训选项
指定培训选项。训练30个时代,小批量128个,并在一个plot中显示训练进度。
miniBatchSize = 128;numEpochs = 30;情节=“培训进度”;
如果GPU可用,在GPU上训练。使用GPU需要并行计算工具箱™ 和支持的GPU设备。有关支持的设备的信息,请参阅万博1manbetxGPU支万博1manbetx持情况(并行计算工具箱).
执行环境=“汽车”;
列车网络
使用自定义训练循环训练网络。
在每个历元开始时,对输入数据进行无序排列。为了使增强图像数据存储中的图像与标题保持同步,请创建一个无序排列的索引数组,将索引放入两个数据集中。
为每个mini-batch:
将图像重新缩放到预先训练的网络所期望的大小。
对于每个图像,选择一个随机的标题。
将标题转换为单词索引序列。使用与填充标记的索引对应的填充值指定序列的右填充。
将数据转换为
dlarray对象。对于图像,指定尺寸标签“SSCB”(spatial, spatial, channel, batch)。对于GPU培训,将数据转换为
gpuArray对象。利用预先训练的网络提取图像特征,并将其重塑到编码器所期望的大小。
评估模型梯度和损失使用
dlfeval和modelGradients功能。控件更新编码器和解码器模型参数
adamupdate函数。在图中显示训练进度。
初始化亚当优化器的参数。
trailingAvgEncoder = [];trailingAvgSqEncoder = [];trailingAvgDecoder = [];trailingAvgSqDecoder = [];
初始化培训进度图。创建一条动画线,根据相应的迭代来绘制损失。
如果阴谋==“培训进度”figure lineLossTrain=动画线(“颜色”[0.85 0.325 0.098]);包含(“迭代”)伊拉贝尔(“损失”)ylim([0 inf])网格在…上结束
火车模型。
迭代= 0;numObservationsTrain = numel(annotationsTrain);numIterationsPerEpoch =地板(numObservationsTrain / miniBatchSize);开始=抽动;%循环纪元。为历元=1:numEpochs%洗牌数据。idxShuffle = randperm (numObservationsTrain);%循环小批。为i=1:numIterationsPerEpoch迭代=迭代+1;%确定小批量指标。idx =(张)* miniBatchSize + 1:我* miniBatchSize;idxMiniBatch = idxShuffle (idx);%读取小批数据。台= readByIndex (augimdsTrain idxMiniBatch);猫(X = 4, tbl.input {:});注释= annotationsTrain (idxMiniBatch);%对于每个图像,选择随机标题。idx = cellfun(@(captionIDs) randsample(captionIDs,1),{annotation . captionIDs});文件= documentsAll (idx);%创建一批数据。[dlX,dlT]=createBatch(X,文档,dlnet,inputMin,inputMax,enc,executionEnvironment);%使用dlfeval和% modelGradients函数。[gradientsEncoder,gradientsEncoder,loss]=dlfeval(@modelGradients,parametersEncoder,...parametersDecoder、dlX dlT);%更新编码器使用adamupdate。[参数SENCODER,trailingAvgEncoder,trailingAvgSqEncoder]=数据更新(参数SENCODER,...gradientsEncoder, trailingAvgEncoder, trailingAvgSqEncoder,迭代);%更新解码器使用adamupdate。[parametersDecoder, trailingAvgDecoder, trailingAvgSqDecoder] = adamupdate(parametersDecoder,...梯度编码器、trailingAvgDecoder、trailingAVGSQdeecoder、迭代);%显示训练进度。如果阴谋==“培训进度”D=持续时间(0,0,toc(开始),“格式”那“hh: mm: ss”);addpoints (lineLossTrain、迭代、双(收集(extractdata(损失))))标题(”时代:“+时代+“消逝”+字符串(D)现在开始结束结束结束

预测新标题
标题生成过程与训练过程不同。在训练过程中,解码器在每一个时间步长上都使用前一个时间步长的真值作为输入。这就是所谓的“强迫教师”。当对新数据进行预测时,解码器使用以前的预测值而不是真实值。
预测序列中每一步最可能出现的单词可能导致次优结果。例如,如果解码器在给出大象的图像时预测标题的第一个单词是“a”,那么预测下一个单词的“大象”的概率就变得更不可能了,因为短语“大象”出现在英语文本中的概率非常低。
要解决这个问题,您可以使用波束搜索算法:不要对序列中的每个步骤采用最可能的预测,而是采用顶部预测K.预测(波束指数)和接下来的每个步骤,保持顶部K.根据总分预测到目前为止的序列。
通过提取图像特征,将其输入编码器,然后使用beamSearch函数中列出的束搜索功能这个例子的一部分。
img = imread (“laika_siting.jpg”);DLX = extractImageFeatures(dlnet,IMG inputMin,inputMax,执行环境);beamIndex = 3;maxNumWords = 20;[即,attentionScores] = beamSearch(DLX,beamIndex,parametersEncoder,parametersDecoder,ENC,maxNumWords);标题=加入(字)
标题=“狗是站在一个瓷砖地板”
显示图像和标题。
图imshow (img)标题(标题)

预测数据集的标题
要预测图像集合的标题,可以对数据存储中的小批量数据进行循环,并使用extractImageFeatures作用然后,在小批量中循环图像,并使用beamSearch函数。
创建一个扩充的图像数据存储,并将输出大小设置为与卷积网络的输入大小匹配。将灰度图像输出为3通道RGB图像,设置“颜色预处理”选项“gray2rgb”.
TBLFileNameTest=表格(cat(1,annotationsTest.Filename));AugimdTest=增强图像数据存储(inputSizeNet,TBLFileNameTest,“颜色预处理”那“gray2rgb”)
augimdsTest = augmentedImageDatastore with properties: NumObservations: 4139 MiniBatchSize: 1 DataAugmentation: 'none' ColorPreprocessing: 'gray2rgb' OutputSize: [299 299] OutputSizeMode: 'resize' DispatchInBackground: 0
为测试数据生成标题。在大型数据集上预测标题可能需要一些时间。如果您有并行计算工具箱™, 然后,您可以通过在一个文档中生成标题来并行地进行预测PARFOR看。如果您没有“并行计算工具箱”。然后PARFOR循环以串行方式运行。
beamIndex=2;maxNumWords=20;numObservationsTest=numel(annotationsTest);NumItemationsTest=ceil(numObservationsTest/miniBatchSize);captionsTestPred=String(1,numObservationsTest);documentsTestPred=tokenizedDocument(String(1,numObservationsTest));为I = 1:numIterationsTest% Mini-batch指数。idxStart =(张)* miniBatchSize + 1;idxEnd = min(我* miniBatchSize numObservationsTest);idx = idxStart: idxEnd;深圳=元素个数(idx);%读取图像。TBL = readByIndex(augimdsTest,IDX);%提取图像特征。猫(X = 4, tbl.input {:});DLX = extractImageFeatures(dlnet,X,inputMin,inputMax,执行环境);%生成标题。captionsPredMiniBatch=字符串(1,sz);documentsPredMiniBatch=标记化文档(字符串(1,sz));PARFORj=1:sz words=beamSearch(dlX(:,:,j),beamIndex,parametersEncoder,parametersDecoder,enc,maxNumWords);字幕predminibatch(j)=连接(单词);documentsPredMiniBatch(j)=标记化文档(文字、,'TokenizeMethod'那“没有”);结束captionsTestPred(idx)=captionsPredMiniBatch;documentsTestPred(idx)=documentsPredMiniBatch;结束
分析和传送文件给工人…完成。
与对应的标题查看的测试图像,使用imshow功能,并设置标题的预测标题。
idx = 1;台= readByIndex (augimdsTest idx);img = tbl.input {1};图imshow (img)标题(captionsTestPred (idx))
评价模型精度
要使用BLEU分数评估字幕的准确性,请使用bleuEvaluationScore函数。使用bleuEvaluationScore功能,你可以比较单一候选人的文件到多个参考文件。
这bleuEvaluationScore默认情况下,函数使用长度为1到4的n-gram对相似性进行评分。由于标题很短,这种行为可能导致信息不充分的结果,因为大多数分数都接近于零。将n-gram长度设置为1到2,通过设置“NgramWeights”选择具有相等权重的两个元素向量。
ngramWeights = [0.5 0.5];为i=1:numObservationsTest annotation=annotationsTest(i);captionIDs=annotation.captionIDs;候选者=文件测试(i);参考=文件所有(标题ID);分数=BLUEEvaluationScore(候选人、推荐人、,“NgramWeights”, ngramWeights);分数(i) =分数;结束
查看平均BLEU得分。
scoreMean =意味着(分数)
scoreMean = 0.4224
在可视化的直方图的分数。
图直方图(分数)包含(“BLEU分数”)伊拉贝尔(“频率”)

注意功能
这注意函数利用Bahdanau注意计算上下文向量和注意权重。
作用[contextVector,attentionWeights] =注意(隐藏,特征,weights1,...bias1、weights2 bias2、weightsV biasV)%模型维度。[embeddingDimension, numFeatures miniBatchSize] =大小(特性);numHiddenUnits =大小(weights1, 1);%完全连接。DLY1 =重塑(功能,embeddingDimension,numFeatures * miniBatchSize);DLY1 = fullyconnect(DLY1,weights1,偏置1,“DataFormat”那“CB”);dlY1 =重塑(dlY1 numHiddenUnits、numFeatures miniBatchSize);%完全连接。dlY2=完全连接(隐藏、权重2、bias2、,“DataFormat”那“CB”);dlY2 =重塑(dlY2 numHiddenUnits 1, miniBatchSize);%,双曲正切。分数=的tanh(DLY1 + DLY2);分数=重塑(分数,numHiddenUnits,numFeatures * miniBatchSize);完全连接,softmax。注意权重=完全连接(分数、权重SV、biasV、,“DataFormat”那“CB”);attentionWeights =重塑(attentionWeights 1 numFeatures miniBatchSize);attentionWeights = softmax (attentionWeights,“DataFormat”那“SCB”);%的上下文。contextVector = attentionWeights .* feature;contextVector =挤压(sum (contextVector, 2));结束
嵌入函数
这嵌入函数将一个索引数组映射到一个嵌入向量序列。
作用Z =嵌入(X,权重)%整形输入到载体[N, T] = size(X, 1:2);X =重塑(X, N*T, 1);%嵌入矩阵的索引Z =重量(:,X);%通过分离批处理和序列尺寸来重塑输出Z =重塑(Z, [], N, T);结束
特征提取功能
这extractImageFeatures函数将经过训练的dlnetwork对象,输入图像,进行图像重新缩放的统计,和执行环境,并返回一个dlarray包含从预先训练的网络中提取的特征。
作用DLX = extractImageFeatures(dlnet,X,inputMin,inputMax,执行环境)%调整大小并重新缩放。inputSize=dlnet.Layers(1).inputSize(1:2);X=imresize(X,inputSize);X=rescale(X,-1,1,“InputMin”,inputMin,“InputMax”,输入最大值);%转换为dlarray。dlX = dlarray (X,“SSCB”);%转换为gpuArray。如果(executionEnvironment = =“汽车”&& canUseGPU) || executionEnvironment ==“gpu”dlX = gpuArray (dlX);结束%提取特征并重塑。dlX=预测(dlnet,dlX);sz=大小(dlX);numFeatures=sz(1)*sz(2);inputsizencoder=sz(3);miniBatchSize=sz(4);dlX=重塑(dlX,[numFeatures inputsizencoder miniBatchSize]);结束
批处理创建函数
这createBatch函数将一小批数据、标记化字幕、预训练网络、用于图像重缩放的统计信息、字编码和执行环境作为输入,并返回与提取的图像特征和字幕相对应的一小批数据以供训练。
作用[dlX, dlT] = createBatch(X,documents,dlnet,inputMin,inputMax,enc,executionEnvironment) dlX = extractImageFeatures(dlnet,X,inputMin,inputMax,executionEnvironment);将文档转换为单词索引序列。T = doc2sequence (enc、文档'PaddingDirection'那“对”那“PaddingValue”, enc.NumWords + 1);T =猫(1 T {:});%转换小批数据到美元。dlT = dlarray (T);%如果在GPU上训练,则将数据转换为gpuArray。如果(executionEnvironment = =“汽车”&& canUseGPU) || executionEnvironment ==“gpu”dlT = gpuArray (dlT);结束结束
编码器模型函数
这modelEncoder函数接受一个激活数组作为输入dlX并通过一个完全连接的操作和一个ReLU操作传递它。对于全连接操作,只在通道尺寸上操作。要仅在通道维度上应用完全连接操作,请将其他通道扁平化为单个维度,并使用“DataFormat”选择权fullyconnect函数。
作用DLY = modelEncoder(DLX,parametersEncoder)[numFeatures,inputSizeEncoder,miniBatchSize] =尺寸(DLX);%完全连接重量= parametersEncoder.fc.Weights;偏见= parametersEncoder.fc.Bias;embeddingDimension =大小(重量、1);dlX = permute(dlX,[2 1 3]);dlX =重塑(dlX、inputSizeEncoder numFeatures * miniBatchSize);海底= fullyconnect (dlX、权重、偏见,“DataFormat”那“CB”);dlY=重塑(dlY,嵌入尺寸,numFeatures,miniBatchSize);% ReLUDLY = RELU(DLY);结束
解码器型号功能
这modelDecoder函数以单个时间步长作为输入dlX、解码器模型参数、编码器的特征和网络状态,并返回下一个时间步骤的预测、更新的网络状态和注意力权重。
作用[dlY,state,attentionWeights]=模型解码器(dlX,参数编码器,功能,状态)hiddenState=state.gru.hiddenState;%的关注weights1 = parametersDecoder.attention.Weights1;bias1 = parametersDecoder.attention.Bias1;weights2 = parametersDecoder.attention.Weights2;bias2 = parametersDecoder.attention.Bias2;weightsV = parametersDecoder.attention.WeightsV;biasV = parametersDecoder.attention.BiasV;[contextVector, attentionWeights] = attention(hiddenState,features,weights1,bias1,weights2,bias2,weightsV,biasV);%嵌入权重=参数decoder.emb.weights;dlX=嵌入(dlX,权重);%CONCATENATEdlY=cat(1,上下文向量,dlX);%GRUinputWeights = parametersDecoder.gru.InputWeights;recurrentWeights = parametersDecoder.gru.RecurrentWeights;偏压= parametersDecoder.gru.Bias;[DLY,hiddenState] = GRU(DLY,hiddenState,inputWeights,recurrentWeights,偏置,“DataFormat”那“CBT”);%更新状态state.gru.HiddenState=HiddenState;%完全连接重量= parametersDecoder.fc1.Weights;偏见= parametersDecoder.fc1.Bias;海底= fullyconnect(海底,重量、偏见,“DataFormat”那“CB”);%完全连接权重=参数decoder.fc2.weights;偏差=参数decoder.fc2.bias;Dy=完全连接(Dy,权重,偏差,“DataFormat”那“CB”);结束
模型梯度
这modelGradients函数将编码器和解码器参数作为输入,编码器的特性dlX,以及目标标题dlT并返回该编码器和解码器的参数的梯度相对于损失,损失,且预测。
作用[gradientsEncoder gradientsDecoder,损失,dlYPred] =...modelGradients(parametersEncoder,parametersDecoder,dlX,dlT)miniBatchSize=大小(dlX,3);sequenceLength=大小(dlT,2)-1;vocabSize=大小(parametersDecoder.emb.Weights,2);%模型编码器特点= modelEncoder (dlX parametersEncoder);%初始化状态numHiddenUnits =大小(parametersDecoder.attention.Weights1, 1);状态=结构;state.gru.HiddenState = dlarray(0) ([numHiddenUnits miniBatchSize],“单一”));dlYPred=dlarray(零([vocabSize miniBatchSize sequenceLength],“喜欢”dlX));损失= dlarray(单(0));padToken = vocabSize;为t = 1时:sequenceLength decoderInput = DLT(:,T);dlYReal = DLT(:,T + 1);[dlYPred(:,:,T),状态] = modelDecoder(decoderInput,parametersDecoder,特征,状态);掩模= dlYReal〜= padToken;损耗=损耗+ sparseCrossEntropyAndSoftmax(dlYPred(:,:,T),dlYReal,掩模);结束%计算梯度[gradientsEncoder,gradientsDecoder]=dlgradient(丢失,参数sEncoder,参数sDecoder);结束
稀疏交叉熵和Softmax损失函数
这sparseCrossEntropyAndSoftmax作为输入的预测海底,相应的目标dlT,序列填充掩码,并应用softmax函数并返回交叉熵损失。
作用损耗= sparseCrossEntropyAndSoftmax(DLY,DLT,掩模)miniBatchSize =尺寸(DLY,2);%Softmax。DLY = SOFTMAX(DLY,“DataFormat”那“CB”);找到与目标单词对应的行。IDX = sub2ind(大小(DLY),DLT”,1:miniBatchSize);DLY = DLY(IDX);远离零。DLY = MAX(DLY,单(1E-8));%掩饰的损失。损失=对数(DY)。*掩码';损失=-总和(损失,“所有”)。/ miniBatchSize;结束
束搜索功能
这beamSearch函数将图像特征作为输入dlX,波束索引,对于编码器和解码器的网络的参数,一个字的编码,和一个最大序列长度,并返回用于使用所述波束搜索算法的图像标题的话。
作用(话说,attentionScores) = beamSearch (dlX、beamIndex parametersEncoder, parametersDecoder,...enc,maxNumWords)%模型尺寸numFeatures=size(dlX,1);numHiddenUnits=size(parameters-coder.attention.weights 1,1);%提取特征特点= modelEncoder (dlX parametersEncoder);%初始化状态state=struct;state.gru.HiddenState=dlarray(零([numHiddenUnits 1],“喜欢”dlX));%初始化候选人候选者=结构;候选人。州=州;候选人,用词=“<开始>”;候选人。分数= 0;候选人。AttentionScores = dlarray(0 ([numFeatures maxNumWords],“喜欢”,dlX));candidates.StopFlag=false;t=0;%循环字虽然t < maxNumWords t = t + 1;candidatesNew = [];%循环候选人为i=1:numel(候选人)%在预测停止令牌时停止生成如果候选人(i)。StopFlag继续结束%候选人详情状态=(我).State候选人;话说=候选人(我).Words;得分=(我).Score候选人;.AttentionScores attentionScores =候选人(我);%预测下一个标记decoderInput = word2ind (enc,话说(结束));[dlYPred、州attentionScores (:, t)] = modelDecoder (decoderInput, parametersDecoder、特征、状态);dlYPred = softmax (dlYPred,“DataFormat”那“CB”);[scoresTop, idxTop] = maxk (extractdata (dlYPred) beamIndex);idxTop =收集(idxTop);%循环预测为j = 1:beamIndex候选= struct;candidateWord = ind2word (enc, idxTop (j));candidateScore = scoresTop (j);如果candidateWord = =“<停止>”候选人。StopFlag= true; attentionScores(:,t+1:end) = [];其他的candidate.StopFlag=false;结束候选人。=状态;候选人。[单词候选人];候选人。Score = Score + log(candidatscore);候选人。AttentionScores = AttentionScores;[候选人];结束结束找到最优秀的候选人[~, idx] = maxk ([candidatesNew.Score], beamIndex);候选人= candidatesNew (idx);当所有候选人都有停止标记时停止预测如果全部([candidates.stopfag])打破结束结束%获取热门人选话说=候选人(1).Words (2: end-1);attentionScores = (1) .AttentionScores候选人;结束
gloot权重初始化函数
这initializeGlorot函数根据gloria初始化生成权重数组。
作用权重=初始值为Lorot(numOut,numIn)varWeights=sqrt(6/(numIn+numOut));权重=varWeights*(2*rand([numOut,numIn]),“单一”) - 1);结束
另请参阅
adamupdate|交叉熵|dlarray|dlfeval|梯度|dlupdate|格勒乌|lstm|softmax|DOC2序列(文本分析工具箱)|标记化文档(文本分析工具箱)|word2ind(文本分析工具箱)|wordEncoding(文本分析工具箱)
相关话题
您还可以从以下列表中选择网站:
