训练一个暹罗网络来比较图像
此示例显示如何培训暹罗网络以识别手写字符的类似图像。
暹罗网络是一种深入学习网络,它使用具有相同架构的两个或多个相同的子网,并共享相同的参数和权重。暹罗网络通常用于涉及在两个可比较的事物之间找到关系的任务。暹罗网络的一些常见应用包括面部识别,签名验证[1],或解释识别[2]。暹罗网络在这些任务中表现良好,因为它们的共享权重意味着在培训期间可以学习的参数较少,并且它们可以通过相对少量的培训数据产生良好的结果。
暹罗网络特别有用的情况下,有大量的类与少量的观察每个。在这种情况下,没有足够的数据来训练深度卷积神经网络来将图像分类。相反,Siamese网络可以确定两个图像是否属于同一类。
这个例子使用Omniglot数据集[3]训练一个暹罗网络来比较手写字符[4]的图像。Omniglot数据集包含50个字母的字符集,其中30个用于训练,20个用于测试。每个字母表包含从14个字符的Ojibwe(加拿大土著Sullabics)到55个字符的Tifinagh。最后,每个字符有20个手写的观察结果。这个例子训练了一个网络来识别两个手写的观察是否是相同字符的不同实例。
您还可以使用暹罗网络通过降维来识别类似的图像。例如,请参见训练一个暹罗网络降维.
加载和预处理训练数据
下载并解压缩Omniglot训练数据集。
url =“https://github.com/brendenlake/omniglot/raw/master/python/images_background.zip”;downloadFolder = tempdir;文件名= fullfile (downloadFolder,“images_background.zip”);dataFolderTrain = fullfile (downloadFolder,'images_background');如果~存在(dataFolderTrain“dir”) disp (“下载Omniglot训练数据(4.5 MB)…”) websave(文件名,url);解压缩(文件名,downloadFolder);结束disp (“训练数据下载”。)
训练数据下载。
控件将训练数据作为图像数据存储加载imageDatastore函数。手动指定标签,方法是从文件名中提取标签并设置标签财产。
imdsTrain = imageDatastore (dataFolderTrain,......“包含子文件夹”符合事实的......“标签源”,“没有”);文件= imdsTrain.Files;部分=分裂(文件、filesep);标签=加入(部分(:,(end-2): (end-1)),'_'); imdsTrain.Labels=分类(标签);
Omniglot训练数据集由来自30个字母的黑白手写字符组成,每个字符有20个观察值。图像大小为105 × 105 × 1,每个像素的值介于0和1.
显示图像的随机选择。
idxs = randperm(numel(imdstrain.files),8);为i = 1:num (idxs) subplot(4,2,i) imshow(readimage(imdsTrain,idxs(i))) title(imdsTrain. labels (idxs(i)),“翻译”,“没有”);结束
创建相似和不同的图像对
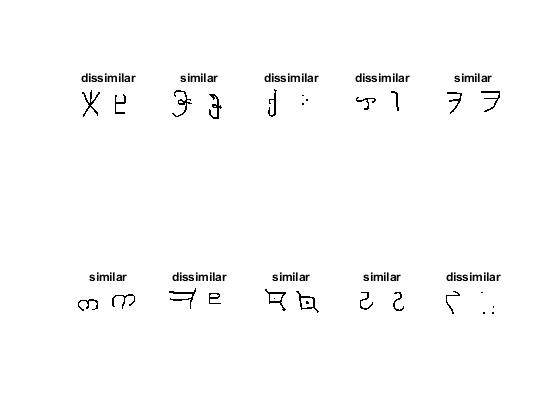
为了训练网络,数据必须被分组成一对对相似或不同的图像。在这里,相似的图像是相同字符的不同手写实例,具有相同的标签,而不同字符的不同图像具有不同的标签。这个函数getsiameSebatch.(定义在万博1manbetx辅助功能)创建随机配对的相似或不同的图像,Bireimage1.和pairImage2。该函数还返回标签pairLabel,它可以识别这对图像是相似的还是不同的。相似的图像有pairLabel = 1,而不同的一对则有pairLabel = 0.
例如,创建一个由五对图像组成的具有代表性的小集合
batchSize = 10;[pairImage1, pairImage2 pairLabel] = getSiameseBatch (imdsTrain batchSize);
显示生成的图像对。
为我= 1:batchSize如果pairLabel(i) == 1 s =“相似”;其他的s =“不同”;结束子地块(2,5,i)imshow([pairImage1(:,:,:,i)pairImage2(:,:,,:,i)];标题结束
在这个例子中,每个训练循环的迭代都会创建一个由180对图像组成的新批。这保证了网络是在大量的随机图像对上训练的,相似和不相似的图像对的比例大致相等。
定义网络架构
Siamese网络体系结构如下图所示。
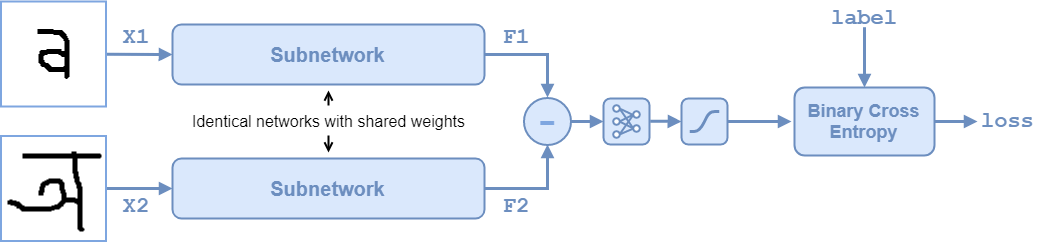
要比较两个图像,每个图像通过共享权重的两个相同子网络之一。子网络将每个105×105×1图像转换为4096维特征向量。同一类别的图像具有类似的4096维表示。每个子网络的输出特征向量通过减法和d结果通过a传递全协商具有单个输出的操作。一个sigmoid.运算将此值转换为之间的概率0和1,表示网络对图像是否相似或不同的预测。在训练过程中,利用网络预测与真标号之间的二元交叉熵损失对网络进行更新。
在这个例子中,两个相同的子网被定义为adlnetwork对象。最后一个全协商和sigmoid.操作作为对子网输出的功能操作执行。
创建子网络作为一系列的层,接受105 × 105 × 1的图像并输出大小为4096的特征向量。
为了卷积层对象,使用窄正态分布初始化权重和偏差。
为了maxpooling2dlayer.对象,设置大步2.
最后fullyConnectedLayer对象,指定输出大小为4096,并使用窄正态分布初始化权重和偏差。
图层= [imageInputLayer([105 105 1],],“名字”,'输入1',“归一化”,“没有”)卷积2dlayer(10,64,“名字”,“conv1”,“增重剂”,“窄正常”,“BiasInitializer”,“窄正常”) reluLayer (“名字”,“relu1”) maxPooling2dLayer (2“步”2,“名字”,“maxpool1”) convolution2dLayer (7128,“名字”,“conv2”,“增重剂”,“窄正常”,“BiasInitializer”,“窄正常”) reluLayer (“名字”,“relu2”) maxPooling2dLayer (2“步”2,“名字”,“maxpool2”) convolution2dLayer (4128,“名字”,“conv3”,“增重剂”,“窄正常”,“BiasInitializer”,“窄正常”) reluLayer (“名字”,'relu3') maxPooling2dLayer (2“步”2,“名字”,“maxpool3”)卷积2dlayer(5,256,“名字”,“conv4”,“增重剂”,“窄正常”,“BiasInitializer”,“窄正常”) reluLayer (“名字”,“relu4”) fullyConnectedLayer (4096,“名字”,'fc1',“增重剂”,“窄正常”,“BiasInitializer”,“窄正常”)]; lgraph=层图(层);
为了使用自定义的训练循环来训练网络并使其能够自动区分,将层图转换为dlnetwork对象。
dlnet = dlnetwork (lgraph);
为最终结果创建权重全协商手术。通过使用标准偏差为0.01的窄正态分布采样随机选择来初始化权重。
Fcweights = Dlarray(0.01 * Randn(1,4096));FCBIAS = DLARRAY(0.01 * RANDN(1,1));fcparams = struct(......“fcweights”,fcWeights,......“FcBias”,fcBias);
要使用网络,请创建函数forwardSiamese(定义在万博1manbetx辅助功能这个例子的一部分),它定义了两个子网和减法,fullyconnect,和sigmoid.操作是组合的forwardSiamese接受网络,结构中包含的参数全协商操作和两个训练图像forwardSiamese函数输出关于两个图像相似性的预测。
定义模型渐变函数
创建函数模型梯度(定义在万博1manbetx辅助功能这个例子的一部分)。的模型梯度函数采用暹罗子网数据链路,参数结构全协商操作,以及一小批输入数据X1和X2与他们的标签pairLabels.该函数返回损耗值和损耗相对于网络的可学习参数的梯度。
暹罗网络的目的是区别两种输入X1和X2.网络的输出是概率0和1,其中值更接近0表示预测的图像是不同的,并且值更接近1图像是相似的。损失由预测分数与真实标号值之间的二元交叉熵给出:
真正的标签 可以是0或1 是预测的标签。
指定培训选项
指定在培训期间使用的选项。训练10000次迭代。
数量=10000;最小批量大小=180;
指定ADAM优化的选项:
将学习速率设置为
0.00006.初始化尾随平均梯度和尾随平均梯度平方衰减率
[]对于这两个数据链路和fcparams..设置梯度衰减因子为
0.9和平方梯度衰减因子到0.99.
学习率=6e-5;trailingAvgSubnet=[];trailingAvgSqSubnet=[];trailingAvgParams=[];trailingAvgSqParams=[];梯度衰减=0.9;梯度衰减=0.99;
在GPU上训练(如果有的话)。使用GPU需要并行计算工具箱™和支持的GPU设备。万博1manbetx有关支持的设备的信息,请参见万博1manbetxGPU支万博1manbetx持情况(并行计算工具箱).如果需要自动检测是否有可用的图形处理器,并将相关数据放置在该图形处理器上,请设置executionEnvironment到“汽车”。如果您没有GPU,或不想使用GPU进行培训,请将值设置为executionEnvironment到“cpu”.要确保使用GPU进行训练,请设置executionEnvironment到“gpu”.
executionEnvironment =“汽车”;
要监控培训进度,可以在每次迭代后绘制培训损失。创建变量阴谋那个包含“培训进度”.如果您不想绘制培训进度,请将此值设置为“没有”.
情节=“培训进度”;
初始化训练损失进度图的绘图参数。
比例=16/9;如果情节= =“培训进度”trainingPlot =图;trainingPlot.Position (3) = plotRatio * trainingPlot.Position (4);trainingPlot。可见=“上”;TrainingPlotaxes = GCA;LineloSstrain =动画线(培训架);xlabel(培训帆布,“迭代”)ylabel(训练绘图轴,“损失”)标题(培训绘图轴,“训练中的损失”)结束
列车模型
使用自定义训练循环训练模型。在每次迭代时循环训练数据并更新网络参数。
每一次迭代:
提取一批图像对和标签使用
getsiameSebatch.在节中定义的函数创建批量图像对.将数据转换为
dlarray具有底层类型的对象单身的并指定尺寸标签'SSCB'(空间、空间、通道、批处理)的图像数据和“CB”(通道,批次)的标签。对于GPU培训,将数据转换为
GPUArray.对象。使用
dlfeval.和模型梯度函数。使用
阿达木酯函数。
%循环在迷你批次。为迭代=1:numIterations%提取小批图像对和对标签(X1, X2, pairLabels] = getSiameseBatch (imdsTrain miniBatchSize);%转换小批数据到美元。指定尺寸标签%'SSCB'(空间,空间,通道,批量)用于图像数据dlX1 = dlarray(单(X1)、'SSCB');dlX2 = dlarray(单(X2),'SSCB');%如果在GPU上训练,则将数据转换为gpuArray。如果(execultenvironment ==.“汽车”&& canUseGPU) || executionEnvironment ==“gpu”dlX1 = gpuArray (dlX1);dlX2 = gpuArray (dlX2);结束%评估模型梯度和生成器状态使用的% dlfeval和模型梯度函数%的例子。[gradientsSubnet,GradientsSparams,loss]=dlfeval(@modelGradients,dlnet,fcParams,dlX1,dlX2,pairLabels);lossValue=double(聚集(提取数据(丢失));%更新暹罗子网络参数。[dlnet,trailingAvgSubnet,trailingAvgSubnet]=......数据更新(dlnet、梯度SSUBNET、,......trailingAvgSubnet trailingAvgSqSubnet,迭代,learningRate、gradDecay gradDecaySq);%更新fullyconnect参数。[fcParams, trailingAvgParams trailingAvgSqParams] =......adamupdate (fcParams gradientsParams,......trailingAvgParams trailingAvgSqParams,迭代,learningRate、gradDecay gradDecaySq);%更新培训损失进度图。如果情节= =“培训进度”添加点(lineLossTrain、迭代、LosValue);结束现在抽;结束

评估网络的准确性
下载并解压缩Omniglot测试数据集。
url =“https://github.com/brendenlake/omniglot/raw/master/python/images_evaluation.zip”;downloadFolder = tempdir;文件名= fullfile (downloadFolder,“images_evaluation.zip”);dataFolderTest = fullfile (downloadFolder,'images_evaluation');如果~exist(dataFolderTest,“dir”) disp ('正在下载Omniglot测试数据(3.2MB)…') websave(文件名,url);解压缩(文件名,downloadFolder);结束disp (“测试数据下载”。)
测试数据下载。
使用使用的图像数据存储将测试数据加载imageDatastore函数。手动指定标签,方法是从文件名中提取标签并设置标签财产。
imdstest = imageageataStore(DataFoldertest,......“包含子文件夹”符合事实的......“标签源”,“没有”);files = imdstest.files;部分=分裂(文件、filesep);标签=加入(部分(:,(end-2): (end-1)),'_'); imdsTest.Labels=分类(标签);
测试数据集包含20个字母,与网络培训的其他字母不同。总计,测试数据集中有659种不同的类。
numclasses = numel(唯一(imdstest.labels))
numClasses = 659
为了计算网络的准确性,创建一组5个随机的小批量测试对。使用暹罗人函数(在万博1manbetx辅助功能来评估网络预测并计算迷你批次的平均准确率。
精度=零(1,5);accuracyBatchSize=150;为i=1:5%提取小批图像对和对标签[XAcc1、XAcc2、pairLabelsAcc]=GetSiamesBatch(imdsTest、accuracyBatchSize);%转换小批数据到美元。指定尺寸标签%用于图像数据的“SSCB”(空间、空间、通道、批次)。dlXAcc1=dlarray(单个(XAcc1),'SSCB');dlxacc2 = dlarray(单个(xacc2),'SSCB');%如果使用GPU,则将数据转换为gpuArray。如果(execultenvironment ==.“汽车”&& canUseGPU) || executionEnvironment ==“gpu”dlXAcc1 = gpuArray (dlXAcc1);dlXAcc2 = gpuArray (dlXAcc2);结束使用训练有素的网络评估预测海底= predictSiamese (dlnet fcParams、dlXAcc1 dlXAcc2);%将预测转换为二进制0或1Y=聚集(提取数据(DY));Y=圆形(Y);%计算小靶的平均精度精度(i) = sum(Y == pairLabelsAcc)/accuracyBatchSize;结束所有小批量的计算精度averageAccuracy =意味着(准确性)* 100
averageAccuracy = 88.6667
显示带有预测的图像测试集
在视觉上检查网络是否正确识别类似和不同的对,创建一小批图像对进行测试。使用预测isiamese函数来获取每个测试对的预测。使用预测,概率得分和标签显示一对图像,指示预测是否正确或不正确。
testBatchSize=10;[XTest1,XTest2,pairLabelTest]=getSiamesBatch(imdsTest,testBatchSize);将测试批数据转换为美元。指定尺寸标签% 'SSCB'(空间,空间,通道,批处理)用于图像数据和'CB'标签的%(通道,批)dlXTest1 = dlarray(单(XTest1),'SSCB');dlXTest2 = dlarray(单(XTest2),'SSCB');%如果使用GPU,则将数据转换为gpuArray如果(execultenvironment ==.“汽车”&& canUseGPU) || executionEnvironment ==“gpu”dlXTest1 = gpuArray (dlXTest1);dlXTest2 = gpuArray (dlXTest2);结束计算预测的概率dlyscore = predictsiamese(dlnet,fcparams,dlxtest1,dlxtest2);yscore =聚集(提取数据(Dlyscore));%将预测转换为二进制0或1YPred=圆形(YScore);%提取数据以绘图xtest1 =提取数据(dlxtest1);xtest2 =提取数据(dlxtest2);%使用预测标签和预测分数打印图像testingPlot =图;testingPlot.Position (3) = plotRatio * testingPlot.Position (4);testingPlot。可见=“上”;为i=1:numel(成对标签测试)如果YPred(i)=1=“相似”;其他的predLabel =“不同”;结束如果pairLabelsTest(i) == YPred(i) testStr =“\bf\color{darkgreen}正确\rm\newline”;其他的testStr =“\bf\color{red}不正确\rm\newline”;结束次要情节(2、5、我)imshow ([XTest1 (::,:, i) XTest2(::,:,我)]);标题(testStr +{黑}\颜色预测:“+ predLabel +“\ newlineScore:“+ YScore(我));结束
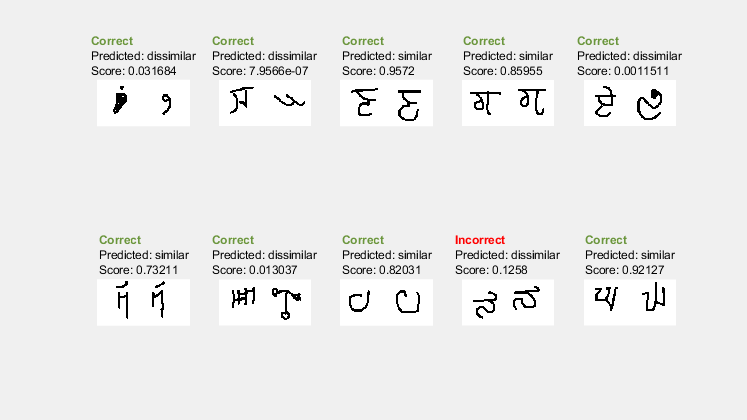
该网络能够比较测试图像,以确定它们的相似性,即使这些图像都没有在训练数据集。
万博1manbetx辅助功能
用于训练和预测的模型函数
这个函数forwardSiamese用于网络训练。函数定义了子网和全协商和sigmoid.业务结合起来形成了完整的连体网络。forwardSiamese接受网络结构和两幅训练图像,并输出关于两幅图像相似度的预测。在本例中,函数forwardSiamese章节里有介绍吗定义网络架构.
作用Y=ForwardSiames(dlnet、fcParams、dlX1、dlX2)% forwardSiamese接受网络和一对训练图像,并返回a%预测成对相似(接近1)或%不相似(接近0)。在训练期间使用前暹罗语。%通过双子网传递第一张图像F1=正向(dlnet,dlX1);F1=乙状结肠(F1);将第二个映像通过孪生子网F2 =前进(dlnet dlX2);F2 =乙状结肠(F2);%减去特征向量Y = abs(F1 - F2);%通过全连接操作传递结果Y = fullyconnect (Y, fcParams.FcWeights, fcParams.FcBias);%转换为0到1之间的概率。y = sigmoid(y);结束
这个函数暹罗人使用经过训练的网络对两幅图像的相似度进行预测。函数与函数相似forwardSiamese,前面定义。然而,暹罗人使用预测功能与网络而不是向前函数,因为一些深层学习层在训练和预测期间的行为不同暹罗人章节里有介绍吗评估网络的准确性.
作用dlX1, Y = predictSiamese (dlnet fcParams dlX2)%predictsiamese接受网络和一对图像,并返回a对两者相似概率的预测%(接近1)%或不同(接近0)。在预测时使用predictSiamese。%通过双子网传递第一张图像F1=预测(dlnet,dlX1);F1=乙状结肠(F1);将第二个映像通过孪生子网F2=预测(dlnet,dlX2);F2=乙状结肠(F2);%减去特征向量Y = abs(F1 - F2);%通过全连接操作传递结果Y = fullyconnect (Y, fcParams.FcWeights, fcParams.FcBias);%转换为0到1之间的概率。y = sigmoid(y);结束
模型梯度函数
这个函数模型梯度的暹罗dlnetwork对象网,一对迷你批量输入数据X1和X2,以及表示它们是相似还是不同的标签。该函数返回关于网络中可学习参数的损失梯度和预测与地面真实之间的二元交叉熵损失。在本例中,函数模型梯度章节里有介绍吗定义模型渐变函数.
作用[梯度SSUBNET、梯度SPARAM、损失]=模型梯度(dlnet、fcParams、dlX1、dlX2、配对标签)%modelGradients函数计算两个变量之间的二进制交叉熵损失%配对图像,并返回损失和损失相对于图像的梯度%网络可学习参数%通过网络传递图像对Y=向前连体(dlnet、fcParams、dlX1、dlX2);%计算二元交叉熵损失损失= binarycrossentropy (Y, pairLabels);计算损失相对于网络可学习的梯度%的参数[gradientsSubnet,GradientsSparams]=dlgradient(损失,dlnet.Learnables,fcParams);结束作用损失= binarycrossentropy (Y, pairLabels)%binarycrossentropy接受网络的预测y,真实% label和pairLabels,并返回二进制交叉熵损失值。%获取预测的精度,以防止由于浮动导致的错误%点精度精度= underlyingType (Y);%将小于浮点精度的值转换为eps。Y(Y < eps(precision)) = eps(precision);%转换1-eps和1到1 eps之间的值。Y(Y > 1 - eps(precision)) = 1 - eps(precision);%计算每对二进制交叉熵损失损失=-成对标签。*对数(Y)-(1-成对标签)。*对数(1-Y);对minibatch和normalize中的所有对求和。损失=(亏损)/元素个数之和(pairLabels);结束
创建批量图像对
以下函数根据其标签创建类似或不相似的随机图像。在本例中,函数getsiameSebatch.章节里有介绍吗创建相似和不同的图像对。
作用[X1,X2,pairLabels]=GetSiamesBatch(imds,miniBatchSize)%getsiamesebatch返回一个随机选择的批处理或配对图像。在%平均值,这个函数产生一个相似和不同的平衡集%成对的。miniBatchSize pairLabels = 0 (1);imgSize =大小(readimage (imd, 1));if ([imgSize 1 miniBatchSize] = 0); / /指定一个最小的字节[imgSize 1 miniBatchSize] = 0; / /设置一个最小的批次为i = 1: minbatchsize choice = rand(1);如果选择<0.5 [Biredx1,Biredx2,Biaplabels(i)] = GetSimilarPair(IMDS.Labels);其他的[pairIdx1, pairIdx2 pairLabels (i)) = getDissimilarPair (imds.Labels);结束X1(:::,:,i)= IMDS.ReadImage(BiredX1);x2(::,:,i)= imds.readimage(Biredx2);结束结束作用[pairIdx1, pairIdx2 pairLabel] = getSimilarPair (classLabel)% getSimilarSiamesePair返回图像的随机索引对%属于同一类且相似的对标签=1。找到所有唯一的类。类=唯一(类标签);%选择一个随机选择的类,这将用于获得类似的对。classChoice=randi(numel(classes));%找到所选类别中所有观察结果的索引。idx =找到(classLabel = =类(classChoice));%从所选的类中随机选择两张不同的图片。BiredxChoice = Randperm(Numel(IDXS),2);BiredX1 = IDXS(BiredXchoice(1));Biredx2 = IDXS(BiredXchoice(2));Biaplabel = 1;结束作用[pairIdx1 pairIdx2,标签]= getDissimilarPair (classLabel)% getDissimilarSiamesePair返回图像的随机索引对%是在不同的类和不同的对标签= 0。找到所有唯一的类。类=唯一(类标签);%随机选择两个不同的类,将用于得到一个不同的对。classesChoice = randperm(元素个数(类),2);%从第一和第二类中找到所有观察的指数。idxs1=find(classLabel==classes(classesChoice(1));idxs2=find(classLabel==classes(classesChoice(2));%从每个类中随机选择一张图片。Biredx1Choice = RANDI(NUMER(IDXS1));Biredx2Choice = RANDI(NUMER(IDXS2));BiredX1 = IDXS1(BiredX1Choice);BiredX2 = IDXS2(BiredX2Choice);标签= 0;结束
工具书类
[1] Bromley,J.,I.Guyon,Y.LeCun,E.Säcker和R.Shah。“使用“暹罗”时滞神经网络的签名验证。“在第六次国际神经信息处理系统会议(NIPS 1993),1994年,PP737-744中的诉讼程序中。可用使用“暹罗”时滞神经网络的签名验证在NIPS诉讼网站上。
[2] Y.温佩格和H舒茨。”用于释义识别的卷积神经网络。“2015年ACL北美分会2015年会议记录,pp901-911。可在用于复述识别的卷积神经网络在ACL文选网站上
[3] Lake, b.m., Salakhutdinov, R.和Tenenbaum, J. B.”通过概率计划诱导学习人类级概念。《科学》,350(6266),(2015)pp1332-1338。
[4] Koch,G.,Zemel,R.,和Salakhutdinov,R.(2015年)。"用于单幅图像识别的暹罗神经网络“。在第32届国际机械学习会议上的诉讼程序中,37(2015)。可用用于一次性图像识别的暹罗神经网络在ICML'15网站上。
另请参阅
dlarray|dlgradient|dlfeval.|dlnetwork|阿达木酯
相关话题
您还可以从以下列表中选择网站:
