训练残差网络进行图像分类
这个例子展示了如何创建一个有剩余连接的深度学习神经网络,并在CIFAR-10数据上训练它。剩余连接是卷积神经网络结构中的一个常用元素。使用剩余连接可以改善网络中的梯度流,并能够对更深层次的网络进行培训。
对于许多应用程序,使用由简单的层序列组成的网络就足够了。然而,一些应用程序需要具有更复杂的图结构的网络,其中层可以有来自多个层的输入和到多个层的输出。这些类型的网络通常被称为有向无环图(DAG)网络。剩余网络是一种DAG网络,它具有绕过主网络层的剩余(或快捷)连接。剩余连接使得参数梯度更容易从输出层传播到网络的较早层,这使得训练较深的网络成为可能。这种增加的网络深度可以在更困难的任务中产生更高的准确性。
要创建和训练具有图形结构的网络,请遵循以下步骤。
创建一个
LayerGraph对象使用layerGraph。该层图形指定网络架构。你可以创建一个空层图,然后添加图层到它。还可以直接从网络层的阵列创建的层图。在这种情况下,layerGraph将数组中的层一个接一个地连接起来。使用添加层以该层图形
addLayers,然后使用以下命令从图中删除层removeLayers。使用以下命令将层连接到其他层
connectLayers,并断开与其他层的连接disconnectLayers。通过绘制网络架构
情节。使用以下工具培训网络
trainNetwork。训练好的网络是DAGNetwork对象。对新数据进行分类和预测
分类和预测。
您还可以加载预训练的网络进行图像分类。有关更多信息,请参见预先训练的深度神经网络。
准备数据
下载CIFAR-10数据集[1]。数据集包含60,000张图像。每个图像大小为32×32,有三个颜色通道(RGB)。数据集的大小为175mb。根据您的internet连接情况,下载过程可能需要一些时间。
datadir = tempdir;downloadCIFARData (datadir);
下载CIFAR-10数据集(175 MB)。这可能需要一段时间…完成。
将CIFAR-10训练和测试图像加载为4-D阵列。训练集包含50,000张图像,测试集包含10,000张图像。使用CIFAR-10测试映像进行网络验证。
[XTrain, YTrain XValidation YValidation] = loadCIFARData (datadir);
可以使用以下代码显示训练图像的随机样本。
图;idx = randperm(大小(XTrain, 4), 20);我= imtile (XTrain (:,:,:, idx),“ThumbnailSize”(96、96));imshow (im)
创建一个augmentedImageDatastore目的用于网络培训。在训练过程中,数据存储沿垂直轴随机翻转训练图像,并在水平和垂直方向随机转换最多4个像素。数据扩充有助于防止网络过度拟合和记忆训练图像的准确细节。
imageSize = [32 32 3];pixelRange = [-4 4];imageAugmenter = imageDataAugmenter (...'RandXReflection',真的,...“RandXTranslation”pixelRange,...“RandYTranslation”,pixelRange);augimdsTrain = augmentedImageDatastore(图象尺寸、XTrain YTrain,...“DataAugmentation”imageAugmenter,...“OutputSizeMode”,“randcrop”);
定义网络体系结构
剩余的网络架构由以下组件组成:
与卷积,批次归一化,和RELU层A主枝依次连接。
剩余的连接绕过了总分支的卷积单元。剩余连接和卷积单元的输出是逐元素添加的。当激活的大小改变时,剩余的连接也必须包含1乘1的卷积层。剩余的连接使得参数梯度更容易地从输出层流向网络的较早的层,这使得训练较深的网络成为可能。
创建主要分支
首先创建网络的主分支。主分支包含五个部分。
包含图像输入层和与激活的初始卷积的初始部分。
具有不同大小特征的卷积层的三个阶段(32×32、16×16和8×8)。每个阶段都包含N卷积的单位。在这个例子的这一部分,N = 2。每个卷积单元包含两个具有激活的3×3卷积层。的
netWidth参数是网络的宽度,定义为过滤器在网络的第一阶段中的卷积层的数量。在第二和第三阶段在第一卷积单元由两个因素下采样的空间尺寸。为了保持在每个卷积层大致整个网络相同的所需的计算量,由两个因素每次执行空间降采样时间增加的过滤器的数量。最后一节介绍了全局平均池、全连接、softmax和分类层。
使用convolutionalUnit (numF、跨步、标签)创建一个卷积单元。numF是在每一层中的卷积滤波器的数量,步为本单元第一卷积层的stride,和标签是一个字符数组,用于在层名称之前添加字符。的convolutionalUnit函数在示例的末尾定义。
为所有层提供唯一的名称。卷积单元中的各层都有以字母开头的名称“SjUk”,在那里j舞台索引是和吗k为该阶段内卷积单位的索引。例如,“S2U1”为第2阶段第1单元。
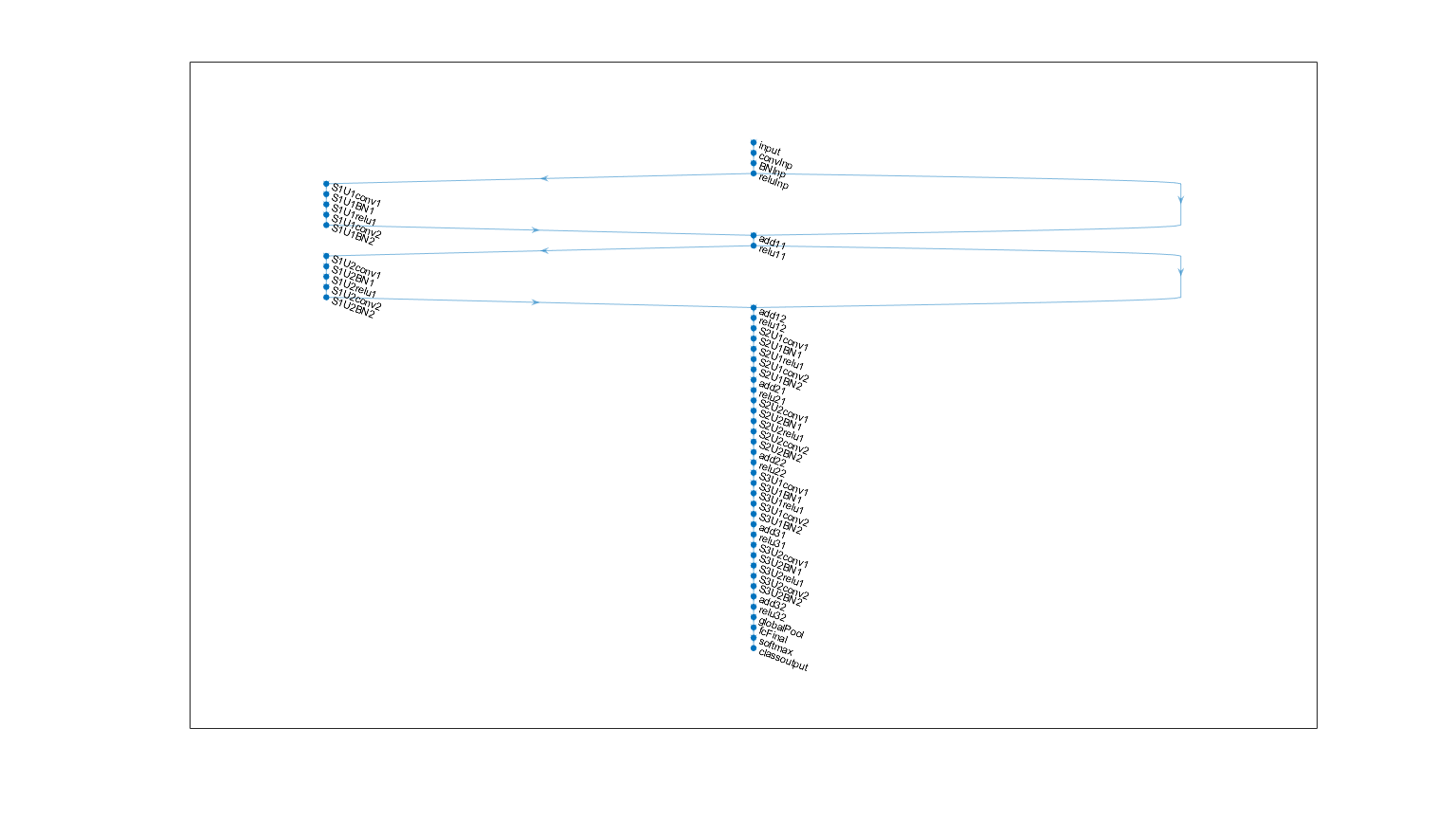
netWidth = 16;图层= [imageInputLayer([32 32 3]),“名字”,“输入”)convolution2dLayer (3 netWidth“填充”,“相同”,“名字”,“convInp”)batchNormalizationLayer (“名字”,“BNInp”)reluLayer (“名字”,“reluInp”)convolutionalUnit (netWidth 1“S1U1”)additionLayer (2“名字”,“add11”)reluLayer (“名字”,“relu11”)convolutionalUnit (netWidth 1“S1U2”)additionLayer (2“名字”,“add12”)reluLayer (“名字”,'relu12')convolutionalUnit (2 * netWidth 2“S2U1”)additionLayer (2“名字”,“add21”)reluLayer (“名字”,“relu21”)convolutionalUnit (2 * netWidth 1“S2U2”)additionLayer (2“名字”,“add22”)reluLayer (“名字”,“relu22”)convolutionalUnit (4 * netWidth 2“S3U1”)additionLayer (2“名字”,“add31”)reluLayer (“名字”,“relu31”)convolutionalUnit (4 * netWidth 1“S3U2”)additionLayer (2“名字”,“add32”)reluLayer (“名字”,“relu32”)averagePooling2dLayer (8,“名字”,“globalPool”)fullyConnectedLayer (10“名字”,“fcFinal”)softmaxLayer (“名字”,“softmax”)classificationLayer (“名字”,“classoutput”));
从层数组中创建一个层图。layerGraph连接所有层层按顺序。绘制层图。
lgraph = layerGraph(层);图(“单位”,“归一化”,'位置',[0.2 0.2 0.6 0.6]);情节(lgraph);

创建剩余连接
在卷积单元周围添加剩余连接。大多数剩余连接不执行任何操作,只是简单地将元素添加到卷积单元的输出中。
方法创建剩余连接“reluInp”到“add11”层。因为您在创建层时将添加层的输入数量指定为2,所以该层有两个具有名称的输入“三机”和“in2”。第一个卷积单元的最后一层已经连接到“三机”输入。然后,添加层将第一个卷积单元的输出和“reluInp”层。
用同样的方法,连接“relu11”层的第二个输入“add12”层。通过绘制层图,检查您是否正确地连接了层。
lgraph = connectLayers (lgraph,“reluInp”,“add11 / in2”);lgraph = connectLayers (lgraph,“relu11”,“add12 / in2”);图(“单位”,“归一化”,'位置',[0.2 0.2 0.6 0.6]);情节(lgraph);
当卷积单元中的层激活改变大小时(即当它们在空间上向下采样和在通道维度上向上采样时),剩余连接中的激活也必须改变大小。通过使用1×1的卷积层及其批处理规范化层来更改剩余连接中的激活大小。
skip1 = [convolution2dLayer(1,2*netWidth),“步”2,“名字”,“skipConv1”)batchNormalizationLayer (“名字”,“skipBN1”));lgraph = addLayers (lgraph skip1);lgraph = connectLayers (lgraph,'relu12',“skipConv1”);lgraph = connectLayers (lgraph,“skipBN1”,“add21 / in2”);
在网络的第二阶段添加身份连接。
lgraph = connectLayers (lgraph,“relu21”,“add22 / in2”);
将第二阶段和第三阶段之间的剩余连接的激活大小改变为1 * 1的卷积层及其批处理归一化层。
skip2 = [convolution2dLayer(1,4*netWidth),“步”2,“名字”,“skipConv2”)batchNormalizationLayer (“名字”,“skipBN2”));lgraph = addLayers (lgraph skip2);lgraph = connectLayers (lgraph,“relu22”,“skipConv2”);lgraph = connectLayers (lgraph,“skipBN2”,“add31 / in2”);
添加最后一个标识连接并绘制最终的层图。
lgraph = connectLayers (lgraph,“relu31”,“add32 / in2”);图(“单位”,“归一化”,'位置',[0.2 0.2 0.6 0.6]);情节(lgraph)

创建更深层次的网络
要为任意深度和宽度的CIFAR-10数据创建具有剩余连接的层图,请使用支持函数万博1manbetxresidualCIFARlgraph。
lgraph = residualCIFARlgraph (netWidth numUnits unitType)为带有剩余连接的CIFAR-10数据创建一个层图。
netWidth为网络宽度,定义为网络的前3×3个卷积层中滤波器的个数。numUnits是网络主要分支中卷积单位的数量。因为网络由三个阶段组成,每个阶段都有相同数量的卷积单元,numUnits必须是3的整数倍。unitType卷积单位的类型是否指定为“标准”或“瓶颈”。一个标准的卷积单元由2个3×3的卷积层。甲瓶颈卷积单元由三个卷积层:1×1层在通道尺寸,一个3×3的卷积层下采样,和一个1×1层在通道尺寸上采样。因此,瓶颈卷积单元具有比标准单元50%以上的卷积层,但只有空间3×3的卷积数目的一半。两个单元类型具有类似的计算复杂性,但使用的瓶颈单元时的功能中的残余连接传播的总数是大四倍。总深度,定义为连续的卷积和完全连接层的最大数目是2 *numUnits+ 2用于标准单位的网络和3*numUnits对于有瓶颈单位的网络+ 2。
创建一个包含9个标准卷积单元(每个阶段3个单元)和16个宽度的剩余网络。网络总深度为2*9+2 = 20。
numUnits = 9;netWidth = 16;lgraph = residualCIFARlgraph (netWidth numUnits,“标准”);图(“单位”,“归一化”,'位置',[0.1 0.1 0.8 0.8]);情节(lgraph)

列车网络的
指定培训选项。80年代的网络培训。选择一个与迷你批大小成比例的学习率,并在60个epoch后将学习率降低10倍。使用验证数据每epoch验证一次网络。
miniBatchSize = 128;learnRate = 0.1 * miniBatchSize / 128;valFrequency =地板(大小(XTrain 4) / miniBatchSize);选择= trainingOptions (“个”,...“InitialLearnRate”learnRate,...“MaxEpochs”,80,...“MiniBatchSize”miniBatchSize,...“VerboseFrequency”valFrequency,...“洗牌”,“every-epoch”,...“阴谋”,“训练进步”,...“详细”假的,...“ValidationData”{XValidation, YValidation},...“ValidationFrequency”valFrequency,...“LearnRateSchedule”,“分段”,...“LearnRateDropFactor”,0.1,...“LearnRateDropPeriod”、60);
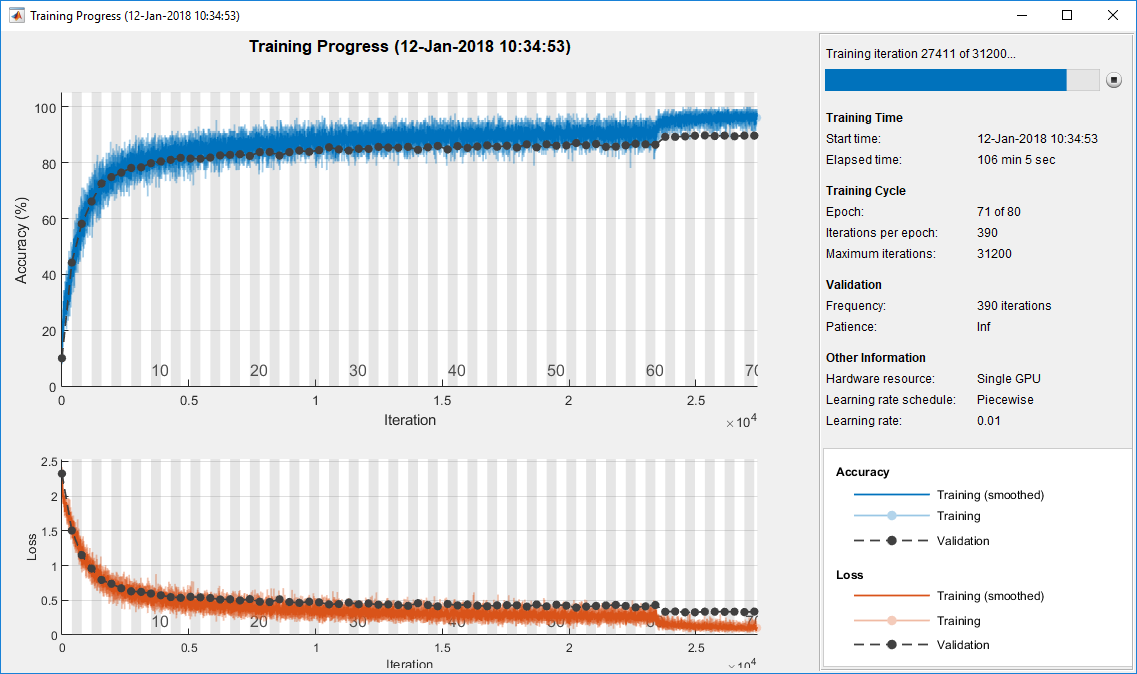
培训网络使用trainNetwork,设置doTraining旗帜真正的。否则,加载预训练网络。一个良好的GPU训练网络大约需要两个小时。如果没有GPU,再培训需要更长的时间。
doTraining = false;如果doTraining trainedNet = trainNetwork(augimdsTrain,lgraph,options);其他的负载(“cifarnet - 20 - 16. -垫”,“trainedNet”);结束
评估培训网络
在训练集(不增加数据)和验证集上计算网络的最终精度。
(YValPred,聚合氯化铝)= (trainedNet XValidation)进行分类;验证错误=均值(YValPred ~= YValidation);YTrainPred =分类(trainedNet XTrain);trainError =均值(YTrainPred ~= YTrain);disp (“训练误差:+ trainError * 100 +“%”)
训练误差:2.862%
disp ("验证错误:"+ validationError * 100 +“%”)
验证错误:9.76%
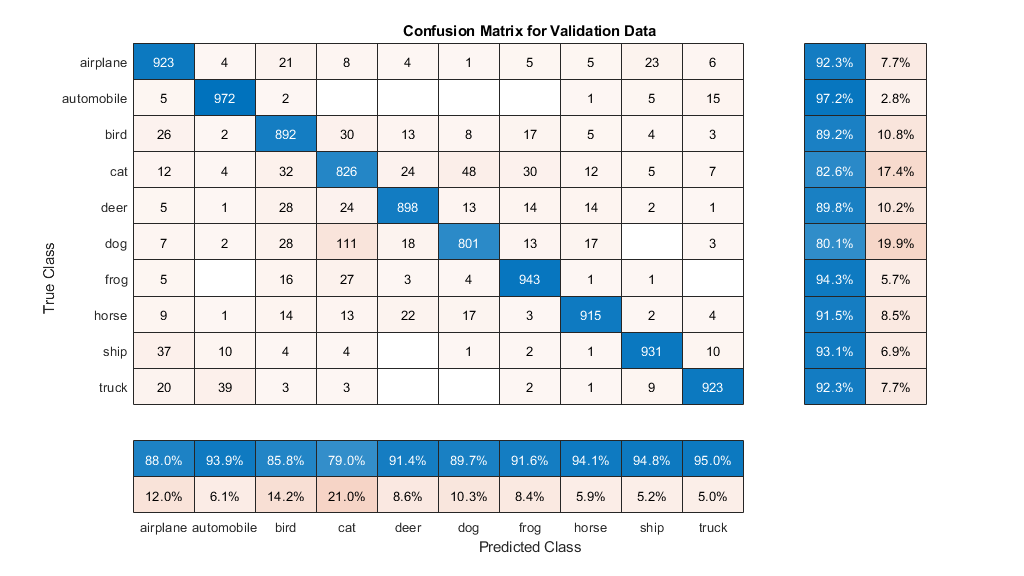
绘制混淆矩阵。通过使用列和行摘要显示每个类的精度和召回率。网络最常把猫和狗混淆起来。
图(“单位”,“归一化”,'位置',[0.2 0.2 0.4 0.4]);厘米= confusionchart (YValidation YValPred);厘米。Title =“验证数据的混淆矩阵”;cm.ColumnSummary =“column-normalized”;厘米。RowSummary =“row-normalized”;
您可以使用以下代码显示9个测试图像的随机样本,以及它们的预测类和这些类的概率。
图idx = randperm(size(XValidation,4),9);为i = 1:元素个数(idx)次要情节(3 3 i) imshow (XValidation (:,:,:, idx(我)));概率= num2str (100 * max(聚合氯化铝(idx(我),:)),3);predClass = char (YValPred (idx (i)));标题([predClass,”、“概率,“%”])结束
convolutionalUnit (numF、跨步、标签)创建一个包含两个卷积层和相应的批处理标准化和ReLU层的层数组。numF为卷积滤波器的个数,步为第一卷积层的步长,标签是所有层名称的前缀标签。
函数layer = convolution2dLayer(3,numF, stride,tag)“填充”,“相同”,“步”步,“名字”,标签,“conv1”])batchNormalizationLayer (“名字”,标签,“BN1”])reluLayer (“名字”,标签,“relu1”numF]) convolution2dLayer(3日,“填充”,“相同”,“名字”,标签,“conv2”])batchNormalizationLayer (“名字”,标签,“BN2”)));结束
参考
[1]Krizhevsky,亚历克斯。“从微小的图像中学习多层特征。”(2009). https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
何,开明,张向宇,任少卿,孙健。“用于图像识别的深度剩余学习”。在IEEE计算机视觉和模式识别会议记录,770 - 778页。2016.
另请参阅
analyzeNetwork|layerGraph|trainNetwork|trainingOptions
相关的话题
你也可以从以下列表中选择一个网站:
