贝叶斯随机搜索变量的选择gydF4y2Ba
这个例子展示了如何实现随机搜索变量选择(科学)、贝叶斯线性回归模型的变量选择技术。gydF4y2Ba
介绍gydF4y2Ba
考虑这个贝叶斯线性回归模型。gydF4y2Ba
回归系数gydF4y2Ba 。gydF4y2Ba
。gydF4y2Ba
的干扰gydF4y2Ba 。gydF4y2Ba
干扰方差gydF4y2Ba ,在那里gydF4y2Ba 逆伽马分布的形状gydF4y2Ba一个gydF4y2Ba和规模gydF4y2BaBgydF4y2Ba。gydF4y2Ba
变量选择的目标是只包括那些支持的预测数据在最后的回归模型。万博1manbetx这样做的一个方法是分析gydF4y2Ba 排列的模型,称为gydF4y2Ba政权gydF4y2Ba,包括模型的系数不同。如果gydF4y2Ba 很小,那么你可以适合所有排列的数据模型,然后比较模型通过使用性能的措施,如拟合优度(例如,Akaike信息标准)或预测均方误差(MSE)。然而,即使是温和的值gydF4y2Ba ,估计所有的排列模型效率低下。gydF4y2Ba
变量的贝叶斯视图选择是一个系数,被排除在一个模型中,有一个堕落的后验分布。即排除系数狄拉克δ分布,其概率质量集中在零。绕过退化变量引起的复杂性,之前被排除系数是高斯分布均值为0,方差小,例如gydF4y2Ba 。因为之前集中在零附近,后还必须集中在零附近。gydF4y2Ba
前的系数被包括gydF4y2Ba ,在那里gydF4y2Ba 足够远离零和gydF4y2Ba 通常是零。这个框架意味着每个系数的之前是一个高斯混合模型。gydF4y2Ba
考虑到潜在的、二进制随机变量gydF4y2Ba ,gydF4y2Ba ,比如:gydF4y2Ba
表明gydF4y2Ba 这gydF4y2Ba 包括在模型中。gydF4y2Ba
表明gydF4y2Ba 这gydF4y2Ba 是排除在模型。gydF4y2Ba
。gydF4y2Ba
的样本空间gydF4y2Ba 的基数gydF4y2Ba ,每个元素都是一个gydF4y2Ba 0或1 - d向量。gydF4y2Ba
是一种小型、正数和gydF4y2Ba 。gydF4y2Ba
系数gydF4y2Ba 和gydF4y2Ba ,gydF4y2Ba 是独立的,先天的。gydF4y2Ba
科学的一个目标是评估后政权概率gydF4y2Ba ,估计,确定相应的系数是否应该被包括在模型中。鉴于gydF4y2Ba ,gydF4y2Ba 是条件独立的数据。因此,对于gydF4y2Ba ,这个方程表示完整的条件概率变量的后验分布gydF4y2BakgydF4y2Ba包含在模型:gydF4y2Ba
在哪里gydF4y2Ba 与标量高斯分布的pdf的意思吗gydF4y2Ba 和方差gydF4y2Ba 。gydF4y2Ba
计量经济学工具箱™有两个贝叶斯线性回归模型,指定科学的先验分布:gydF4y2BamixconjugateblmgydF4y2Ba和gydF4y2BamixsemiconjugateblmgydF4y2Ba。早些时候提出的框架描述的先知先觉gydF4y2BamixconjugateblmgydF4y2Ba模型。模型之间的差异gydF4y2Ba
和gydF4y2Ba
是独立的,先天的吗gydF4y2BamixsemiconjugateblmgydF4y2Ba模型。因此,之前的方差gydF4y2Ba
是gydF4y2Ba
(gydF4y2Ba
)或gydF4y2Ba
(gydF4y2Ba
)。gydF4y2Ba
在您决定使用哪一个模型之前,电话gydF4y2BabayeslmgydF4y2Ba创建模型和指定hyperparameter值。万博1manbetx支持hyperparameters包括:gydF4y2Ba
拦截gydF4y2Ba,一个逻辑标量指定是否在模型中包括一个拦截。gydF4y2BaμgydF4y2Ba,一个(gydF4y2BapgydF4y2Ba+ 1)×2矩阵指定之前高斯混合的方法gydF4y2Ba 。第一列包含组件对应的方法gydF4y2Ba ,第二列包含相应的手段gydF4y2Ba 。默认情况下,所有方法都是0,它指定实现科学价值。gydF4y2BaVgydF4y2Ba,一个(gydF4y2BapgydF4y2Ba+ 1)×2矩阵指定之前高斯混合方差因素(或方差)gydF4y2Ba 。列对应的列gydF4y2BaμgydF4y2Ba。默认情况下,第一个组件的方差gydF4y2Ba10gydF4y2Ba和第二部分的方差gydF4y2Ba0.1gydF4y2Ba。gydF4y2Ba相关gydF4y2Ba,一个(gydF4y2BapgydF4y2Ba+ 1)————(gydF4y2BapgydF4y2Ba+ 1)指定的之前的相关矩阵正定矩阵gydF4y2Ba 对于这两个组件。默认是单位矩阵,这意味着回归系数是不相关的,先天的。gydF4y2Ba概率gydF4y2Ba,一个(gydF4y2BapgydF4y2Ba+ 1)- d的先验概率向量变量包含(gydF4y2Ba k = 0,…, _p_)或一个函数处理自定义函数。gydF4y2Ba 和gydF4y2Ba ,gydF4y2Ba 是独立的,先天的。然而,使用一个函数处理(gydF4y2Ba@functionnamegydF4y2Ba),您可以提供一个定制的先验分布,指定之间的依赖关系gydF4y2Ba 和gydF4y2Ba 。例如,您可以指定强制gydF4y2Ba 如果模型的gydF4y2Ba 包括在内。gydF4y2Ba
在您创建一个模型,通过它和数据gydF4y2Ba估计gydF4y2Ba。的gydF4y2Ba估计gydF4y2Ba函数使用一个吉布斯采样器样品的充分条件,并估计后验分布的特点gydF4y2Ba
和gydF4y2Ba
。同时,gydF4y2Ba估计gydF4y2Ba返回后的估计gydF4y2Ba
。gydF4y2Ba
对于这个示例,考虑创建一个预测线性模型对美国失业率。你想要一个模型,概括了。换句话说,你想最小化模型复杂性通过删除所有多余的预测和预测与失业率是不相关的。gydF4y2Ba
加载和数据预处理gydF4y2Ba
美国宏观经济数据集加载gydF4y2BaData_USEconModel.matgydF4y2Ba。gydF4y2Ba
负载gydF4y2BaData_USEconModelgydF4y2Ba
数据集包括MATLAB®时间表gydF4y2BaDataTimeTablegydF4y2Ba,其中包含14个变量测量从1947年第一季度到2009年一季度;gydF4y2BaUNRATEgydF4y2Ba美国失业率。更多细节,回车gydF4y2Ba描述gydF4y2Ba在命令行中。gydF4y2Ba
情节都在同一个图系列,但在不同的次要情节。gydF4y2Ba
图tiledlayout (4, 4)gydF4y2Ba为gydF4y2Baj = 1:尺寸(DataTimeTable, 2) nexttile情节(DataTimeTable.Time, DataTimeTable {: j});标题(DataTimeTable.Properties.VariableNames (j));gydF4y2Ba结束gydF4y2Ba
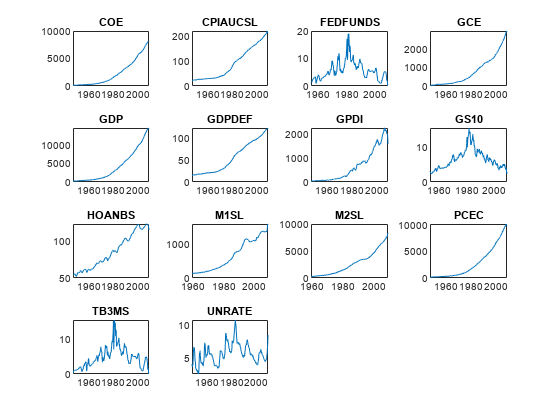
所有系列除了gydF4y2BaFEDFUNDSgydF4y2Ba,gydF4y2BaGS10gydF4y2Ba,gydF4y2BaTB3MSgydF4y2Ba,gydF4y2BaUNRATEgydF4y2Ba似乎一个指数的趋势。gydF4y2Ba
对数变换应用到这些变量与一个指数的趋势。gydF4y2Ba
hasexpotrend = ~ ismember (DataTimeTable.Properties.VariableNamesgydF4y2Ba…gydF4y2Ba(gydF4y2Ba“FEDFUNDS”gydF4y2Ba“GD10”gydF4y2Ba“TB3MS”gydF4y2Ba“UNRATE”gydF4y2Ba]);DataTimeTableLog = varfun (@log DataTimeTable,gydF4y2Ba“数据源”gydF4y2Ba,gydF4y2Ba…gydF4y2BaDataTimeTable.Properties.VariableNames (hasexpotrend));DataTimeTableLog = [DataTimeTableLoggydF4y2Ba…gydF4y2BaDataTimeTable (:, DataTimeTable.Properties.VariableNames (~ hasexpotrend)];gydF4y2Ba
DataTimeTableLoggydF4y2Ba是一个时间表gydF4y2BaDataTimeTablegydF4y2Ba,但这些变量与一个指数趋势在对数尺度。gydF4y2Ba
系数有较大震级往往占主导地位的点球套索回归目标函数。因此,它是重要的变量有类似的规模当你实现套索回归。比较在DataTimeTable变量的尺度gydF4y2Ba日志gydF4y2Ba通过绘制他们的箱形图在同一轴。gydF4y2Ba
图;箱线图(DataTimeTableLog.VariablesgydF4y2Ba“标签”gydF4y2Ba,DataTimeTableLog.Properties.VariableNames);h = gcf;h.Position (3) = h.Position (3) * 2.5;标题(gydF4y2Ba“变量盒阴谋”gydF4y2Ba);gydF4y2Ba
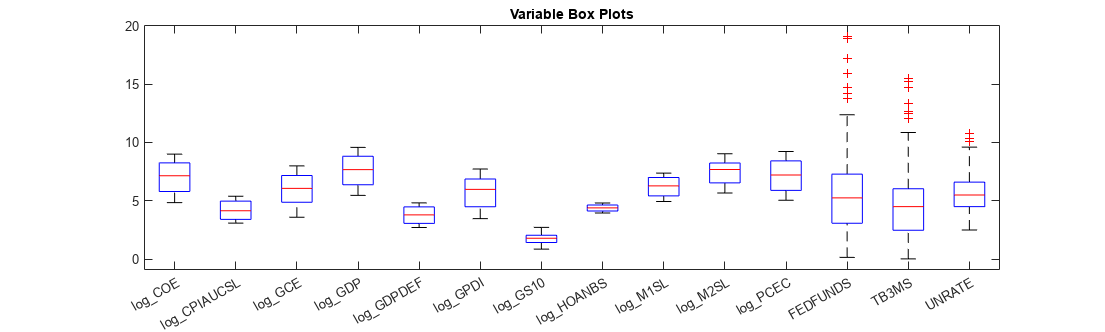
的变量都相当类似的鳞片。gydF4y2Ba
前调优高斯混合方差因素,遵循这个过程:gydF4y2Ba
分区数据估计和预测样本。gydF4y2Ba
符合模型来估计样本并指定,gydF4y2Ba ,gydF4y2Ba 和gydF4y2Ba 。gydF4y2Ba
使用拟合模型来预测响应预测地平线。gydF4y2Ba
每个模型的预测均方误差估计。gydF4y2Ba
选择最低的模型预测均方误差。gydF4y2Ba
乔治和麦克洛克提出另一种优化之前的差异gydF4y2Ba 在gydF4y2Ba[1]gydF4y2Ba。gydF4y2Ba
创建评估和预测样本变量的响应和预测数据。指定一个预测地平线的4年(16人)。gydF4y2Ba
跳频= 16;y = DataTimeTableLog。UNRATE(1:(end - fh)); yF = DataTimeTableLog.UNRATE((end - fh + 1):end); isresponse = DataTimeTable.Properties.VariableNames ==“UNRATE”gydF4y2Ba;X = DataTimeTableLog{1:(结束- fh), ~ isresponse};XF = DataTimeTableLog{(结束- fh + 1):最终,~ isresponse};p =大小(X, 2);gydF4y2Ba%的预测数量gydF4y2Bapredictornames = DataTimeTableLog.Properties.VariableNames (~ isresponse);gydF4y2Ba
创建先验贝叶斯线性回归模型gydF4y2Ba
为科学通过调用创建先验贝叶斯线性回归模型gydF4y2BabayeslmgydF4y2Ba模型类型,并指定数量的预测方差因素指标名称和组件。假设gydF4y2Ba
和gydF4y2Ba
是依赖,先天的(gydF4y2BamixconjugateblmgydF4y2Ba模型)。gydF4y2Ba
V1 = 50 (100);V2 = (0.05 0.1 0.5);numv1 =元素个数(V1);numv2 =元素个数(V2);PriorMdl =细胞(numv1 numv2);gydF4y2Ba% PreallocategydF4y2Ba为gydF4y2Bak = 1: numv2gydF4y2Ba为gydF4y2Baj = 1: numv1 V = (V1 (j) * (p + 1, - 1)的V2 (k) * 1 (p + 1, - 1)];PriorMdl {j, k} = bayeslm (p,gydF4y2Ba“ModelType”gydF4y2Ba,gydF4y2Ba“mixconjugateblm”gydF4y2Ba,gydF4y2Ba…gydF4y2Ba“VarNames”gydF4y2Bapredictornames,gydF4y2Ba“V”gydF4y2Ba,V);gydF4y2Ba结束gydF4y2Ba结束gydF4y2Ba
PriorMdlgydF4y2Ba是一个3×3单元阵列,每个单元格包含一个吗gydF4y2BamixconjugateblmgydF4y2Ba模型对象。gydF4y2Ba
情节的先验分布gydF4y2Balog_GDPgydF4y2Ba的模型gydF4y2BaV2gydF4y2Ba是0.5。gydF4y2Ba
为gydF4y2Baj = 1: numv1 [~, ~, ~ h] =情节(PriorMdl {j 3},gydF4y2Ba“VarNames”gydF4y2Ba,gydF4y2Ba“log_GDP”gydF4y2Ba);标题(sprintf (gydF4y2Ba“GDP日志,V1 = % g, V2 = % g”gydF4y2BaV1 (j), V2 (3)));h。标签= strcat (gydF4y2Ba“图”gydF4y2Banum2str (V1 (j)), num2str (V2 (3)));gydF4y2Ba结束gydF4y2Ba
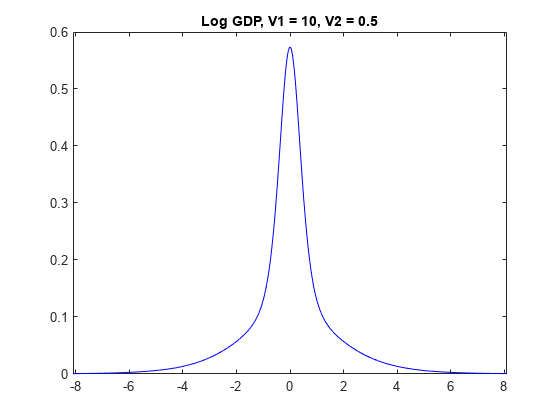
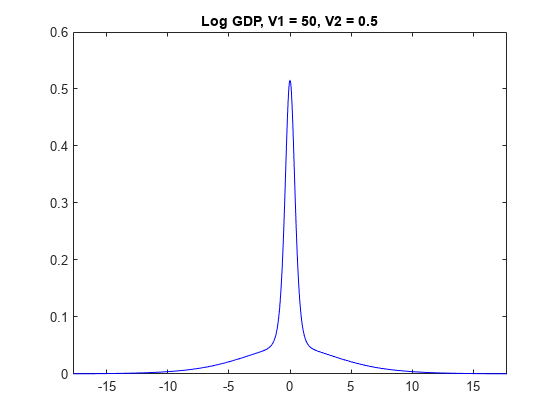
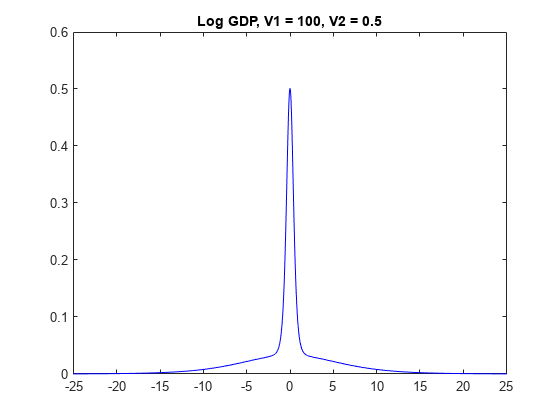
的先验分布gydF4y2Ba
有gydF4y2Baspike-and-slabgydF4y2Ba形状。当gydF4y2BaV1gydF4y2Ba很低,更多的分布集中在0,这使得该算法更难属性高β值。然而,变量算法识别重要的正规化,在算法不属性高级对应的系数。gydF4y2Ba
当gydF4y2BaV1gydF4y2Ba密度高,更远离零发生,这使得算法更容易属性非零系数重要预测因子。然而,如果gydF4y2BaV1gydF4y2Ba太高,那么重要的预测可以膨胀系数。gydF4y2Ba
执行科学变量选择gydF4y2Ba
执行科学,估计使用的后验分布gydF4y2Ba估计gydF4y2Ba。使用默认选项吉布斯采样器。gydF4y2Ba
PosteriorMdl =细胞(numv1 numv2);PosteriorSummary =细胞(numv1 numv2);rng (1);gydF4y2Ba%的再现性gydF4y2Ba为gydF4y2Bak = 1: numv2gydF4y2Ba为gydF4y2Baj = 1: numv1 PosteriorMdl {j, k}, PosteriorSummary {j, k}] =估计(PriorMdl {j, k}, X, y,gydF4y2Ba…gydF4y2Ba“显示”gydF4y2Ba、假);gydF4y2Ba结束gydF4y2Ba结束gydF4y2Ba
每个细胞在gydF4y2BaPosteriorMdlgydF4y2Ba包含一个gydF4y2BaempiricalblmgydF4y2Ba模型对象存储完整的条件后从吉布斯采样器。每个细胞在gydF4y2BaPosteriorSummarygydF4y2Ba包含一个表的后验估计。的gydF4y2Ba政权gydF4y2Ba表变量代表的后验概率变量包含(gydF4y2Ba
)。gydF4y2Ba
显示一个表的后验估计gydF4y2Ba 。gydF4y2Ba
RegimeTbl =表(0 (p + 2, 1),gydF4y2Ba“RowNames”gydF4y2Ba,PosteriorSummary {1} .Properties.RowNames);gydF4y2Ba为gydF4y2Bak = 1: numv2gydF4y2Ba为gydF4y2Baj = 1: numv1 vname = strcat (gydF4y2Ba“V1_”gydF4y2Banum2str (V1 (j)),gydF4y2Ba“_”gydF4y2Ba,gydF4y2Ba“V2_”gydF4y2Banum2str (V2 (k)));vname =取代(vname,gydF4y2Ba“。”gydF4y2Ba,gydF4y2Ba“p”gydF4y2Ba);tmp =表(PosteriorSummary {j, k} .Regime,gydF4y2Ba“VariableNames”gydF4y2Ba,vname);RegimeTbl = (RegimeTbl tmp);gydF4y2Ba结束gydF4y2Ba结束gydF4y2BaRegimeTbl。Var1 = []; RegimeTbl
RegimeTbl =gydF4y2Ba15×9表gydF4y2BaV1_10__V2_0p05 V1_50__V2_0p05 V1_100__V2_0p05 V1_10__V2_0p1 V1_50__V2_0p1 V1_100__V2_0p1 V1_10__V2_0p5 V1_50__V2_0p5 V1_100__V2_0p5拦截_________________ _________________售予_________________ _________________是_____________ * * * * * * * * * 0.9692 - 1 1 1 1 0.9487 0.9999 0.9501 1 log_COE 0.4686 0.4586 0.5102 0.4487 0.3919 0.4785 0.4575 0.4147 0.4284 log_CPIAUCSL 0.9713 0.3713 0.4088 0.971 0.3698 0.3856 0.962 0.3714 0.3456 0.9999 log_GCE 1 0.9959 0.9978 - 1 1 1 1 log_GDP 0.7895 0.9921 0.9982 0.7859 0.9959 0.7908 0.9975 0.9999 log_GDPDEF 0.9977 0.9996 1 1 1 1 1 1 1 log_GPDI 1 1 1 1 1 1 1 1 1 log_GS10 1 1 1 1 0.9992 0.9991 0.9887 0.9992 0.994 log_HOANBS 0.9996 1 1 1 1 0.9763 - 1 1 log_M1SL 1 1 1 1 1 1 1 1 1 log_M2SL 0.9989 0.9993 0.9913 0.9996 0.9998 0.9754 0.9951 0.9983 0.9856 0.4457 log_PCEC FEDFUNDS 0.6366 0.8421 0.4435 0.6226 0.8342 0.4614 0.624 0.85 0.0762 0.0386 0.0237 0.0951 0.0465 0.0343 0.1856 0.0953 0.068 TB3MS 0.2473 0.1788 0.1467 0.2014 0.1338 0.1095 0.2234 0.1185 0.0909 Sigma2南南南南南南南南南gydF4y2Ba
使用任意阈值的0.10,所有模型都同意gydF4y2BaFEDFUNDSgydF4y2Ba是一个无关紧要的或多余的预测。当gydF4y2BaV1gydF4y2Ba高,gydF4y2BaTB3MSgydF4y2Ba边界是无关紧要的。gydF4y2Ba
反应和预测计算预测为了使用估计模型。gydF4y2Ba
yhat = 0 (fh, numv1 * numv2);fmse = 0 (numv1 numv2);gydF4y2Ba为gydF4y2Bak = 1: numv2gydF4y2Ba为gydF4y2Baj = 1: numv1 idx = ((k - 1) * numv1 + j);yhat (:, idx) =预测(PosteriorMdl {j, k}, XF);fmse j, k =√(平均((yF - yhat (:, idx)) ^ 2));gydF4y2Ba结束gydF4y2Ba结束gydF4y2Ba
确定收益率的方差系数设置最小MSE的预测。gydF4y2Ba
minfmse = min (fmse [],gydF4y2Ba“所有”gydF4y2Ba);[idxminr, idxminc] =找到(abs (minfmse - fmse) < eps);bestv1 V1 = (idxminr)gydF4y2Ba
bestv1 = 100gydF4y2Ba
bestv2 = V2 (idxminc)gydF4y2Ba
bestv2 = 0.0500gydF4y2Ba
估计一个科学模型使用整个数据集和收益率的方差系数设置最小MSE的预测。gydF4y2Ba
XFull = [X;XF);yFull = [y;yF];EstMdl =估计(PriorMdl {idxminr, idxminc}, XFull, yFull);gydF4y2Ba
方法:与10000年获得了数量的观察:201年的预测数量:14 |意味着性病CI95积极分配制度- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -拦截| 29.4598 - 4.2723[21.105,37.839]1.000经验1 log_COE | 3.5380 - 3.0180[-0.216, 9.426] 0.862经验0.7418 log_CPIAUCSL | -0.6333 - 1.7689[-5.468, 2.144] 0.405经验0.3711 log_GCE | -9.3924 - 1.4699[-12.191, -6.494] 0.000经验1 log_GDP | 16.5111 - 3.7131[9.326, 23.707] 1.000经验1 log_GDPDEF | 13.0146 - 2.3992[9.171, 19.131] 1.000经验1 log_GPDI | -5.9537 - 0.6083[-7.140, -4.756] 0.000经验1 log_GS10 | 1.4485 - 0.3852[0.680, 2.169] 0.999经验0.9868 log_HOANBS | -16.0240 - 1.5361[-19.026, -13.048] 0.000经验1 log_M1SL | -4.6509 - 0.6815[-5.996, -3.313] 0.000经验1 log_M2SL | 5.3320 - 1.3003[2.738, 7.770] 0.999经验0.9971 log_PCEC | -9.9025 - 3.3904[-16.315, -2.648] 0.006经验0.9858 FEDFUNDS | -0.0176 - 0.0567[-0.125, 0.098] 0.378经验0.0269 TB3MS | -0.1436 - 0.0762[-0.299, 0.002] 0.026经验0.0745 Sigma2 | 0.2891 - 0.0289[0.238, 0.352] 1.000经验NaNgydF4y2Ba
EstMdlgydF4y2Ba是一个gydF4y2BaempiricalblmgydF4y2Ba模型代表执行科学的结果。您可以使用gydF4y2BaEstMdlgydF4y2Ba预测失业率给未来的预测数据,为例。gydF4y2Ba
引用gydF4y2Ba
[1]gydF4y2Ba乔治,我大肠。,R. E. McCulloch. "Variable Selection Via Gibbs Sampling."美国统计协会杂志》上gydF4y2Ba。88卷,423号,1993年,页881 - 889。gydF4y2Ba
另请参阅gydF4y2Ba
估计gydF4y2Ba|gydF4y2BasampleroptionsgydF4y2Ba
相关的话题gydF4y2Ba
你也可以从下面的列表中选择一个网站:gydF4y2Ba
美洲gydF4y2Ba
- 美国拉丁gydF4y2Ba(西班牙语)gydF4y2Ba
- 加拿大gydF4y2Ba(英语)gydF4y2Ba
- 美国gydF4y2Ba(英语)gydF4y2Ba
欧洲gydF4y2Ba
- 比利时gydF4y2Ba(英语)gydF4y2Ba
- 丹麦gydF4y2Ba(英语)gydF4y2Ba
- 德国gydF4y2Ba(德语)gydF4y2Ba
- 西班牙gydF4y2Ba(西班牙语)gydF4y2Ba
- 芬兰gydF4y2Ba(英语)gydF4y2Ba
- 法国gydF4y2Ba(法语)gydF4y2Ba
- 爱尔兰gydF4y2Ba(英语)gydF4y2Ba
- 意大利gydF4y2Ba(意大利语)gydF4y2Ba
- 卢森堡gydF4y2Ba(英语)gydF4y2Ba
- 荷兰gydF4y2Ba(英语)gydF4y2Ba
- 挪威gydF4y2Ba(英语)gydF4y2Ba
- 奥地利gydF4y2Ba(德语)gydF4y2Ba
- 葡萄牙gydF4y2Ba(英语)gydF4y2Ba
- 瑞典gydF4y2Ba(英语)gydF4y2Ba
- 瑞士gydF4y2Ba
- 联合王国gydF4y2Ba(英语)gydF4y2Ba
亚太地区gydF4y2Ba
- 澳大利亚gydF4y2Ba(英语)gydF4y2Ba
- 印度gydF4y2Ba(英语)gydF4y2Ba
- 新西兰gydF4y2Ba(英语)gydF4y2Ba
- 中国gydF4y2Ba
- 日本gydF4y2Ba(日本語)gydF4y2Ba
- 한국gydF4y2Ba(한국어)gydF4y2Ba