mixsemiconjugateblm
带半共轭先验的随机搜索变量选择贝叶斯线性回归模型
描述
一般来说,当您创建一个贝叶斯线性回归模型对象时,它只指定了线性回归模型的联合先验分布和特征。也就是说,模型对象是用于进一步使用的模板。具体来说,为了将数据合并到模型中进行后验分布分析和特征选择,将模型对象和数据传递给适当的对象目标函数。
创建
语法
描述
属性
对象的功能
例子
为SSVS创建先验模型
考虑预测美国实际国民生产总值(gdp)的多元线性回归模型(GNPR)采用工业生产指数(新闻学会)、总就业人数(E)和实际工资(或者说是)。
对所有 , 是一系列均值为0,方差为0的独立高斯扰动吗 。
假设这些先验分布 = 0,…,3:
,在那里 和 是独立的标准正态随机变量。因此,系数具有高斯混合分布。假设所有系数都是条件独立的。
。 和 分别是逆伽马分布的形状和比例。
它表示具有离散均匀分布的随机变量-包含状态变量。
为SSVS创建一个先验模型。指定预测器的数量p。
P = 3;PriorMdl = mixsemijugateblm (p);
PriorMdl是一个mixsemiconjugateblm贝叶斯线性回归模型对象表示回归系数和扰动方差的先验分布。mixsemiconjugateblm在命令行上显示先前分布的摘要。
或者,您可以通过传递预测器的数量来为SSVS创建一个先验模型bayeslm和设置ModelType到的名称-值对参数“mixsemiconjugate”。
MdlBayesLM = bayeslm(p,“ModelType”,“mixsemiconjugate”)
MdlBayesLM = mix半导体jugateblm与属性:NumPredictors: 3拦截:1 VarNames: {4x1 cell} Mu: [4x2 double] V: [4x2 double]概率:[4x1 double]相关性:[4x4 double] A: 3 B:1 |意味着性病CI95积极的分布 ------------------------------------------------------------------------------ 拦截| 0 2.2472[-5.201,5.201]0.500混合分布β(1)| 0 2.2472[-5.201,5.201]0.500混合分布β(2)| 0 2.2472[-5.201,5.201]0.500混合分布β(3)| 0 2.2472[-5.201,5.201]0.500混合分布Sigma2 | 0.5000 - 0.5000[0.138, 1.616] 1.000搞笑(3.00,1)
Mdl和MdlBayesLM是等价的模型对象。
您可以使用点表示法设置已创建模型的可写属性值。将回归系数名称设置为相应的变量名称。
PriorMdl。VarNames=[“他们”“E”“福”]
PriorMdl = mixsemijugateblm with properties: NumPredictors: 3拦截:1 VarNames: {4x1 cell} Mu: [4x2 double] V: [4x2 double]概率:[4x1 double]相关性:[4x4 double] A: 3 B:1 |意味着性病CI95积极的分布 ------------------------------------------------------------------------------ 拦截| 0 2.2472[-5.201,5.201]0.500混合分布IPI | 0 2.2472[-5.201, 5.201] 0.500混合分布E | 0 2.2472[-5.201, 5.201] 0.500混合分布WR | 0 2.2472[-5.201, 5.201] 0.500混合分布Sigma2 | 0.5000 - 0.5000[0.138, 1.616] 1.000搞笑(3.00,1)
MATLAB®将变量名称与显示中的回归系数关联起来。
绘制先验分布。
情节(PriorMdl);
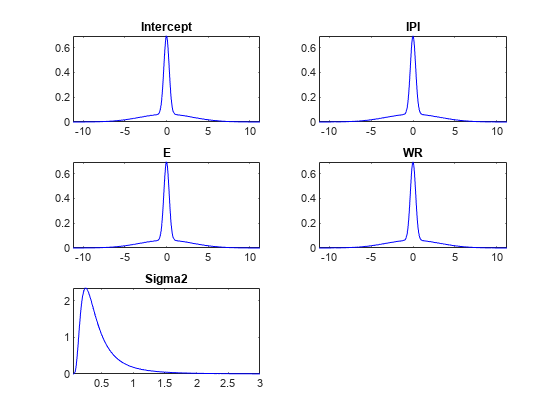
每个系数的先验分布是两个高斯的混合:两个分量的均值都为零,但分量1相对于分量2的方差较大。因此,它们的分布以0为中心,并且具有spike-and-slab外观。
使用SSVS和默认选项执行变量选择
中的线性回归模型为SSVS创建先验模型。
为执行SSVS创建一个先验模型。假设
和
是独立的(半共轭混合物模型)。指定预测器的数量p回归系数的名称。
P = 3;PriorMdl = mixsemijugateblm (p,“VarNames”, (“他们”“E”“福”]);
显示先验区域概率和先验的高斯混合方差因子 。
priorprobability = table(PriorMdl。概率,“RowNames”, PriorMdl。VarNames,...“VariableNames”,“概率”)
priorProbabilities =4×1表概率___________截距0.5 IPI 0.5 E 0.5 WR 0.5
priorV = array2table(PriorMdl。V,“RowNames”, PriorMdl。VarNames,...“VariableNames”, (“gammaIs1”“gammaIs0”])
priorV =4×2表gammaIs1 gammaIs0 ________ ________截取10 0.1 IPI 10 0.1 E 10 0.1 WR 10 0.1
PriorMdl存储先验状态概率概率属性和政体中的方差因素V财产。变量包含的默认先验概率为0.5。对于变量包含体系,每个系数的默认方差因子为10,对于变量排除体系,默认方差因子为0.01。
加载Nelson-Plosser数据集。为响应和预测器系列创建变量。
负载Data_NelsonPlosserX = DataTable{:, priormll . varnames (2:end)};y = DataTable{:,“GNPR”};
的边际后验分布来实现SSVS 和 。因为SSVS使用马尔科夫链蒙特卡罗(MCMC)进行估计,所以设置一个随机数种子来再现结果。
rng (1);PosteriorMdl =估计(PriorMdl,X,y);
方法:MCMC抽样10000张,观察数:624 |意味着性病CI95积极的分配制度 ------------------------------------------------------------------------------- 拦截| -1.5629 - 2.6816[-7.879,2.703]0.300经验0.5901 IPI | 4.6217 - 0.1222[4.384, 4.865] 1.000经验1 E | 0.0004 - 0.0002[0.000, 0.001] 0.976经验0.0918 WR | 2.6098 - 0.3691[1.889, 3.347] 1.000经验1 Sigma2 | 50.9169 - 9.4955[35.838, 72.707] 1.000经验NaN
PosteriorMdl是一个empiricalblm的后验分布绘制的模型对象
和
根据这些数据。估计在命令行上显示边缘后验分布的摘要。摘要的行对应回归系数和扰动方差,列对应后验分布的特征。其特点包括:
CI95,其中包含参数的95%贝叶斯相等可信区间。例如,后验概率的回归系数E是在[0.000, 0.001]是0.95。政权,其中包含变量包含的边际后验概率( 对于一个变量)。例如,后验概率E应该包含的型号是0.0918。
假设变量政权< 0.1应该从模型中去除,结果表明可以将失业率从模型中排除。
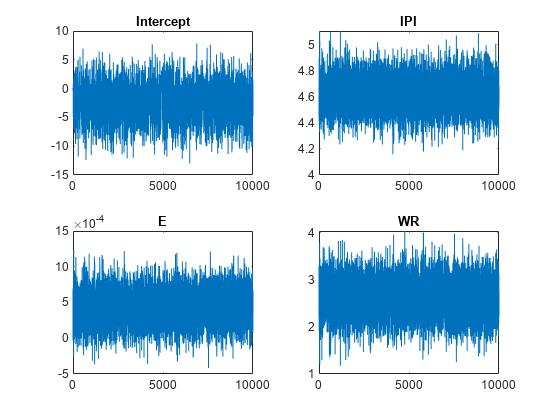
默认情况下,估计绘制并丢弃大小为5000的老化样本。然而,一个好的做法是检查图纸的痕迹图,以充分混合和缺乏瞬态。绘制每个参数的绘图跟踪图。您可以访问组成分布的绘图(属性)BetaDraws和Sigma2Draws)使用点表示法。
图;为J = 1:(p + 1) subplot(2,2, J);情节(PosteriorMdl.BetaDraws (j,:));标题(sprintf (' % s ', PosteriorMdl.VarNames {j}));结束
图;情节(PosteriorMdl.Sigma2Draws);标题(“Sigma2”);
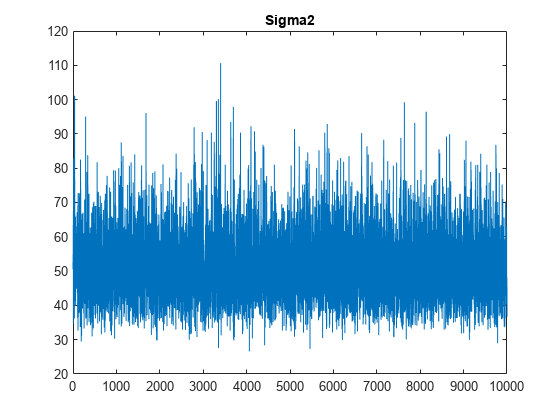
轨迹图表明,这些图似乎混合得很好。这些图没有显示出可检测的短暂性或序列相关性,并且在状态之间不跳跃。
为SSVS指定自定义先验制度概率分布
中的线性回归模型为SSVS创建先验模型。
加载Nelson-Plosser数据集。为响应和预测器系列创建变量。将特定于示例的文件添加到MATLAB®路径。
负载Data_NelsonPlosserVarNames = [“他们”“E”“福”];X = DataTable{:,VarNames};y = DataTable{:,“GNPR”};Path = fullfile(matlabroot,“例子”,“经济学”,“主要”);目录路径);
假设:
截距在模型中,概率为0.9。
新闻学会和E在模型中的概率是0.75。如果
E是包含在模型中的,那么概率是或者说是包含在模型中的是0.9。如果
E被排除在模型之外,那么概率是或者说是包含的是0.25。
声明一个名为priorssvsexample.m:
接受一个逻辑向量,指示截距和变量是否在模型中(
真正的对于模型包含)。元素1对应于截距,其余元素对应于数据中的变量。返回一个数字标量,表示所描述的先验区域概率分布的对数。
函数Logprior = priorssvsexample(varinc)PRIORSSVSEXAMPLE记录ssv的先验状态概率分布% PRIORSSVSEXAMPLE是一个自定义日志先验区域概率的例子具有依赖随机变量的SSVS的%分布。varinc是%一个4乘1的逻辑向量,表示模型中是否有4个系数%和logPrior是一个数字标量,表示优先级的对数区域概率的%分布。%%系数根据以下规则进入模型:% * varinc(1)的概率为0.9。% * varinc(2)和varinc(3)在模型中的概率为0.75。% *如果varinc(3)包含在模型中,则模型中varinc(4)的百分比为0.9。% *如果varinc(3)从模型中排除,则概率varinc(4)的百分比为0.25。logprior =日志(0.9)+ 2 *日志(0.75)+日志(varinc (3) * 0.9 + (1-varinc (3)) * 0.25);结束
priorssvsexample.m是计量经济学工具箱™中包含的特定于示例的文件。要访问它,请输入编辑priorssvsexample.m在命令行。
为执行SSVS创建一个先验模型。假设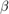 和
和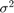 是独立的(半共轭混合物模型)。指定预测器的数量
是独立的(半共轭混合物模型)。指定预测器的数量p回归系数的名称,自定义,变量包含制度的先验概率分布。
P = 3;PriorMdl = mixsemijugateblm (p,“VarNames”, (“他们”“E”“福”],...“概率”, @priorssvsexample);
的边际后验分布来实现SSVS和。因为SSVS使用MCMC进行估计,所以设置一个随机数种子来再现结果。
rng (1);PosteriorMdl =估计(PriorMdl,X,y);
方法:MCMC抽样10000张,观察数:624 |意味着性病CI95积极的分配制度 ------------------------------------------------------------------------------- 拦截| -1.4658 - 2.6046[-7.781,2.546]0.308经验0.5516 IPI | 4.6227 - 0.1222[4.385, 4.866] 1.000经验1 E | 0.0004 - 0.0002[0.000, 0.001] 0.976经验0.2557 WR | 2.6105 - 0.3692[1.886, 3.346] 1.000经验1 Sigma2 | 50.9621 - 9.4999[35.860, 72.596] 1.000经验NaN
假设,变量与政权< 0.1应该从模型中移除,结果表明可以将所有变量都包含在模型中。
因为这个例子要求路径要访问特定于示例的文件,请通过删除进行清理路径从MATLAB®路径。
rmpath(路径);
使用后验预测分布预测响应
中的回归模型为SSVS创建先验模型。
执行科学价值:
为SSVS创建一个贝叶斯回归模型,该模型具有数据似然的半估计先验。使用默认设置。
列出最后10期估计数据。
估计边际后验分布。
P = 3;PriorMdl = bayeslm(p,“ModelType”,“mixsemiconjugate”,“VarNames”, (“他们”“E”“福”]);负载Data_NelsonPlosserFHS = 10;%预测视界大小X = DataTable{1:(end - fhs), priormll . varnames (2:end)};y = DataTable{1:(end - fhs),“GNPR”};XF = DataTable{(end - fhs + 1):end, priormll . varnames (2:end)};%未来预测数据yFT = DataTable{(end - fhs + 1):end,“GNPR”};%真实的未来反应rng (1);%用于再现性PosteriorMdl =估计(PriorMdl,X,y,“显示”、假);
使用后验预测分布和未来预测数据预测反应XF。画出响应的真实值和预测值。
yF = forecast(PosteriorMdl,XF);图;情节(日期、DataTable.GNPR);持有在plot(date ((end - fhs + 1):end),yF) h = gca;HP = patch([dates(end - FHS + 1) dates(end) dates(end) dates(end - FHS + 1)],...h.YLim([1,1,2,2]),[0.8 0.8 0.8]);uistack(惠普、“底”);传奇(“预测地平线”,“真正的GNPR”,“预测GNPR”,“位置”,“西北”)标题(实际国民生产总值:1909 - 1970);ylabel (“rGNP”);包含(“年”);持有从

yF是与未来预测数据相对应的真实GNP的未来值的10乘1向量。
估计预测均方根误差(RMSE)。
frmse =√(mean((yF - yFT).^2))
Frmse = 4.5935
预测均方根误差是预测精度的相对度量。具体来说,您使用不同的假设来估计几个模型。预测RMSE最低的模型是所比较的模型中表现最好的模型。
当您使用SSVS执行贝叶斯回归时,最佳实践是调优超参数。一种方法是在超参数值的网格上估计预测RMSE,并选择使预测RMSE最小化的值。
版权所有2018 The MathWorks, Inc.
更多关于
选择功能
的bayeslm函数可以为贝叶斯线性回归创建任何支持的先验模型对万博1manbetx象。
参考文献
[1]乔治,e。I。和r。e。麦卡洛克。"通过吉布斯抽样的变量选择"美国统计协会杂志。第88卷,第423号,1993年,第881-889页。
[2]库普,G. D. J.普瓦里尔,J. L.托比亚斯。贝叶斯计量经济学方法。纽约:剑桥大学出版社,2007年。
版本历史
您也可以从以下列表中选择一个网站: